GenerativeAI systems' inception began with unimodal models. There is only one modality for their input, and only one modality for their output, though both don't need to be the same. Think chatbots that receive text prompts and generate text answers, while image generators like DALL·E 2, can receive text prompts and generate images based on those prompts.
Advancements in deep learning, neural network architectures, and natural language processing have enabled AI to understand the world the way humans do. Now, generative AI can generate multimodal outputs just like we can. Similar to how humans learn by using multiple senses, multimodal generative AI systems are trained on diverse modalities simultaneously.
In this detailed guide, we’ll compare Unimodal vs. Multimodal AI models. We'll explain how they perform functions, how they work, their key differences, and the distinctive approaches they have when developing AI systems.
Read more: 6 AI Model Optimization Techniques You Should Know
Top Generative AI Models and Technologies
Generative AI or GenAI models are designed to recognize patterns and structures in their input training data and generate new content that mimics these characteristics. This allows them to produce a wide range of content, including text, images, videos, and audio.
Unlike traditional AI models that need to be spoon-fed information (supervised learning), GenAI takes a more independent approach. It utilizes unsupervised and semi-supervised learning techniques. This flexibility allows GenAI to learn from both labeled (categorized) and unlabeled data and constantly expand its knowledge base for the creation of new, exciting content.
Generative AI encompasses a wide range of technologies, including:
- Large Language Models (LLMs) use extensive text data, learning from patterns to forecast sentence successions or even generate coherent paragraphs autonomously.
- Generative Adversarial Networks (GANs) are used in image synthesis, art creation, and video generation. It leverages the two competing networks, the generator and the discriminator, to generate highly realistic content.
- Variational Autoencoders (VAEs) learn to compress data into a simpler form allowing them to generate new samples from the learned distribution.
- Autoregressive Models create data one piece at a time, using each previous piece to generate what comes next. They predict the next part based on what they've already made. A well-known example is GPT (Generative Pre-trained Transformer).
- Recurrent Neural Networks (RNNs) handle sequential data, like sentences or time-series data and generate new sequences by predicting the next element in the sequence part based on previous ones.
- Transformer-based Models are popular for tasks like natural language processing and generating content. They use attention mechanisms to understand relationships in data.
The progress of GenAI is unstoppable, with endless potential applications in our current technology.
Partner with Index.dev to hire senior, vetted Gen AI engineers, ML specialists, NLP experts, UX designers, and AI developers in just 48 hours →
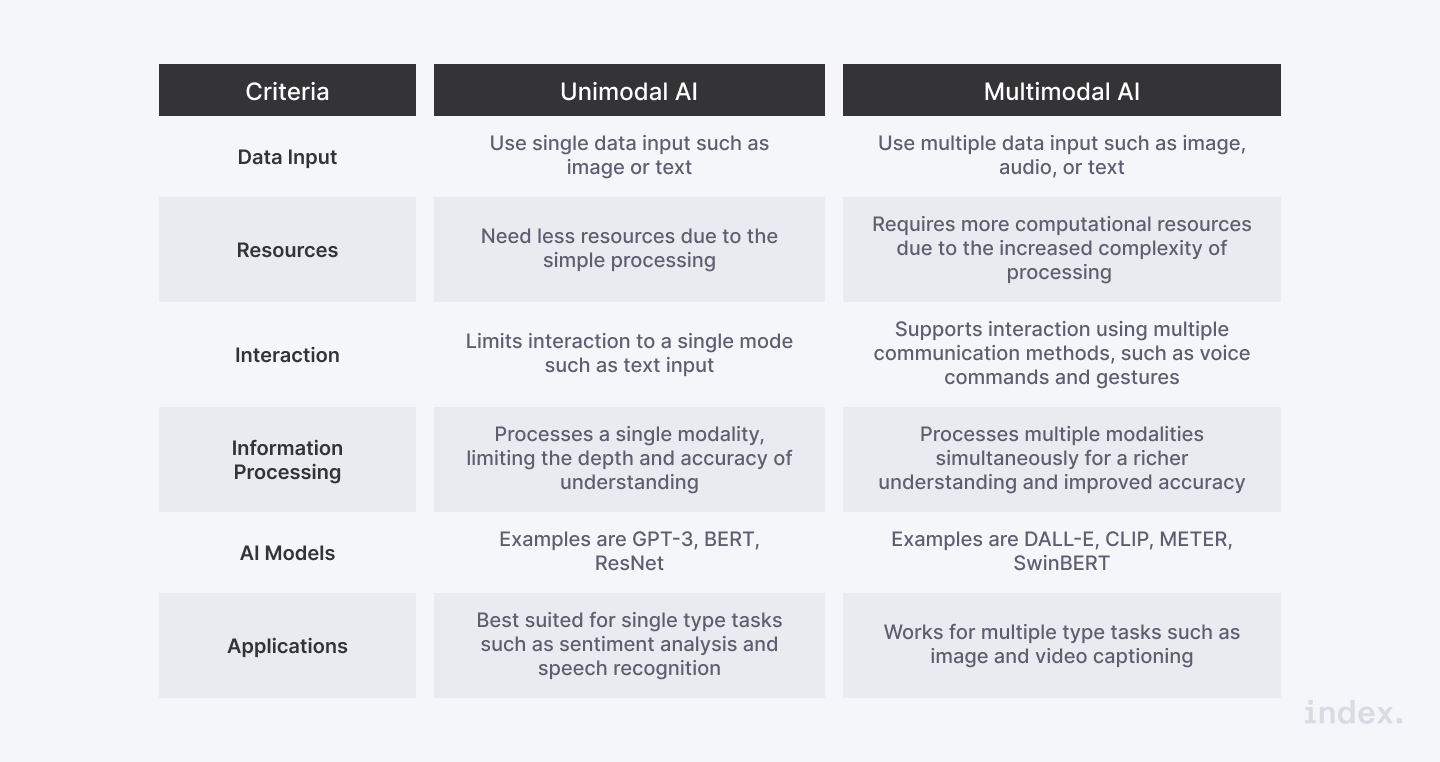
Unimodal vs. Multimodal AI Models: Key Differences
While performing similar tasks, multimodal and unimodal AI models take a different approach to develop AI systems. Therefore, unimodal models train AI models to execute a specific task using one type of data source, while multimodal models combine data from various sources to analyze a given problem.
They also differ in terms of their:
Data Scope
The key difference between unimodal and multimodal AI models is their scope of data. Unimodal AI models are designed to analyze and process one type of data, while multimodal models combine multiple data sources and integrate them into a common system capable of handling text, images, video, and audio.
Context
Due to their limited data processing capabilities, unimodal models have a massive disadvantage when it comes to the accuracy of context comprehension. They may lack the context or any other supporting information that can be crucial in making accurate predictions.
In contrast, multimodal models integrate data from multiple sources which enable them to analyze a prompt more comprehensively, thus getting more contextual information and leading to more accurate predictions.
Complexity
Unimodal AI systems are less complex since they only need to process one source of data. Unimodal AI systems are generally less complex than multimodal AI systems since they only need to process one type of data. On the other hand, multimodal AI systems require a more complex architecture to integrate and analyze multiple data sources simultaneously.
Performance
Both models can perform well in their given tasks. However, unimodal models may struggle when dealing with tasks requiring a broader context comprehension. Multimodal AI systems can handle context-intensive tasks seamlessly and offer a more comprehensive and nuanced analysis.
Data Requirements
Unimodal AI systems require a huge amount of single data type to train. Contrarily, multimodal models can be trained with smaller amounts of data, as they integrate data from multiple sources, resulting in a more robust AI system.
Technical Complexity
Multimodal models require a more complex architecture to analyze multiple sources of data simultaneously. This added complexity demands more technical expertise and resources for their development and maintenance processes than unimodal AI systems.

Factors to Consider When Choosing a Modality
The following factors should be considered when choosing a training modality for machine learning, for example:
- Data Availability: Data availability dictates which modality is more feasible. So, think first if there is enough high-quality data for your task.
- Task Relevance: How relevant is this modality to achieve your ultimate performance goal? The more complementary information for your task, the better.
- Encoding Complexity: How difficult will it be to encode the source of data? Texts demand simpler encoding while videos are more complex.
- Fusion Complexity: How easy will it be to integrate that modality with others? Adding complexity to your modality increases the fusion difficulty.
- Performance: What performance potential could that modality provide? Adding complexity to improve accuracy is worth it.
A balance between these factors will help you determine the most effective modality for your specific application.
Read more: What is a Large Language Model? Everything you need to know!
Unimodal Models: A Detailed Overview
What is Unimodal AI?
Unimodal AI models involve using only one type of data, or modality. Examples of modalities are text, image, audio, and video. Traditional machine learning algorithms are mostly unimodal. This means they are tailored to work with just one type of input data. Therefore, convolutional neural networks (CNNs) are used for analyzing image data, while recurrent neural networks (RNNs) are leveraged for analyzing sequential data like text.
Key Components of Unimodal Model
Following are the key components of unimodal AI:
- Data Input: The single type of data the model processes, such as text, images, video, or audio.
- Feature Extraction: The techniques used to extract features from the data input: convolutional layers for images and word embeddings for text.
- Model Architecture: The model structure – this could be neural networks or recurrent neural networks, depending on the task.
- Training Algorithm: The method used to train the model, including techniques like gradient descent to adjust model parameters based on the data input.
- Evaluation Metrics: Criteria used to evaluate the model’s performance on specific tasks, involving accuracy, precision, or recall.
How Unimodal Models Work
The model starts with a single data input. For example, if the task demands image classification, the data input would be a set of images. Before feeding the data into the model, the data is preprocessed. This might include image normalization, text tokenization or noise reduction.
Then the model extracts important features from the data. The model is trained using these features to learn patterns and make predictions. For images, this might include detecting edges and patterns, for text, this could involve capturing semantic meanings.
During training, the model learns to map input features to the desired output by adjusting its parameters. Once trained, the model can analyze new data and provide results based on what it has learned.
Advantages of Unimodal Models
There are several advantages to unimodal AI models, as listed below:
- Simplicity: Unimodal models are easier to design and implement since they focus on a single type of data, leading to a straightforward development process.
- Efficiency: These models require fewer computational resources, making them faster and cost-effective.
- Focus: They can achieve ultimate performance on one specific task, since they are optimized for that particular type of data.
- Data Requirements: Data collection, analysis, and management is simple, reducing the complexity of the data preparation process.
Limitations of Unimodal Models
Just with any technology type, unimodal models have some limitations:
- Limited Context Understanding: Models trained on a single modality cannot capture the full context and information that might come from combining multiple data types.
- Less Robustness: Relying solely on one type of input makes these models less robust, especially when dealing with noisy or incomplete data.
- Reduced Flexibility: As far as tasks may require integrating information from different modalities (e.g. understanding content from images and texts) is concerned, they underperform.
- Limited Insights: These models are prone to higher errors since relying on a single data type, providing less comprehensive insights compared to multimodal models. They also can’t replicate how humans perceive and learn from multiple senses.
Unimodal Models Applications
Unimodal models are like detectives that focus on one kind of clue. Here's how can help humans in different ways:
- Object Detection: Unimodal models can identify objects in photos, like telling cats apart from dogs and helping self-driving cars and security cameras see objects.
- Sentiment Analysis: They analyze text to figure out emotions, such as identifying whether a review is positive or negative.
- Speech Recognition: They can listen to speech and transcribe it into words, helping in building applications like virtual assistants and automated transcription services.
- Spam Detection: They can help filter email text, analyzing text to classify emails as spam or legitimate.
- Optical Character Recognition (OCR): Unimodal models can convert scanned documents and photos into text you can edit and search.
- Recommendation Systems: Unimodal models can analyze user preferences and behaviors to recommend products, movies, or music. They can suggest products, movies, or music based on your preferences and past choices.
- Medical Diagnosis: In healthcare, unimodal models can analyze medical images (e.g., X-rays, MRIs) to provide assistance in diagnosing diseases.
5 Use Cases of Unimodal Models
1. Healthcare:
- Applications: Medical image analysis (e.g., X-rays, MRIs), diagnosis support, and patient data management.
- Example: Using image classification to detect anomalies in radiology images.
2. Finance:
- Applications: Fraud detection, credit scoring, stock market prediction, and customer sentiment analysis.
- Example: Analyzing transaction data to identify potential fraudulent activities.
3. Technology:
- Applications: Natural language processing (NLP) for chatbots, virtual assistants, and automated transcription services.
- Example: Implementing speech recognition for voice-activated devices.
4. Automotive:
- Applications: Object detection for autonomous driving, driver monitoring systems, and predictive maintenance.
- Example: Utilizing object detection models to help security cameras detect and classify objects on the road.
5. Marketing:
- Applications: Customer sentiment analysis, market research, and targeted advertising.
- Example: Analyzing social media posts to gauge public sentiment about a brand or product.
Read more: Comparing Top LLM Models: BERT, MPT, Hugging Face & More
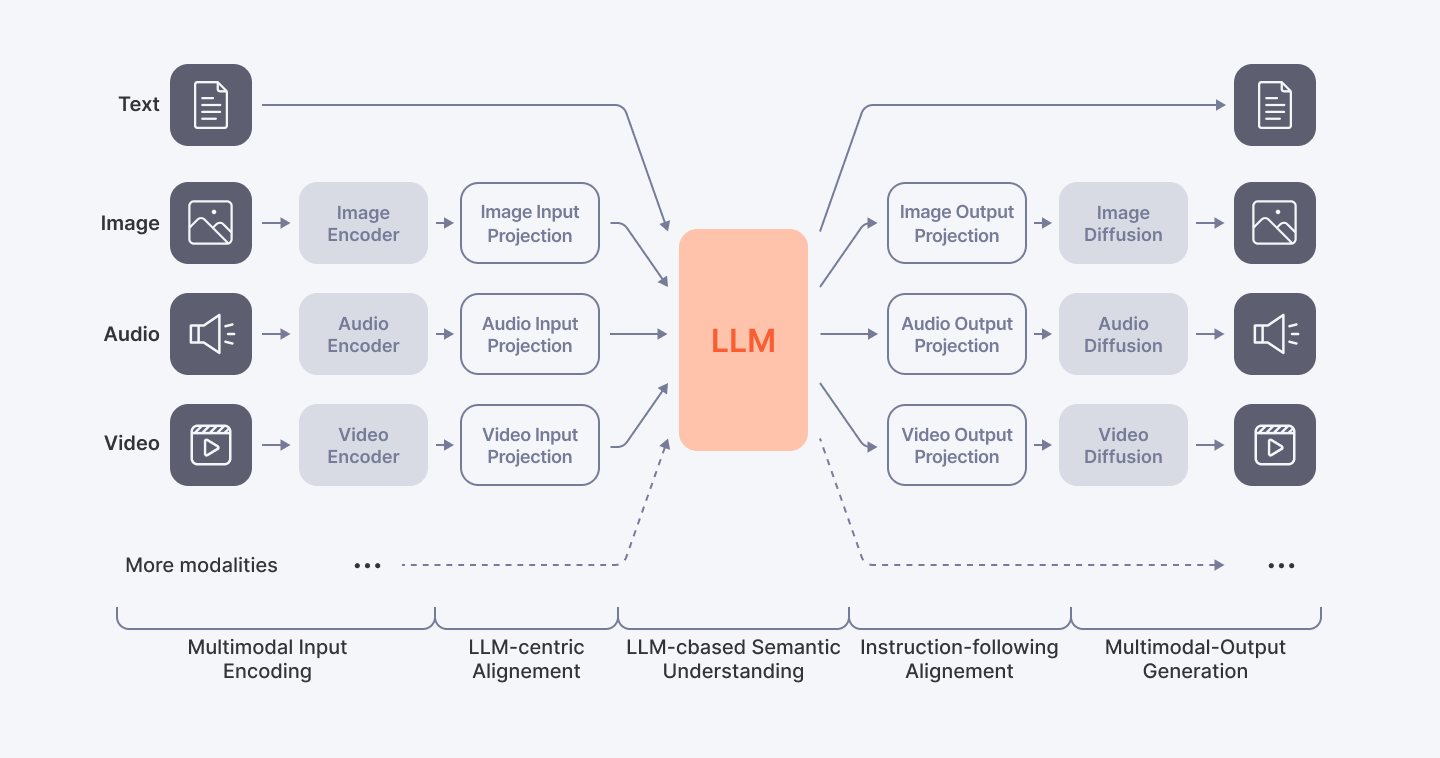
Multimodal Models: A Detailed Overview
What is Multimodal AI?
Research forecasts that the global multimodal AI industry will hit $4.5 billion at a compound annual growth rate of 35% by 2028. Multimodal models can comprehend and interpret multiple data types simultaneously, including text, images, video, or audio. It combines data inputs from various sources and generates accurate contextual information yielding neural network topologies, deep learning techniques, and insights. An example of multimodality is Alexa from Amazon. This assistive technology can interpret verbally and visually commands, and provide text-based responses. These virtual assistants can also carry out activities like reminding consumers and managing smart home applications.
Crucial Components of Multimodal AI
The key components of multimodal models are the following:
- Input Module: This module acts like the AI’s senses, gathering different data types such as text and images and it prepares this data for further processing.
- Fusion Module: Think of this as the AI’s brain, combining all the collected data from several sources and using advanced techniques to highlight the most important details and build the bigger picture.
- Output Module: This module provides the final output. After processing the data, it presents the final results or responses to the user.
How Multimodal Models Work
Multimodal models begin by gathering data from various sources, such as text, images, audio, or other modalities. Each modality’s data is processed separately by specialized encoders extracting relevant features from the input data. These encoders are responsible for processing the input data from each modality separately. Therefore, an image encoder would process an image, while text encoders would process text. The extracted features from different modalities are combined in a fusion network, integrating the information into a single representation. The fusion network considers the context of the input data and comprehends the relationship between different modalities and their significance. After contextual understanding, a classifier makes predictions based on the fused multimodal representations. The classifier is trained on the specific task and is responsible for making the final decision. The next stage is fine-tuning, involving adjusting the parameters of the multimodal AI model to optimize its performance on specific datasets. Once trained and fine-tuned, the multimodal model can be used for inference, making predictions or classifications on new or unseen data inputs.
Advantages of Multimodal Models
There are several advantages to multimodal AI models, as pointed below:
- Natural Interaction: Multimodal models enable inputs from multiple modalities, including speech, gesture, and facial expression, improving the human-machine interaction.
- Improved accuracy: They accomplish greater accuracy in tasks like speech recognition, sentiment analysis, and object recognition.
- Context Comprehension: Multimodal models excel in comprehending the context by combining both textual and visual data analysis.
- Robustness: These models reduce the noise or mistakes made in individual modalities, being more resilient to changes and uncertainties in data to produce more accurate predictions and classification.
Challenges of Multimodal Models
As with any new technology, multimodal AI comes with several downsides, including:
- Higher Data Requirements: Multimodal models require large amounts of data from multiple modalities for it to be trained properly.
- Computational Complexity: It can be computational demanding to process and analyze large amounts of data from several modalities at once, requiring stronger hardware and more effective algorithms.
- Data Alignment: The proper alignment of data is challenging due to differences in format, timing, and semantics.
- Limited Data Sets: The performance of a multimodal model can be hampered by the restricted or limited availability of labeled data for training.
- Ethical and Privacy Concerns: The fact that multimodal models are created by people, might lead to bias and discriminatory outputs related to gender, religion, race, or more. Plus, their algorithms might be trained based on data that include sensitive or personal information, raising legitimate concerns about the security of names, addresses, or financial information.
Multimodal Models Applications
Multimodal models offer transformative changes for a wide range of industries, including:
- Gesture Recognition: These models are crucial to translating sign language. They can identify and understand human gestures and translate them into text or speech format, closing important communication gaps.
- Video Summarization: They can extract audio and visual information facilitating video summarization.
- Medical Diagnosis: They can provide assistance in medical diagnosis including patient records and medical scans.
- Autonomous Vehicles: Multimodal models can impact singificanlty the evolution of autonomous vehicles, helping them analyze data from radar, cameras, LiDAR, sensors, or GPS.
- Image Captioning: These models generate descriptions for images, demonstrating a robust comprehension of both visual and linguistic information, essential for content recommendations and automatic image labeling.
- Emotion Recognition: They can detect human emotions including voice tone, text sentiment, and facial expressions, assisting in sentiment analysis on social media.
- Text-to-Image Generation: These models help generate images from text descriptions, contributing to advertising, art, design, and many more.
- Virtual Assistants: They can comprehend and respond to voice commands used in voice-controlled devices, digital personal assistants, and smart home automation.
Partner with Index.dev to hire senior, vetted Gen AI engineers, ML specialists, NLP experts, UX designers, and AI developers in just 48 hours →
5 Use Cases of Multimodal AI
1. Healthcare:
- Applications: Medical image analysis (e.g., X-rays), written reports, medical scans, and patient records.
- Example: Analyzing MRI scans, patient history, and generic markers to diagnose cancer.
2. Weather Forecasting:
- Applications: Satellite imagery, weather sensors, historical data.
- Example: Analzying historical weather patterns to provide more accurate weather predictions.
3. Automotive:
- Applications: Driver assistance systems, HMI (human-machine interface) assistants, radar and ultrasonic sensors.
- Example: Using voice commands to adjust the temperature, change the music, or make a phone call without taking their hands off the steering wheel.
4. Media and Entertainment:
- Applications: Recommendation systems, personalized advertising experiences, and targeted advertising.
- Example: Creating targeted advertising campaigns, leading to higher click-through rates and conversions for advertisers.
5. Retail:
- Applications: Customer profiling, personalized product recommendations, and improved supply chain management.
- Example: Creating a detailed profile of each customer, including their preferences, purchase history, and shopping habits for personalized product recommendations.
Read more: Examining the Leading LLM Models: Top Programs and OWASP Risks
Next Steps
Let Index.dev be your trusted partner in hiring vetted generative AI engineers to unlock the full potential of your multimodal AI project.
Why choose Index.dev:
- Train more efficiently AI models and systems
- Develop a custom model for your domain-specific task
- Ensure smooth integration of AI models into your existing infrastructure
And if you're a skilled generative AI engineer seeking high-paying remote jobs, joining Index.dev can connect you with promising projects in the US, UK, and EU markets.
