Data Engineers are called the backbone of data science.
Running data algorithms and analytics, establishing standardized processes, and developing interfaces for the flow and access of data is how businesses are scaled. But this won’t be possible without reliable, timely, and accurate data to start with and a talented data engineer who can get the most out of that time and effort-consuming process.
With data engineering jobs getting more competitive, data engineer interviews are becoming one of the hardest to crack. There’s so much you should know about, from general and technical questions to behavioral and brainteasers. But don’t worry, the best way to get prepared is to simply revise the likely questions you’ll encounter at the job interview.
This article will help you navigate through the data engineer job interview landscape. It will list the most common data engineering interview questions you might encounter, tips that might be helpful and answers recruiters want to hear as follows:
- General questions and answers
- In-depth questions and answers
- Technical questions and answers
- Behavioral questions and answers
In the end, we’ll reveal 3 common mistakes you should avoid during your data engineer interview preparation. With that out of the way, let’s get straight to the point.
General Data Engineer interview questions & answers
Usually, recruiters start with a few more general questions. Their main goal is to take the edge off and prepare you for the more complex questions ahead. Here are a few of them that will help you get off to a flying start.
- What is Data Engineering?
Tip: Regardless of your skill level, this may come up during your interview. With this question, interviewers aim to assess whether you can discuss your field in an understandable, competent, and holistic way. When you answer, try to include your definition of data engineering and a general summary of how data engineers collaborate with the team.
Your answer: Data engineering is the act of collecting, transforming, cleansing, profiling, and processing large data sets through a combination of desktop software, mobile applications, cloud-based servers, and physical infrastructure. Effective data engineering requires strong pipeline management. Within a team, Data Engineers work closely with data scientists, who analyze and use the information we collect.
- Why did you choose a career in Data Engineering and why should we hire you?
Tip: Interviewers want to employ passionate people. They might ask this question to learn more about your motivation and interest in choosing a data engineering career path. Talk about your educational background a little and your work experience. Highlight your story and insights you’ve gained and share what excites you most about being a data specialist.
Your answer: From early childhood, I’ve been passionate about computers. When I finished high school, I already knew I wanted to get a degree in Information Systems. I took some math and statistics classes, developed my programming and data management skills, and took online courses to learn more about Data Engineering which helped me land my first job as a Data Engineer for a small fin-tech company. It was the ideal career path for me and my combination of interests, passions, and skills.
- What Data Engineer certifications have you earned?
Tip: The certifications you have under your belt prove to your future employer how dedicated you are to expanding your data engineering knowledge and skill set. However, if you don’t have them, you can mention the training provided by past employers. This will indicate that you’re up to the challenge to grab this opportunity.
Your answer: Right now, I’m preparing for the Google Cloud Professional Data Engineer certification and I attend Big Data conferences with recognized speakers. Last year, I earned a Cloudera Certification as a Data Engineer. In the meantime, I keep up-to-date with the latest trends, technologies, and training in the field.
- What is Big Data?
Tip: This is one of the basic questions asked in a data engineer interview. So, make sure you provide a brief description of what Big Data is and how it helps businesses.
Your answer: Big data is a collection of complex and large data sets from different sources. It helps companies understand their business and customers better and allows them to make greater decisions backed by data.
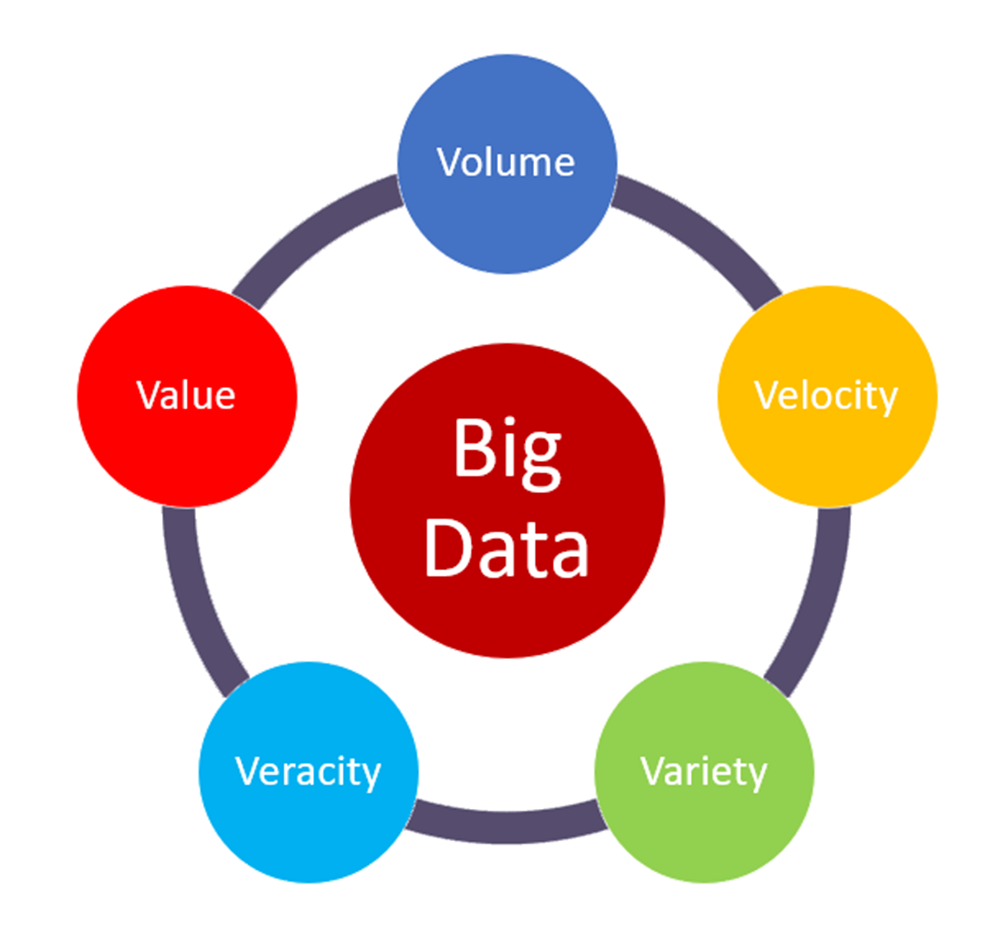
- What are the 5 V’s of Big Data?
Tip: The 5 V’s are the main characteristics of big data. Knowing them allows data engineers to derive more value from their data and be more customer-centric.
Your answer: Big data is described by five characteristics:
- Volume - the amount of data that is growing at a high rate, including the number of users, number of tables, size of data;
- Velocity - the rate at which data grows;
- Variety - the various data formats like log files, media files, and voice recordings;
- Veracity - the uncertainty of available data or the high volume of data that brings inconsistency;
- Value - turning data into value that subsequently may generate revenue for the business.
In-depth Data Engineer interview questions and answers
The following questions and answers will help you gain a comprehensive understanding of your competencies at work:
6. What are the daily responsibilities of a data engineer?
Tip: In your answer, specify the core skills and responsibilities that you think are essential for a data engineering professional.
Your answer: A proficient Data Engineer should have a good understanding of database design and architecture and the know-how to collaborate effectively with other departments. Data Engineers also need to know how to architect distributed systems and data stores, create pipelines and combine data sources. To accomplish all these tasks, a data engineer needs strong SQL and NoSQL skills, a good level of experience in Hadoop, and expertise in Data Warehousing and ETL tools.
7. What non-technical skills does a Data Engineer need to perform at the job?
Tip: Avoid the most obvious answers, such as interpersonal and communication skills.
Your answer: As data engineers, we work with different departments and get various tasks a day. To make our work easy, we have to prioritize the workload. Prioritizing and multitasking skills will come in handy in my data engineering role.
8. Which frameworks are essential for Data Engineers?
Tip: Hiring managers often ask this question to find out whether you have the essential skills required for the job. Be as specific as possible and list the names of frameworks and applications.
Your answer: Data engineers have to be proficient in SQL, AWS, Hadoop, and Python. I am fluent with all these frameworks, embracing every opportunity to learn new ones. I am also familiar with Hive, Apache Spark, and Tableau.
9. What are the steps to be followed to deploy a Big Data solution?
Tip: Big data solutions represent a significant challenge for some businesses. By answering this question, you’ll show that you can become a valuable asset to the data science team.
Your Answer: In brief, there are three main steps to be followed to deploy a Big Data solution:
- Data Ingestion - the extraction of data from various sources: CRM like Salesforce, Enterprise Resource Planning system like SAP, RDBMS, MySQL or any other log files, social media feeds, etc.
- Data Storage - the extracted data is then stored in HDFS or NoSQL database.
- Data Processing - the final step in deploying the big data solution. The data may be processed through one of the following frameworks: Spark, MapReduce, or Pig.
10. What is Data Modeling? Do you have experience with Data Modeling?
Tip: You will likely be asked this question if you are interviewed for an entry-level data engineering role. If you’re experienced with Data Modelling, you can go into detail about what tools you have used (for example Talend, Pentaho, or Informatica).
Your answer: Data modeling is the act of documenting complex data systems in the form of diagrams to give a conceptual representation of the system. It offers numerous benefits, such as the simplified representation of complex data objects and their rules. Data models serve as blueprints for creating a new database. I’ve previously used Informatica integration to deliver high-throughput data ingestion to help business analysts get the information they need quickly and effectively.
11. What are the various types of design schemas in Data Modeling?
Tip: Hiring professionals may ask you this question to test your knowledge of data engineering fundamentals. Do your best to explain the concept clearly and concisely.
Your answer: Data modeling employs two types of data schemas: star and snowflake. Star schema is divided into a fact table referenced by multiple dimension tables, which are linked to a fact table. In contrast, in the snowflake schema, the fact table remains the same, while the dimension tables are normalized into many layers looking like a snowflake.
12. How is the job of a Data Engineer different from that of a Data Architect?
Tip: This question will test your ability to determine that there are differences within the team of a data warehouse. To avoid going wrong with the answer, share some insights from your previous experience.
Your answer: Although we work closely together, our core responsibilities differ from company to company. Managing servers and building the architecture of the data system is the core responsibility of a data architect. Along with that, we, data engineers, make sure to test and maintain that architecture and provide high-quality and reliable data for the data analysts.
13. What’s the difference between a Data Engineer and Data Scientist?
Tip: With this question, hiring managers are trying to assess your understanding of different job roles within the data science team.
Your answer: We develop, test, and maintain the architecture of data generation, whereas data scientists focus on the organization and translation process of complex data. Simply speaking, data scientists require us to create the infrastructure for them to work.
14. How can data analytics help the business grow and boost revenue?
Tip: Hiring managers aim to land data engineers who understand how to help their data analysts contribute to business growth and revenue generation. You can answer this question by illustrating the key advantages of data engineering and analytics in boosting a company's revenue.
Your answer: Data analytics helps businesses to boost revenue, improve customer satisfaction, and increase profit. By implementing Big Data analytics, businesses can encounter an up to 20% increase in revenue. Airbnb, LinkedIn, and Cisco are some of the companies that use data analytics to grow their income.
15. What is the biggest challenge have you overcome as a Data Engineer?
Tip: Recruiters often ask this question to learn how you address difficulties at work. Some of them may include: constraints of resources, considering which tools to use to deliver better results, real-time integration, or storing huge amounts of data. When you answer, focus on the STAR method by stating the situation, task, action, and result.
Your answer: As a lead data engineer for a project, I had insufficient internal support. As a result, the project fell behind schedule. I took the decision to meet with the project manager and address all possible solutions. Based on my suggestion, the company assigned an additional workforce to my team and we were able to land the project successfully within the timeline.
Technical Data Engineer interview questions and answers
The technical data engineer questions and answers help the hiring manager assess two things: whether your qualifications are enough for the role; and if you’re experienced with the latest systems and programs. So here’s a list of tech-savvy data engineer questions and answers you can practice with:
16. What is the difference between a Data warehouse and an Operational database?
Tip: Entry-level and intermediate-level Data Engineers could come across this question in a job interview.
Your answer: Data warehouses focus on the calculation, aggregation, and selection statements, which makes them the best choice for data analysts. However, Operational databases focus more on efficiency and speed by using Insert, Update and Delete SQL statements, which makes data analysis more complex.
17. What is the meaning of *Args and **Kwargs?
Tip: This is a data engineering question that focuses on your knowledge of complex coding skills. You can go even further with your professional coding skills by writing this code down.
Your answer: *args and **kwargs are special keywords that allow the function to take the variable-length arguments. *args is an ordered function while **kwargs represent unordered arguments used in a function.
18. What are the essential frameworks and applications for Data Engineers?
Tip: With this question your assessor tests you to know if you’re eligible for the job. You can start listing the frameworks that match your level of expertise.
Your answer: SQL, Hadoop, Python, and CSS are the most essential frameworks and applications for a Data Engineering professional.
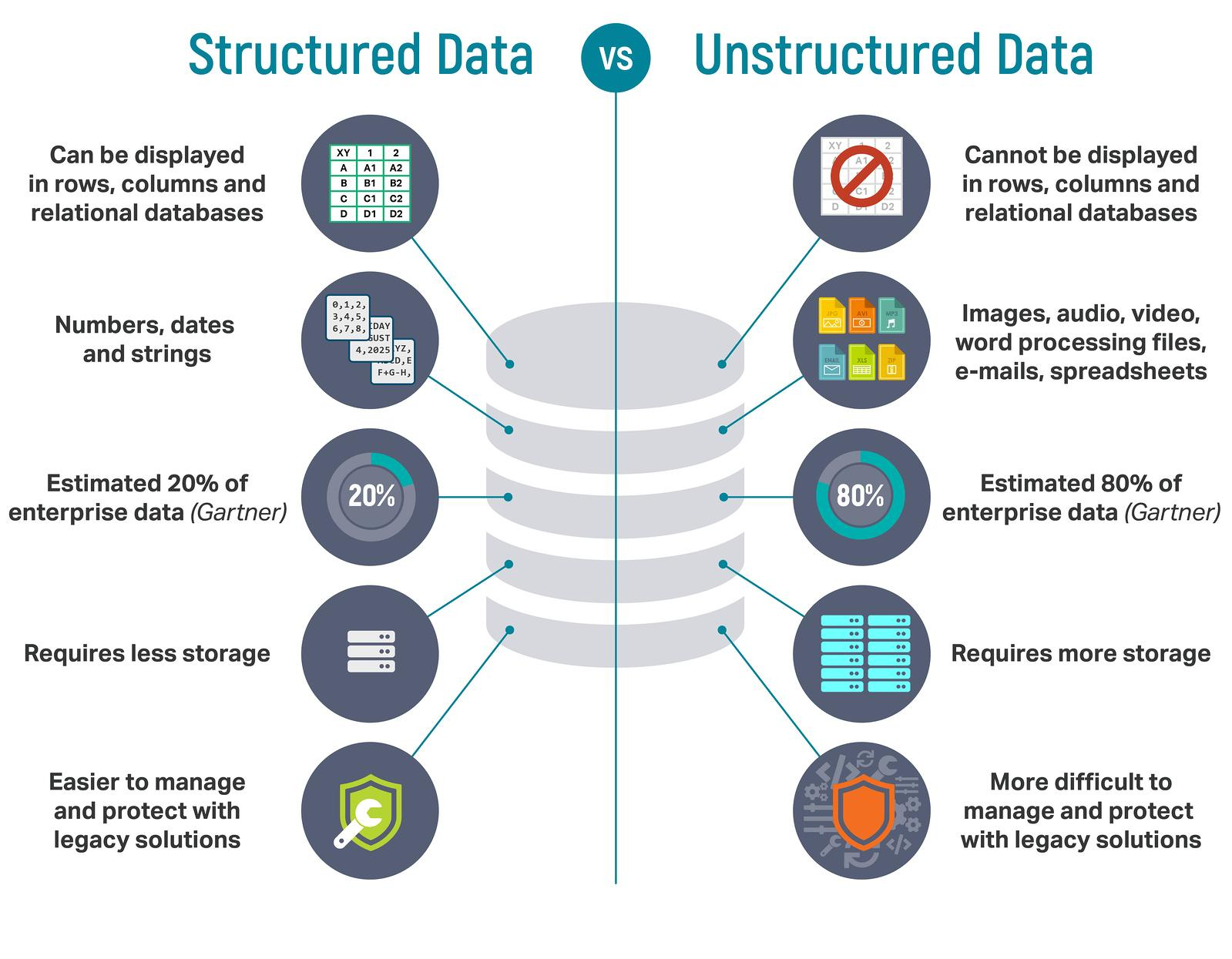
19. Have you ever transformed unstructured data into structured data?
Tip: It’s an important question as your answer demonstrates your grasp of both data types. You can answer this question by briefly distinguishing between both categories.
Your answer: Data Engineers work with data that is coming into the systems in all sorts of formats and broadly categorize them as structured and unstructured.
Here are the key differences in the following criteria:
- Storage: The structured data uses DBMS, whereas unstructured data uses unmanaged file structures.
- Integration tool: Structured data make use of ELT (Extract, Transform, Load), while unstructured data requires manual data entry or batch processing that includes codes.
- Scaling: In structured data schema scaling is difficult. On the contrary, unstructured data makes schema scaling easy.
20. What is Hadoop?
Tip: Many hiring managers ask about the Hadoop framework in the interview. You’ll likely be required to use this particular tool for the job. So, if you haven’t ever worked with it, do your homework and make sure you show some familiarity with its attributes. However, if you’re experienced with the tool, give a detailed explanation of the project you’ve previously worked on to highlight your skills.
Your answer: Hadoop is open-source software that allows you to use a network of multiple computers to solve big data problems. Its extensive collection of utilities and various components lets you process huge amounts of data and perform many powerful big data applications efficiently.
21. Have you ever worked with the Hadoop framework? If so, please describe a particular project you’ve worked on.
Your answer: Hadoop framework is an open-source network based on Java that can be used by everyone without any additional training, which makes it the best option for projects with limited resources. I’ve had the chance to work with the Hadoop framework on a team project focused on increasing data efficiency. We decided to use Hadoop due to its ability to increase the speed of data processing and preserve quality through its distributed processing. And as we expected to increase our data processing considerably, we also decided to implement it because of its scalability.
22. What are the core components of Hadoop?
Your answer: Hadoop is an open-source framework used for the storage and processing of big data sets in a distributed manner.
The main components of the Hadoop application are:
- HDFS (Hadoop Distributed File System) - HDFS is the main data storage system used by Hadoop. It can reliably store large data files even when hardware fails.
- Hadoop MapReduce - MapReduce is the Hadoop layer that aids writing applications that process a large number of data. It is responsible for processing unstructured and structured data stored in HDFS and also for the parallel processing of a high volume of data, dividing data into independent tasks.
- Yarn - Yarn aids resource management within the Hadoop cluster. It provides multiple data processing engines i.e. data science, real-time streaming, and batch processing.
- Hadoop Common - This is a basic set of tools and libraries that are used by Hadoop.
23. What are the components of HDFS & YARN?
Your answer:
The two main components of HDFS are:
- NameNode - a master node for processing metadata information from data blocks
- DataNode - a node that acts as a slave node to store the data, for processing and use
The two main components of YARN are:
- ResourceManager - It receives processing requests and allocates NodeManagers depending on the processing needs
- NodeManager - It executes tasks on each DataNode
24. What are the main features of the Hadoop framework?
Your answer: Hadoop supports the storage and processing of data, which makes it the best option for handling big data challenges. Some important features of Hadoop are:
- Open source: Hadoop is an open-source framework available for free.
- Distributed processing: Hadoop supports the faster-distributed processing of data and uses MapReduce to parallel process the data.
- Fault tolerance: Hadoop is highly fault-tolerant. It allows us to create three replicas of each block at different nodes, by default. This means we can recover the data from another note if one node fails. The detection of node failure and data recovery is done automatically.
- Reliability: Since Hadoop stores data in clusters, independent of all the other operations, the data stored in the Hadoop environment is not affected by the failure of the machine.
- Scalability: Hadoop is scalable and compatible with many hardware.
- High availability: The data stored in the Hadoop environment is available even after the hardware failure.
25. What are the three running modes of Hadoop?
Your answer: Apache Hadoop runs in the following three modes:
- Standalone or local: By default, Hadoop runs in a local mode and does not need any custom configuration. In this mode, all the following components of Hadoop use a local file system and run on a single JVM - NameNode, DataNote, ResourceManager, and NodeManager.
- Pseudo-distributed: In this mode, all the master and slave Hadoop services are deployed and executed in a single mode just like the Standalone mode.
- Fully distributed: In this mode, Hadoop master and slave services are deployed and executed on separate modes and, thus, form a multi-node cluster.
26. What are the core methods of Reducer in Hadoop MapReduce?
Your answer: The Reducer is the second stage of data processing in the Hadoop Framework. It processes the data output of the mapper and brings out the final output that is stored in HDFS.
The Reducer has three phases:
- Shuffle: The data output from the mappers is shuffled and acts as the input for Reducer;
- Sorting: This is done simultaneously with shuffling. The output from different mappers is organized and sorted.
- Reduce: In this phase, the Reduces aggregates the key-value pairs and provides the required output which is finally stored on HDFS and is not further sorted and processed.
27. What is Distributed Cache in a MapReduce framework?
Your answer: Distributed Cache is a feature of the Hadoop MapReduce framework. Its main purpose is to cache files for applications and make them available for every MapReduce task running on the data nodes.
28. What is a NameNode?
Your answer: A NameNode is one of the vital parts of HDFS that tracks the different files presented in clusters. NameNodes don’t store data. They store metadata of DataNodes.
29. How does the DataNode communicate with the NameNode?
Your answer: DataNodes send signals to NameNodes to inform them that they are working properly in two different ways:
- Blog report signals - a list of data blocks stored on DataNode’s functioning
- Heartbeat signals - a periodic report to establish whether DataNode is alive and functional. If DataNodes fails to send heartbeats, NameNodes determines that it has died and has stopped operating.
30. What if NameNode crashes in the HDFS cluster?
Your answer: The HDFS cluster has only one NameNode that maintains DataNode’s metadata. With one NameNode available, there is a single point of failure for HDFS clusters. So, if NameNode crashes, systems might become unavailable. To prevent that, we should specify a secondary NameNode that will take periodic checkpoints in HDFS file systems.
31. What is a Block Scanner? What happens when Block Scanner finds a corrupted block of data?
Your answer: Hadoop divides large data sets into small data blocks for ease of storage. A block is the smallest unit of data that can be written or read in HDFS, while a Block Scanner is a program that tracks and checks the number of blocks present on a DataNode for any possible checksum errors and data corruption.
When Block Scanner finds a corrupted block of data, DataNode reports it to NameNode. Then, the NameNode starts creating a replica of the corrupted block. If the system does not delete the corrupted data block, NameNode creates replicas as per the replication factor.
32. Which ETL tools have you worked with? Do you have a favorite one? If so, why?
Tip: With this question, hiring managers want to test your understanding and experience regarding the ETL (Extract, Transform, and Load) process and tools. Make sure to name all the ETL tools you’ve worked with and the ones you like working with.
Your answer: I have experience with various ETL tools, such as SAS Data Management, IBM Infosphere, and SAP Data Services. But my preferred one is Informatica’s PowerCenter. It is highly efficient and flexible and has an extremely top performance rate which, I believe, are the most important features of an ETL tool. They smoothly run business data operations and guarantee trouble-free data access at all times, even if changes in the business structure take place.
33. How would you describe SQL to someone who does not have a technical background?
Tip: In the world of a data engineer, SQL is way more than a query language. It’s a data processing pattern shared by many big data frameworks, including SparkSQL, pandas, and KafkaSQL. With this question, hiring managers will test your capabilities in translating complicated business requirements and questions into SQL queries. Your answer should contain a brief explanation of what SQL is and how it communicates with Databases.
Your answer: SQL stands for Structured Query Language and it is used to communicate with Databases (a database is nothing but an organized collection of data for easy access, storing, and managing of data). SQL is a standard language used to perform tasks such as retrieval, updation, insertion, and deletion of data from a database.
34. What is your experience level with NoSQL databases? Tell me about a situation where building a NoSQL database was a better solution than building a relational database.
Tip: To give the best possible answer, try to showcase your grasp of both types of databases and back it up with a situation that demonstrates your work capabilities in applying your know-how to a real project.
Your answer: In some situations, building a NoSQL database might be beneficial. In my previous company, when the franchise system was exponentially growing in size, we had to scale up quickly and get the most out of all operational and sales data we had.
Yes, relational databases indeed have better connectivity to various analytics tools. However, NoSQL databases have a lot to offer. With bigger servers and huge data processing load, scaling out is a better option than scaling up. It is cost-saving and easier to accomplish than with NoSQL databases as it can easily handle huge amounts of data. That comes in handy when you need to respond quickly to exponential data load shifts.
35. In what ways Python helps Data Engineers? Which Python libraries would you use for data processing?
Tip: This question helps the hiring manager evaluate whether you know the Python basics. Python is the most used programming language in data engineering.
Your answer: Data Engineers use Python to create the data pipelines, write the ETL scripts, set up statistical models, and perform data analysis. I use Pandas and NumPy for efficiently processing large arrays of numbers and pandas. I also used them for machine learning work, statistics, and data preparation.
36. What is a cloud and what is cloud computing?
Tip: More and more companies are moving their services to the cloud. Therefore, recruiters would like to assess your basic understanding of cloud computing, your cloud computing abilities, or knowledge of industry trends. The better way to answer this question is usually to give a brief explanation of the terms.
Your answer: A cloud is a system of networks, services, storage devices, hardware, and interface that work together to deliver computing services to the end-users, business management users, and cloud service providers. Cloud computing is an advanced way of using cloud services, as it offers users a way to access several worldwide servers from anywhere in the world.
37. What are the pros and cons of cloud computing?
Tip: Data engineers are well aware that there are ins and outs of using cloud computing. Even if you lack prior experience working in cloud computing, you must be able to state a certain level of understanding of its benefits, advantages, and drawbacks. This will show the recruiter that you’re aware of the latest technological issues in the industry.
Your answer: I haven’t had the opportunity to work in a cloud computing environment yet. However, I have a good understanding of its ins and outs. On the plus side, a cloud computing environment is easy to use, cost-effective and reliable, and requires minimum management. Additionally, it offers data control, backup, recovery, and huge storage capabilities. On the negative side, the cloud computing environment may compromise data security and privacy, as long as the data sets are kept outside the company. It requires a good and stable internet connection with equally good bandwidth to function well. Moreover, your control is limited, as the infrastructure is managed by the service provider. All in all, cloud computing could be both a right and wrong choice for a company, depending on its department structure and resources at hand.
Behavioral Data Engineer questions and answers
Behavioral or scenario-based data engineering interview questions and answers give the recruiters a chance to see how you’ve handled high-pressure data engineering issues and challenges in your experience. Here are some examples to consider in your preparation.
38. What is your approach to developing a new analytical product as a Data Engineer?
Tip: Recruiters may ask this question to know your role in developing a new product and evaluate your understanding of the product development cycle. Speak about what you are responsible for, including controlling the outcome of the final product and building algorithms and metrics with the correct data.
Your answer: At first, I would opt for understanding the outline of the entire product, so I can comprehend its requirements, specifications, and scope. The next step would be to look into the details and reasons for each metric and think about as many issues that could occur. This will help me create a more robust system.
39. Describe a time when you encountered an unexpected data maintenance problem that made you search for an out-of-the-box solution".
Tip: For a data engineer, data maintenance is a routine activity. However, inevitably, an unexpected issue arises every once in a while. As this might cause uncertainty in the workplace, the hiring manager would like to know how you would deal with such high-pressure situations.
Your answer: Even if data maintenance may come off as routine, it’s always a good idea to push the mile and closely monitor the specified tasks. And that includes making sure the scripts are well executed. Once, during an integrity check, I located a corrupt index that could have caused some serious issues in the future. This prompted me to create a new maintenance task that will help prevent corrupt indexes from being added to the company’s databases.
40. Have you ever proposed changes that improved data reliability and quality?
Tip: One of the things recruiters value most is your ability to initiate improvements to existing processes, even if you were not assigned to do it. If you have such experience, point it out. This will showcase your ability to think outside the box. If you lack such experience, explain what changes you would propose as a data engineer.
Your answer: Data quality and reliability are a top priority in my work. While working for my previous employer, I discovered some data storage issues in the company’s database. I proposed to develop a data quality process that has been implemented soon in my department’s routine. This included meetups with co-workers from different departments where we would troubleshoot data issues. At first, everyone was worried that it would take too much time and effort. But in time, it turned out to be a great solution, as the new processes prevented the occurrence of more costly issues in the future.
41. Data engineers work “backstage”. Do you feel comfortable with that or do you prefer to hit the “spotlight”?
Tip: The reason why data engineers work “backstage” is to make data available. So, the best way to answer this question is to tell hiring managers that what matters is your expertise in the field.
Your answer: As a data engineer, I’m ok with doing most of my work away from the spotlight. Hitting the spotlight has never been that essential to me. I believe what truly matters is my expertise in the field and how it helps the company reach its goals. However, I’m comfortable being in the spotlight. For example, if there’s a problem in my department that needs to be addressed by the executives, I won’t hesitate to bring their attention to it. This way, I can improve teamwork and reach better results for the business.
42. Do you have experience as a trainer in data engineering software, processes or architecture?
Tip: Data engineers may often be required to train teammates on the existing pipelines and architectures or on the new processes and systems that have been implemented. Make sure to mention the challenges you’ve faced while you’ve provided training and let the interviewer know how you’ve handled it.
Your answer: I’m experienced with training both small and large groups of co-workers. The most challenging part in this regard is to train new teammates who worked for many years in another company. Usually, they’re used to handling data from an entirely different perspective and struggle to accept and learn new things and ways of working. However, what usually helps is emphasizing new ways to open their minds to the alternative possibilities out there.
3 common mistakes to avoid in your data engineer interview preparation
Sometimes a single detail can cost you your success. So, here are the three most common mistakes you should avoid in your data engineering interview preparation.
- Skipping behavioral interview questions
Covering your technical part is not enough. Behavioural or scenario-based questions are becoming increasingly important, as they tell the hiring manager more about how you handle difficult situations at the workplace. So, to ace your interview preparation, get familiar with the common behavioral data engineer interview questions and answers we’ve listed above and rehearse some of your past experiences.
- Not practicing the mock interview
Don’t forget to call a fellow data engineer and ask them to do a mock interview with you. Doing a mock interview will help you pay special attention to your body language, tone of voice, and pace of your speech. You’ll be amazed by the insights you’re going to gain.
- Getting discouraged
There’s one more thing you should know about data engineer interviews: no matter how difficult they seem, don’t give up. Stay calm and confident. Don’t hesitate to ask for additional information. This will prove that you’re not afraid of challenges and you’re willing to collaborate to find the best solution.
Concluding lines
Now that you're familiar with the most essential data engineer interview questions and answers and with the interview process itself, you should be more confident in grabbing the data engineer role.
However, if you feel that you lack some of the skills required for the job, check our guide on what qualifications companies look for in a data engineer. If you are eager to explore more hiring opportunities, feel free to reach out to the Index platform.
All the best!
