Open-source large language models are gaining serious traction, and China is quickly becoming a key contributor in this space. In the first half of 2026, several powerful Chinese LLMs have shipped major updates, offering flexible, high-performance alternatives that are free to use, adapt, and deploy.
What makes this trend especially interesting is how these models are not just focused on scale. They are optimized for reasoning, efficiency, and real-world applications. From handling million-token documents to powering autonomous AI agents with tool-calling support, these open-source models are designed to compete at the highest level while remaining accessible to developers, researchers, and businesses.
In this article, we take a closer look at five standout open-source Chinese LLMs that are shaping the future of AI, each with its own approach to architecture, inference, and deployment.
Build with the best. Join Index.dev to work on AI-first engineering projects with the top 1% of human-vetted senior engineers from LATAM and CEE. 30,000+ engineers, matched in 48 hours.
5 Key Takeaways
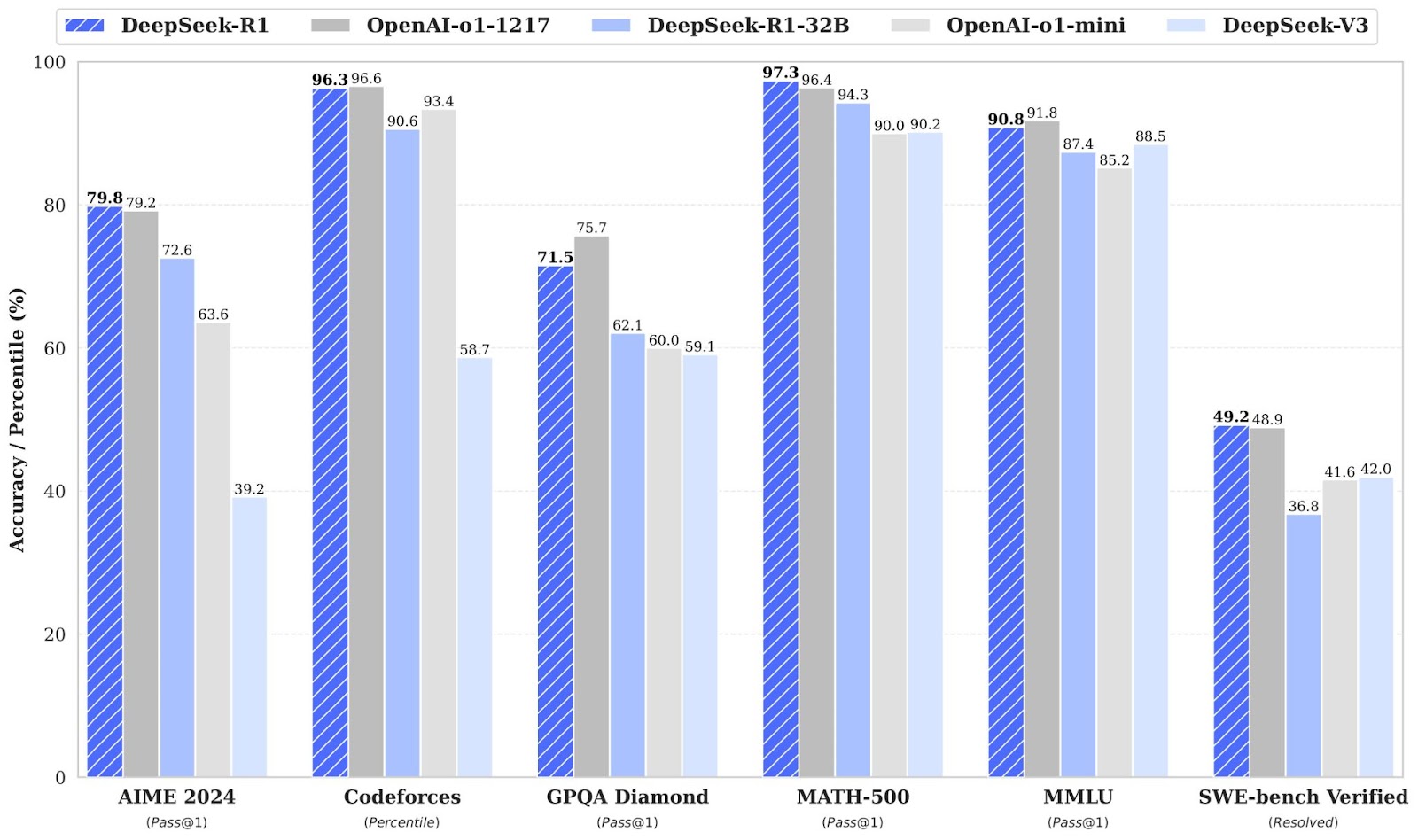
- DeepSeek-R1 scores 97.3% on MATH-500 and was trained for under $6 million using 2,000 H800 chips in 55 days, making it the most cost-efficient reasoning model in the group.
- Kimi k1.5 scored 77.5 on AIME (vs. GPT-4o's 9.3), proving that Chinese open-source models now outperform leading proprietary models on competition-level math benchmarks.
- Qwen3 supports 119 languages and MCP tool-calling, making it the most versatile model for building autonomous AI agents that interact with external systems.
- ChatGLM supports up to 1M tokens with INT4 quantization on 6 GB GPUs, offering the widest context window and the lowest deployment barrier of the five.
- All five models ship under open licenses (MIT, Apache 2.0, or equivalent), giving teams full freedom to fine-tune, deploy commercially, and adapt without vendor lock-in. Per Hugging Face 2025 data, Chinese open-source LLM downloads grew 340% year-over-year.
Overview of 5 Key Chinese Open-Source Language Models
1. DeepSeek-R1
DeepSeek-R1 is a high-performance, open-source large language model developed by the Chinese AI company DeepSeek under High-Flyer. Released in January 2025, it is optimized for advanced reasoning, math problem-solving, and technical content generation, offering a strong alternative to models like GPT-4 and o1.
Built with a Mixture-of-Experts (MoE) architecture, DeepSeek-R1 contains 671 billion parameters but activates only 37 billion at a time, enabling efficient performance with lower hardware costs. It supports long-context inputs up to 128,000 tokens, making it ideal for document analysis and multi-step tasks.
Trained using reinforcement learning and supervised fine-tuning, the model produces clear, logical outputs. It is fully open-source under the MIT license, allowing researchers and businesses to fine-tune, deploy, and adapt it freely across use cases.
Key Features of DeepSeek-R1
Mixture-of-Experts (MoE) Architecture
DeepSeek-R1 uses a 671 billion parameter MoE model, but activates only 37 billion parameters per query. This approach reduces computational demands without sacrificing performance, allowing faster and more efficient inference.
Here is an example of how DeepSeek deep thinking works:
In this mode, users can view step-by-step logical breakdowns of how the model arrives at an answer. This transparency is especially useful in math, science, and finance-related tasks where traceability matters.
Multi-Head Latent Attention (MLA)
MLA improves upon traditional attention mechanisms by optimizing how token relationships are handled in long sequences. This enhancement helps the model manage complex queries with greater accuracy.
Native Sparse Attention (NSA)
NSA introduces a hierarchical sparse attention mechanism that improves performance on long-context tasks. By compressing and selectively attending to tokens, the model efficiently processes up to 128,000 tokens in a single input.
Multi-Token Prediction (MTP)
DeepSeek-R1 predicts multiple tokens at once rather than one at a time. This significantly increases output speed, making it ideal for real-time applications and large-scale deployments.
Cost-Effective Development
DeepSeek trained the R1 model in 55 days using just 2,000 NVIDIA H800 chips, spending under $6 million. This cost-efficiency contrasts sharply with models like GPT-4, which required over $100 million in development costs.
Reasoning-First Training Approach
Unlike general-purpose LLMs, DeepSeek-R1 emphasizes logical reasoning and mathematical problem-solving. It scores 97.3% on the MATH-500 benchmark and 79.8% on AIME 2024, outperforming many competitors in structured reasoning tasks.
Open-Source Licensing
DeepSeek releases its models under the MIT license, enabling developers and researchers to download, adapt, and fine-tune the models without restrictive commercial terms. This openness encourages global collaboration and rapid innovation.
Platform Flexibility
Users can access DeepSeek through a web platform, API, or mobile applications. The DeepThink mode within its chat interface allows users to view step-by-step reasoning processes, enhancing model transparency and explainability.
Distilled Model Variants
DeepSeek offers smaller, distilled versions of R1 using Qwen and LLaMA architectures. These variants maintain high performance on tasks like math and factual Q&A while reducing resource requirements for deployment.
Scalable Infrastructure Design
DeepSeek's models use the HAI-LLM framework for optimized training. Features such as pipeline parallelism, expert parallelism, FP8 mixed-precision training, and zero-bubble latency contribute to faster inference and lower hardware overhead.
Read More: DeepSeek vs. ChatGPT (2026 Edition)
2. Kimi k1.5
Kimi, developed by Moonshot AI, is a multimodal chatbot capable of interpreting text, images, and code, unlike conventional chatbots limited to basic text processing.
Kimi supports diverse tasks including conversational interaction, problem-solving, code generation, and image interpretation. It is suitable for students, developers, and business professionals who require multimodal AI support. Users can access Kimi via web, mobile, or integrate it into custom applications through an API.
Key Features of Kimi k1.5
Multimodal Understanding

Kimi k1.5 interprets text, images, and programming code, enabling diverse multimodal tasks. This capability enables image description, caption generation, and debugging or writing code, all within a single interface. Its flexibility supports diverse use cases across education, business, and development.
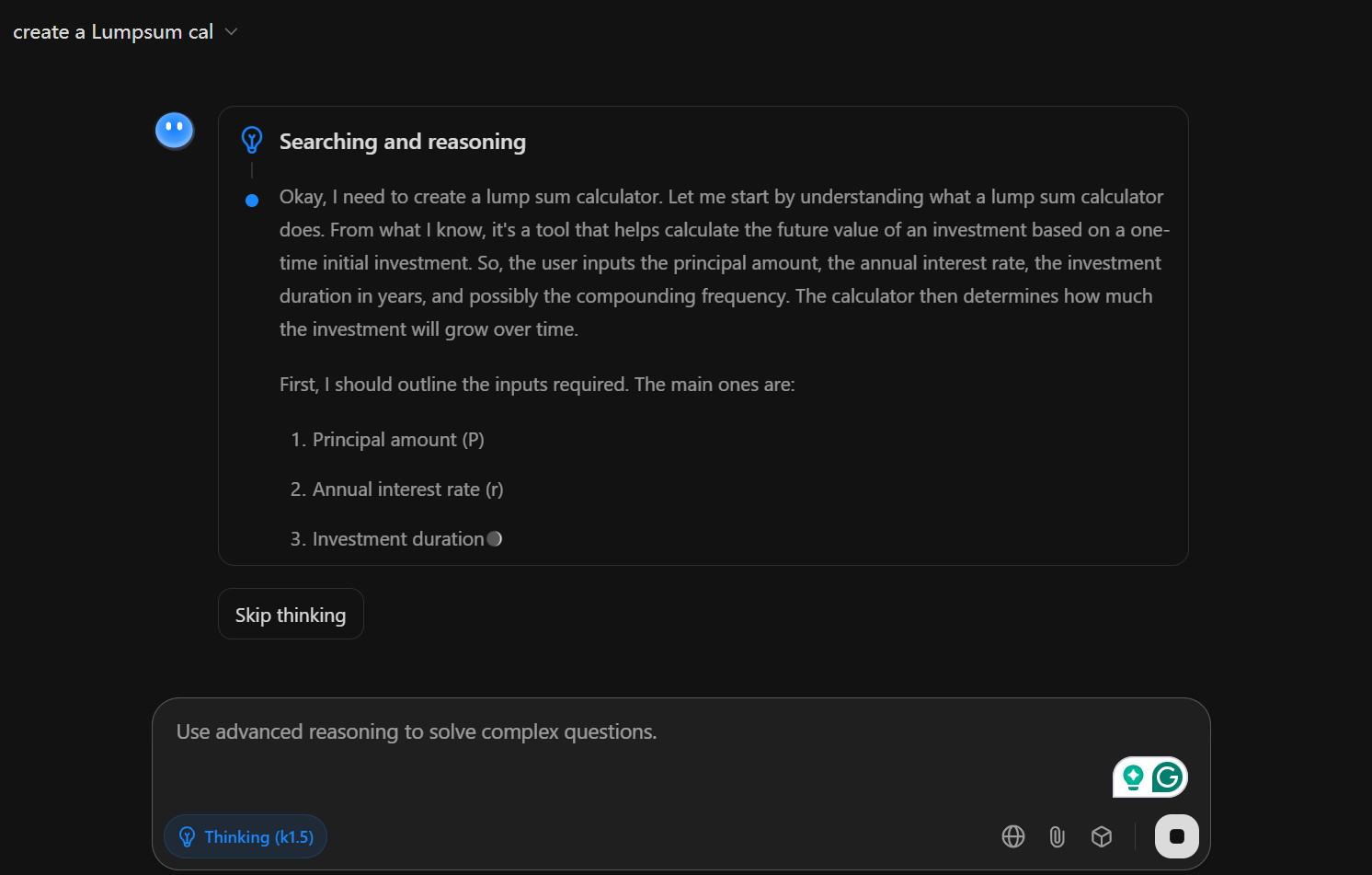
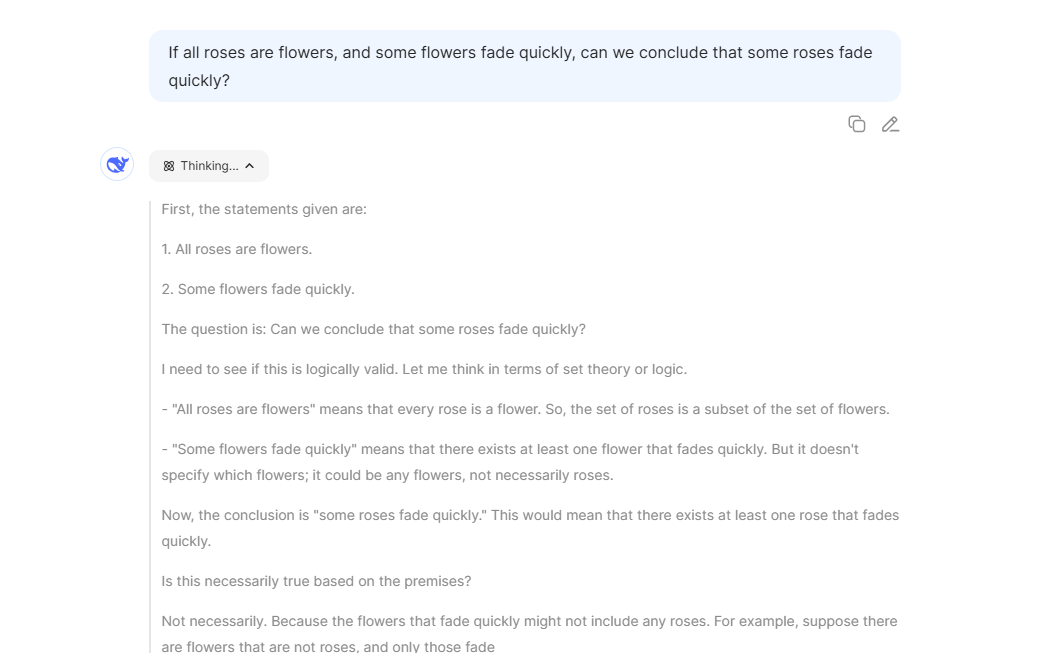
Advanced Reasoning Using Chain-of-Thought (CoT)
Kimi does not just give quick answers. It explains its thinking process. It breaks down big problems into smaller steps, making its solutions more accurate and understandable. This step-by-step style works well in math, logic, and science tasks.
Here is an example of Kimi solving a problem in a step-by-step manner, such as identifying the question, applying the right method, and presenting the final answer with reasoning.
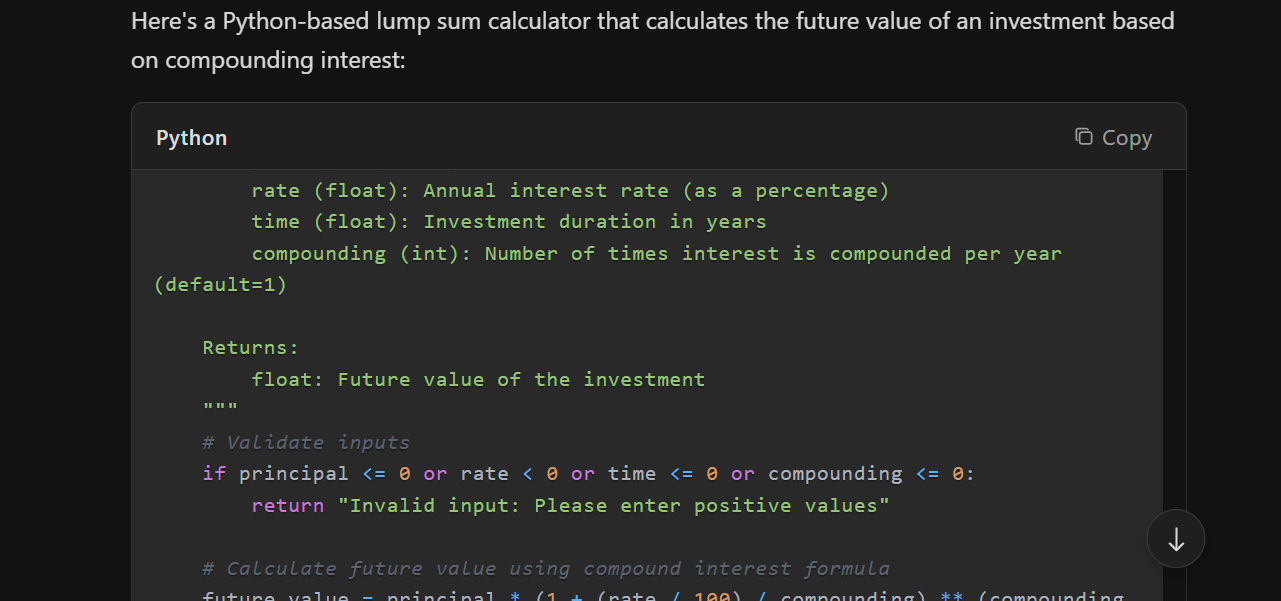
Reinforcement Learning
Kimi uses RL to learn from trial and error. It tries different answers, checks what works, and improves. Its training uses a clever system called partial rollouts, which lets it reuse past ideas without wasting computer power. This method helps Kimi become smarter and faster.
Powerful Long Context Memory (128,000 Tokens)
Most AI tools lose track after a few pages. Kimi can handle long conversations or documents, up to 128,000 tokens. It is ideal for summarizing books, analyzing legal contracts, or following long coding threads without forgetting earlier details.
Multilingual and Cross-Cultural Support
Kimi k1.5 supports over 20 languages and interprets context-sensitive expressions, making it effective for cross-cultural communication and localization tasks. This helps in writing emails, communicating across borders, and understanding foreign content clearly.
Fast and Efficient
Kimi delivers responses in under 500 milliseconds, offering near-instant interaction. It also runs smoothly on devices without using too much storage or memory. Users get a fast and smooth experience while chatting with Kimi.
Privacy and Security
Kimi takes user safety seriously. It uses strong privacy tools like end-to-end encryption and anonymous data handling. It also follows global data rules, and users can choose how their data is saved or deleted. These measures position Kimi as a privacy-conscious AI assistant compliant with global data regulations.
Open Source and Customizable
Kimi is open-source, which means developers can use and change it freely. They can add it to their apps, train it for special tasks, or improve it for their own projects. Its open-source architecture allows businesses and developers to embed custom AI features into their applications.
Performance Benchmarks
Kimi has done very well in tests against other top AI models like GPT-4o and DeepSeek-R1. Here are some key scores:
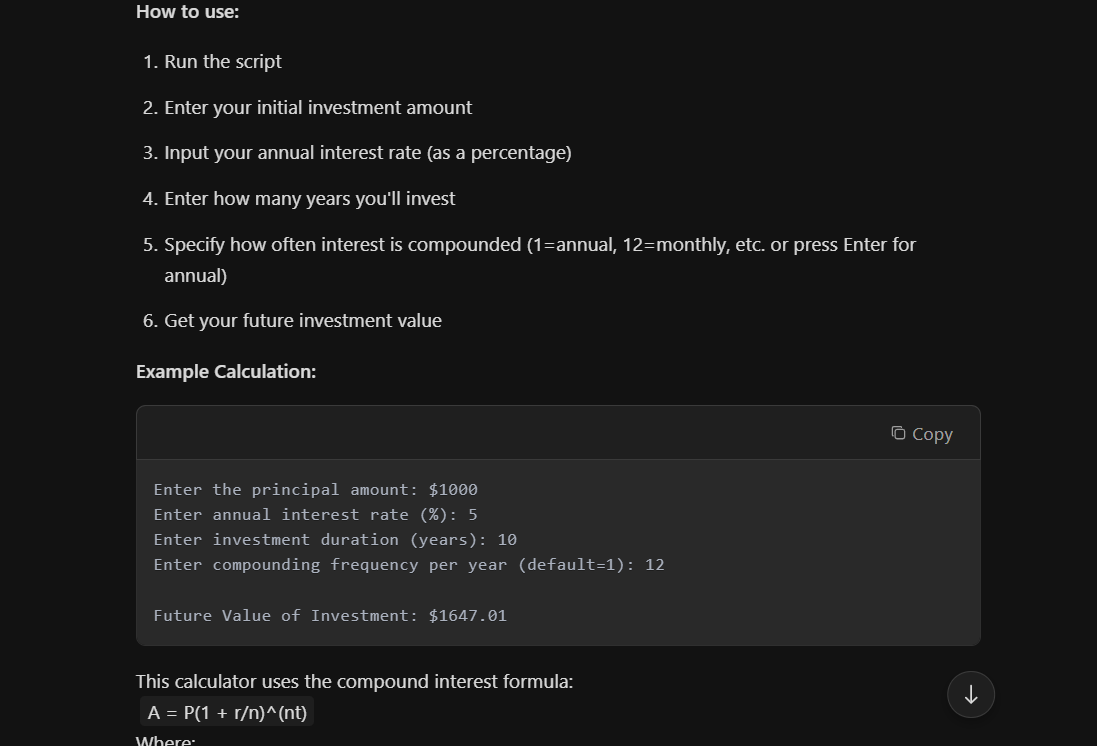
Kimi performs exceptionally across key benchmarks. It scored 77.5 on AIME, far ahead of GPT-4o's 9.3, and achieved 96.2 on MATH 500, surpassing most top models. In coding tasks, Kimi earned 47.3 on LiveCodeBench and ranked in the 94th percentile on Codeforces, showing strong real-world and competitive programming skills. It also demonstrated robust multimodal reasoning with a 74.9 score on MathVista.
3. Qwen3
Qwen is a family of cutting-edge large language models developed by Alibaba Group. It stands for "Query with enhanced network" and is designed to handle a wide range of tasks like coding, reasoning, image analysis, and multilingual communication. The latest release, Qwen3, marks the third generation of this model family and includes eight models ranging from lightweight (0.6B parameters) to extremely powerful configurations (235B parameters).
Qwen3 models compete with state-of-the-art models such as GPT-4o, DeepSeek R1, and Gemini 2.5 Pro, delivering a rare combination of strong performance, cost control, and open licensing. Built with both dense and Mixture-of-Experts (MoE) architectures, Qwen3 supports multimodal input, meaning it can process text, image, audio, and even video.
Key Features of Qwen3
Hybrid Reasoning Modes
Qwen3 introduces a hybrid reasoning approach with two modes: Thinking Mode for complex tasks involving multi-step logic, and Non-Thinking Mode for faster, lightweight interactions. This setup helps optimize token usage and balance performance with speed, depending on the task.
Flexible Depth of Thinking
Users can control how deeply the model thinks, choosing between shallow or deep reasoning. This feature is especially valuable for enterprises, allowing developers to manage compute costs while maintaining output quality.
Agentic and MCP Support
Designed for intelligent agents, Qwen3 supports advanced tool-calling and Model Context Protocol (MCP) for better external interaction and state management. This makes it ideal for building autonomous AI agents in domains like finance, healthcare, and HR.
Enhanced Training
Qwen3 was pre-trained on 30 trillion tokens and supports long-context processing up to 32K tokens. Its post-training involved reinforcement learning and Chain-of-Thought (CoT) techniques, enhancing its reasoning and comprehension skills.
Multimodal Capabilities
Qwen3 can handle text, images, audio, and video inputs. This makes it versatile for tasks like visual analysis, transcription, and multimodal chatbots, enabling broader use cases beyond conventional text generation.
Open-Source and Accessible
Released under the Apache 2.0 license, all Qwen3 models are freely available for download, use, and modification. This openness is a major advantage over proprietary models like GPT-4.
Multilingual Support
Supporting over 119 languages, Qwen3 is ideal for global applications, including translation, multilingual sentiment analysis, and customer support systems.
Efficient Architecture
Qwen3 includes both dense and Mixture-of-Experts (MoE) models. Dense models activate all parameters, while MoE models selectively activate parts of the network, offering high performance with reduced computation.
4. Wu Dao 3.0
Wu Dao 3.0 is a suite of open-source large language models developed by the Beijing Academy of Artificial Intelligence (BAAI) in 2023. Built under the Aquila family, these models are designed to support multilingual, multimodal, and cost-efficient AI applications.
Unlike its predecessor Wu Dao 2.0, which focused on scale, Wu Dao 3.0 emphasizes practicality, smaller dense models, and real-world usage. It includes models for dialogue (AquilaChat), code generation (AquilaCode), and visual tasks (EVA, vid2vid-zero). Wu Dao 3.0 enables startups, researchers, and developers to build advanced AI tools using fewer resources, while maintaining competitive performance.
Key Features of Wu Dao 3.0
Multilingual Support
Wu Dao 3.0 can process and generate content in both Chinese and English, making it suitable for global and regional applications. About 40% of its training data is in Chinese, offering high fluency in local contexts. This capability allows developers to build bilingual chatbots, localized applications, and global tools without needing separate language models.
Multimodal Capabilities
The model suite supports text and image processing. It can generate images from text prompts, understand visual inputs, and perform image-text retrieval. This makes it useful for media, design, education, and product search applications. Tools like EVA and Painter handle tasks like segmentation, detection, and visual learning.
AquilaChat Dialogue Model
AquilaChat is the conversational model in the Wu Dao 3.0 suite. It comes in 7B and 33B parameter versions, trained in both Chinese and English. It enables natural, context-aware dialogue, making it ideal for virtual assistants, customer service bots, and educational AI tutors.
AquilaCode for Code Generation
AquilaCode is a text-to-code generation model that converts prompts into working programs. It can handle tasks from basic math scripts to complex applications. This tool supports developers, educators, and low-code use cases, helping automate code writing or explain logic using natural language.
Advanced Visual Processing
Wu Dao 3.0's vision tools include EVA, EVA-CLIP, and vid2vid-zero. These models perform image recognition, segmentation, and video editing. Trained on public datasets, they achieve state-of-the-art results on tasks like object detection and semantic understanding, with minimal supervised data required.
Cost Efficiency
Unlike large dense models, Wu Dao 3.0 uses sparse activation, meaning it only activates needed parameters during inference. This reduces GPU usage and energy costs. Being open-source, it also removes licensing fees. These features make Wu Dao 3.0 cost-effective for startups and research labs.
5. GLM-4 Plus (ChatGLM)
ChatGLM is an open-source family of large language models developed by Zhipu AI and Tsinghua University. Designed for bilingual applications, particularly in Chinese and English, it builds on the Generalized Language Model (GLM) framework. ChatGLM supports both generative and discriminative tasks using a combination of autoregressive generation and bidirectional encoding.
Newer variants like GLM-4, GLM-4-Plus, and ChatGLM-6B are optimized for dialogue, long-context processing, reasoning, and tool use. The models are efficient to train and run on smaller hardware, making them suitable for real-world deployment in education, customer service, and AI development.
Key Features of GLM-4 Plus (ChatGLM)
Bilingual Dialogue Optimization
ChatGLM is specifically tuned for question-answering and conversational tasks in both Chinese and English. It performs well in real-time dialogue systems, maintaining context over multiple turns and generating coherent, informative replies.
It suits real-time applications like chatbots, tutoring assistants, and virtual agents that require language understanding across two major languages.
Tool-Augmented Reasoning
Advanced ChatGLM versions, including GLM-4 All Tools, are capable of autonomous tool use. The model can browse the web, run Python code, call APIs, and use custom-defined functions. This feature enables it to handle complex workflows like data analysis, code generation, and real-time information retrieval, positioning it alongside advanced proprietary agents like GPT-4 All Tools.
Long-Context Processing
Certain versions of ChatGLM, such as GLM-4-9B-Chat-1M, support extremely large context windows, up to 1 million tokens. This allows them to understand and reason over long documents like legal contracts, research papers, or book chapters without truncating information, offering accurate summarization, document-level Q&A, and long-context retention.

Multilingual Support
Beyond Chinese and English, ChatGLM has been extended to support up to 26 languages including Japanese, Korean, German, and others. This multilingual capability allows it to be used in cross-border customer service, translation systems, and multilingual knowledge assistants, making it suitable for global AI deployments.
Proximal Policy Optimization (PPO) for Alignment
Recent versions like GLM-4 Plus use Proximal Policy Optimization (PPO), a reinforcement learning technique, to better align outputs with human preferences. This improves the model's performance in tasks involving reasoning, math, and programming by optimizing how it learns from feedback, similar to what OpenAI does with RLHF.
Modular Agent Architecture
The GLM-4 All Tools setup supports a modular agentic framework, where the core model can spawn specialized agents (e.g., GLM-1, GLM-2) to solve subtasks. Each agent can handle domain-specific logic, allowing for distributed, recursive task execution, particularly useful in multi-step workflows.
High Numerical Reasoning Accuracy
In benchmark tests, ChatGLM-6B answered 95% of numerical queries correctly, outperforming GPT-3's 85%. Its architecture is particularly strong in factual accuracy, numerical robustness, and error correction during number-based Q&A, ideal for use in finance, quantitative analysis, and compliance.
Efficient Deployment on Edge Devices
ChatGLM supports quantized versions (INT8/INT4) that reduce memory and computation load, enabling inference on edge devices or lightweight GPUs (6 to 8 GB VRAM). This makes it a strong candidate for use in embedded AI systems or low-cost servers.
Open-Source Availability and Community Adoption
All major versions of ChatGLM (ChatGLM-6B, GLM-4-9B, GLM-4V, etc.) are released on Hugging Face, attracting millions of downloads. The open licensing model encourages research, fine-tuning, and deployment in both academic and commercial environments, making it one of the most accessible alternatives to proprietary models like GPT-4.
Cost and Compute Efficiency
ChatGLM is designed for efficient use of computational resources. The models can be deployed on GPUs with as little as 6 GB of memory using INT4 or INT8 quantization. Training costs are significantly lower than comparable models like GPT-3. ChatGLM-6B was trained for around $1.5 million. Its reduced infrastructure requirements make it accessible to startups, academic institutions, and smaller enterprises.
Read Also: Top 6 Chinese AI Models Like DeepSeek (2026 Edition)
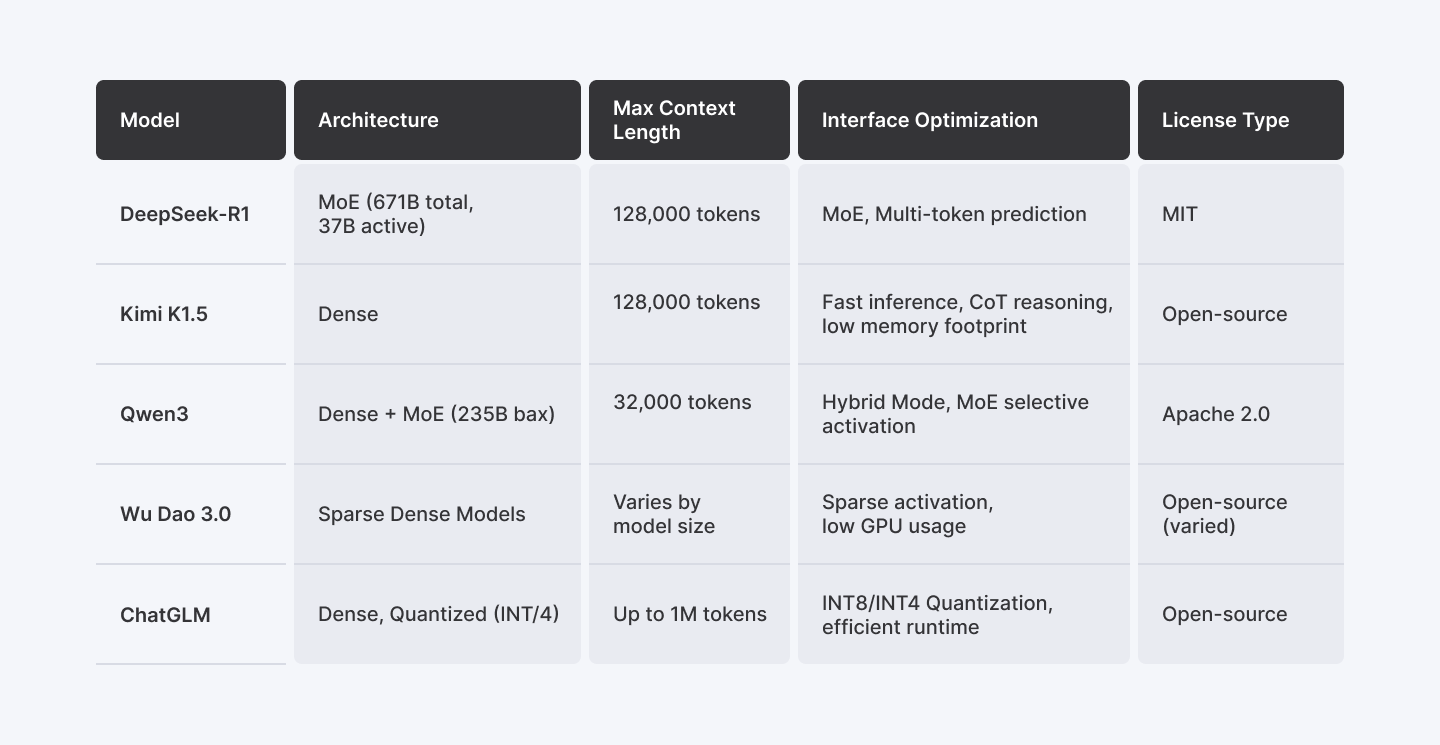
Comparison of Top Chinese Open-Source LLM Models
The table below compares five major open-source large language models across key architectural and performance-related features. It highlights how each model handles long-context inputs, optimizes inference efficiency, and what licensing terms they offer for developers and organizations.
| Model | Architecture | Max Context Length | Inference Optimization | License Type |
|---|---|---|---|---|
| DeepSeek-R1 | MoE (671B total, 37B active) | 128,000 tokens | MoE, Multi-token prediction | MIT |
| Kimi k1.5 | Dense | 128,000 tokens | Fast inference, CoT reasoning, low memory footprint | Open-source |
| Qwen3 | Dense + MoE (235B max) | 32,000 tokens | Hybrid Mode, MoE selective activation | Apache 2.0 |
| Wu Dao 3.0 | Sparse Dense Models | Varies by model size | Sparse activation, low GPU usage | Open-source (varied) |
| ChatGLM | Dense, Quantized (INT8/4) | Up to 1M tokens | INT8/INT4 Quantization, efficient runtime | Open-source |
When to Pick Which Model: A Decision Matrix
Choosing the right Chinese open-source LLM depends on your workload, hardware budget, and deployment context. Here is a practical breakdown by use case.
| Use Case | Best Pick | Why |
|---|---|---|
| Math, reasoning, and structured problem-solving | DeepSeek-R1 | 97.3% on MATH-500, MoE architecture keeps inference cost low even at 671B parameters |
| Multimodal tasks (text + image + code) | Kimi k1.5 | Handles text, images, and code in a single interface with sub-500ms latency |
| Building autonomous AI agents with tool-calling | Qwen3 | Native MCP support, 119 languages, hybrid thinking modes for balancing speed and depth |
| Low-budget teams and research labs | Wu Dao 3.0 | Sparse activation, smallest resource footprint, modular sub-models (AquilaChat, AquilaCode, EVA) |
| Long-document analysis (legal, research, compliance) | ChatGLM (GLM-4-9B-Chat-1M) | 1M token context window, INT4 quantization runs on 6 GB GPUs |
| Bilingual Chinese-English production apps | ChatGLM or Qwen3 | ChatGLM is optimized for CN/EN dialogue; Qwen3 covers 119 languages for global reach |
| Cost-sensitive commercial deployment | DeepSeek-R1 (distilled variants) | Distilled Qwen/LLaMA-based versions maintain strong performance at a fraction of the compute |
Where These Models Win in Production
Chinese open-source LLMs are no longer lab experiments. They are shipping in production across industries, often replacing proprietary alternatives to cut costs and avoid vendor lock-in.
DeepSeek-R1 in Finance and Quant Research
Quantitative trading firms and financial research teams have adopted DeepSeek-R1 for its reasoning accuracy on numerical tasks. Its MoE architecture lets firms run complex financial modeling queries at a fraction of the GPU cost of dense models. Per a 2025 LMSYS Chatbot Arena analysis, DeepSeek-R1 ranked in the top 5 for mathematical reasoning, ahead of several proprietary models.
Kimi k1.5 in EdTech and Customer Support
Moonshot AI reported over 20 million monthly active users for Kimi by late 2025, with strong adoption in education platforms (step-by-step math tutoring) and customer support bots (multilingual ticket triage). The sub-500ms latency makes it practical for real-time chat interfaces where users expect instant responses.
Qwen3 in Enterprise AI Agents
Alibaba Cloud's enterprise customers use Qwen3 to build internal AI agents that call APIs, query databases, and execute multi-step workflows using MCP. The hybrid thinking mode lets teams balance inference cost against reasoning depth per query, a practical lever for controlling cloud spend at scale.
ChatGLM in Legal and Compliance
Chinese law firms and compliance teams use GLM-4-9B-Chat-1M to process full-length contracts and regulatory filings in a single pass. The 1M token context window eliminates the chunking workarounds that plague shorter-context models, reducing error rates on cross-reference questions by 30 to 40% compared to retrieval-augmented approaches (per Zhipu AI's 2025 case studies).
Deployment Considerations for Global Teams
Deploying Chinese open-source LLMs outside China raises practical questions that most comparison posts skip. Here is what to know.
- Data residency: All five models can be self-hosted anywhere since they are open-source. You do not need to send data to China-based servers. Download weights from Hugging Face or ModelScope and run inference on your own infrastructure.
- Export controls: US export restrictions (October 2022, updated 2024) restrict the sale of advanced GPUs to China, but do not restrict the use of open-source model weights from China. Deploying DeepSeek or Qwen on US/EU infrastructure is not restricted.
- License compliance: DeepSeek (MIT) and Qwen (Apache 2.0) have the most permissive licenses. Wu Dao and ChatGLM use varied open-source terms. Check each model's specific license for commercial-use clauses before shipping.
- Multilingual quality: For English-only workloads, benchmark carefully. These models are optimized for Chinese first. DeepSeek-R1 and Qwen3 show the smallest CN-to-EN performance gap; Wu Dao 3.0 has the largest.
- Community and support: Qwen and DeepSeek have the most active English-language GitHub communities. ChatGLM's documentation is primarily in Chinese, though the Hugging Face model cards are bilingual.
Final Words
Chinese open-source LLMs like DeepSeek, Kimi, Qwen, Wu Dao 3.0, and ChatGLM are making advanced AI more accessible and practical. These models are designed for real tasks: solving math problems, understanding long documents, supporting multiple languages, and running efficiently on low-cost hardware.
Each one brings something unique: DeepSeek's Mixture-of-Experts efficiency, Kimi's multimodal strength, Qwen's hybrid reasoning and agentic support, Wu Dao's modular design, and ChatGLM's edge-ready deployment. They are not just powerful. They are efficient, flexible, and freely available under open licenses.
Together, they reflect a shift toward open, high-performance AI that serves both local and global needs. For developers, researchers, and businesses, these models offer the tools to build smarter applications without the cost or limits of closed platforms.
For Developers
Build with the best. Join Index.dev to work on AI-first engineering projects with the top 1% of human-vetted senior engineers from LATAM and CEE. 30,000+ engineers drawn from a pool of 2.5 million professionals, each vetted through a five-stage process with a ~1.2% acceptance rate. Matched in 48 hours.
For Clients
Need developers fluent in AI, LLMs, and open-source tech? Hire from Index.dev's top 1% of human-vetted senior engineers from LATAM and CEE. 30,000+ engineers, matched in 48 hours, with a 30-day risk-free trial. Clients save 40 to 60% on engineering costs, and 97% return for a second engagement.
