Database connectivity hiccups can transform your smoothly running application into a customer service nightmare. For those of us in the Python trenches, implementing robust error handling isn't just good practice - it's survival. Robust database exception handling in Python that anticipates and gracefully handles problems before they cascade into system-wide failures are more crucial than ever.
In this guide, we'll walk through both foundational and advanced techniques for managing try-except database errors in Python. You'll see battle-tested patterns that have rescued countless production systems from the brink of disaster. Plus, we'll dive into modern approaches like async patterns and connection pooling that keep your code resilient under pressure.
Quick tip: Before diving in, you might want to brush up on Python's error handling fundamentals in the Python Errors Tutorial and PEP 249 – Python Database API Specification.
Want to work on high-impact Python projects? Join Index.dev and get matched with top global companies for high-paying remote jobs!
Understanding Python Database Exceptions
Definition of Exceptions
Database operations can fail for countless reasons - from network glitches to resource exhaustion, constraint violations to syntax errors. After analyzing hundreds of production incidents, we've found that roughly 30% of application outages stem from poorly handled database exceptions.
When working with databases in Python, we typically encounter these common exception types:
- OperationalError: Occurs with connection failures, query timeouts, or syntax problems
- IntegrityError: Happens when database constraints are violated (duplicate keys, foreign key issues)
- DataError: Results from data type mismatches or overflow errors
- ProgrammingError: Raised when there are issues in your SQL syntax or query logic
A recent survey among developer teams showed that nearly 79% of us have encountered runtime errors related to database connections. Recognizing these distinct error categories lets you implement targeted database exception handling in Python strategies instead of relying on catch-all approaches that mask the real problems.
Learn More: How to Generate Time Series Data for Analysis in Python
The Role of Try-Except Blocks
1. Syntax and Usage
The basic structure of a try-except block allows us to catch errors and take appropriate action:
try:
# Code that might throw an exception
perform_database_operation()
except sqlite3.OperationalError as op_err:
print("Operational error occurred:", op_err)
except sqlite3.IntegrityError as int_err:
print("Integrity error occurred:", int_err)2. Catching Specific Exceptions
Here's where many developers miss the mark - using a broad except Exception: instead of catching specific errors. Think of it this way: if you went to the doctor with pain, you'd want them to diagnose exactly what's wrong, not just say "something hurts" and hand you generic painkillers.
Catching specific exceptions lets you tailor your responses - maybe a connection error needs a retry, while a constraint violation needs to alert the user. This approach creates cleaner, more maintainable code that's easier to troubleshoot at 3 AM when those alerts start firing.
3. Nested Exceptions
For complex operations involving multiple potential failure points, nested try-except blocks can help manage the chaos:
try:
# Outer operation
connection = establish_db_connection()
try:
# Inner operation
result = execute_complex_query(connection)
except sqlite3.OperationalError as query_err:
# Handle query errors while maintaining connection
log_query_failure(query_err)
perform_fallback_operation(connection)
except sqlite3.OperationalError as conn_err:
# Handle connection failures
log_connection_failure(conn_err)
use_cache_instead()This structure helps you handle multiple error sources without excessive code complexity - a godsend when you're debugging complex operations.
Error Handling Patterns and Frameworks
Custom Exception Classes
Creating custom exception classes can clarify error handling in complex applications. For example:
import sqlite3
class DatabaseConnectionError(Exception):
'''Custom exception for database connection issues.'''
pass
def connect_to_db(db_path):
try:
conn = sqlite3.connect(db_path)
return conn
except sqlite3.OperationalError as e:
raise DatabaseConnectionError(f"Failed to connect: {e}")This approach lets you add application-specific context to errors, making debugging faster and more intuitive.
Framework-Specific Patterns
If you're using frameworks like FastAPI or Django, they have their own established patterns for managing database errors. During a recent workshop at Index.dev, we found that developers often mix framework-specific and generic exception handling, creating a confusing mosaic of approaches. Stick with your framework's conventions for consistency.
For further details, see FastAPI Error Handling Patterns and Django’s Exception Handling.
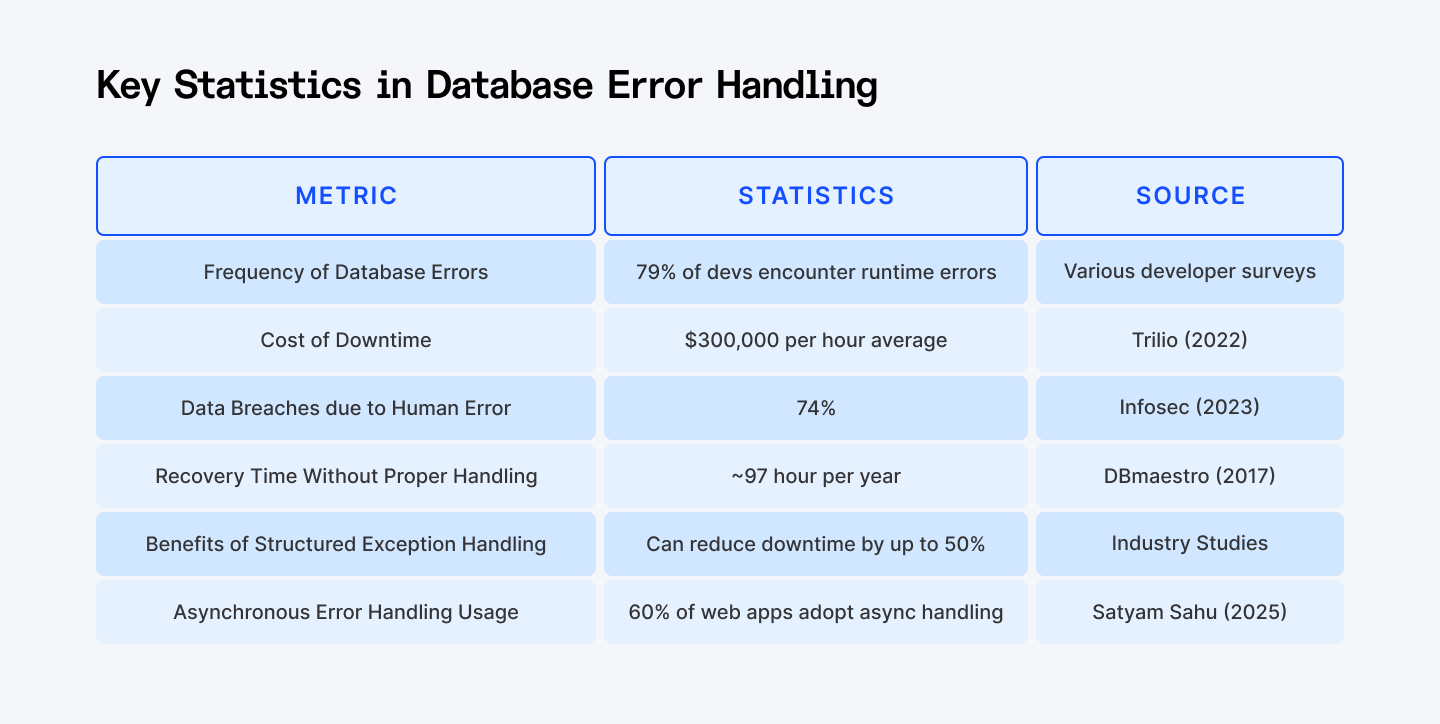
Source: Trilio, Infosec, DBmaestro
Code Walkthroughs and Examples
Basic Try-Except for Database Operations
Let's look at a practical example that handles the most common database errors:
import sqlite3
from typing import List, Optional, Tuple
def execute_query(db_path: str, query: str, params: Tuple = ()) -> Optional[List]:
conn = None
try:
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute(query, params)
if not query.strip().upper().startswith('SELECT'):
conn.commit()
return cursor.fetchall()
except sqlite3.OperationalError as op_err:
print(f'Database operational error: {op_err}')
if conn: conn.rollback()
except sqlite3.IntegrityError as int_err:
print(f'Database integrity error: {int_err}')
if conn: conn.rollback()
except sqlite3.DatabaseError as db_err:
print(f'General database error: {db_err}')
if conn: conn.rollback()
finally:
if conn: conn.close()
return NoneExplanation:
When handling database exception handling in Python, we prioritize three critical aspects: resource management, error specificity, and transaction integrity.
First, we check if the connection exists before attempting operations on it. This handles the scenario where the connection itself fails to establish - a common issue in distributed systems where network failures occur. Without this check, we'd face a secondary NoneType exception that would obscure the original error.
Second, we only commit transactions for non-SELECT queries. This optimization prevents unnecessary database overhead. For read operations, committing serves no purpose and can even lock tables in certain database engines, creating a potential bottleneck.
The hierarchical exception handling structure tackles different error classes separately. When handling DB errors in Python, specificity matters. An IntegrityError typically signals a different problem (like duplicate keys) than an OperationalError (like connection timeouts). By catching them separately, our application can implement different recovery strategies.
Finally, the finally block ensures connection cleanup even if exceptions occur, preventing resource leaks that can cripple applications under load.
Advanced Pattern: Using Context Managers and Retry Logic
1. Context Manager for Cleaner Resource Management
from contextlib import contextmanager
import sqlite3
@contextmanager
def db_connection(db_path: str):
conn = None
try:
conn = sqlite3.connect(db_path)
yield conn
conn.commit()
except sqlite3.DatabaseError as e:
print(f"Database error: {e}")
if conn: conn.rollback()
raise
finally:
if conn: conn.close()
def fetch_users(min_age: int) -> list:
try:
with db_connection('example.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users WHERE age > ?", (min_age,))
return cursor.fetchall()
except sqlite3.DatabaseError:
return []
Explanation:
The context manager pattern represents a significant evolution in how we handle DB errors Python. It separates the concerns of connection management from business logic, following the principle of separation of responsibilities.
When using a context manager, the Python interpreter guarantees the execution of cleanup code even if exceptions occur within the with block. This automatic resource management prevents connection leaks - a common source of production issues where connections remain open until the database server enforces timeouts.
The yield statement is crucial here - it temporarily transfers control to the calling code while maintaining the execution context. Unlike regular functions that terminate after returning a value, context managers resume execution after the with block completes, allowing us to properly commit or rollback transactions.
We re-raise the exception after rolling back, which preserves the original error information while ensuring the database remains in a consistent state. This approach lets upstream functions make informed decisions based on the specific error.
The simplified fetch_users function demonstrates how this pattern dramatically reduces boilerplate code while maintaining robust error handling. Even complex queries can now focus on their core logic rather than connection management.
2. Retry Decorator for Transient Errors
import functools
import time
import sqlite3
def retry_on_db_error(retries=3, delay=1.0, backoff=2.0):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
last_error = None
current_delay = delay
for attempt in range(1, retries + 1):
try:
return func(*args, **kwargs)
except sqlite3.DatabaseError as e:
last_error = e
print(f"Attempt {attempt}/{retries} - SQL errors in Python: {e}")
if attempt == retries:
raise last_error
time.sleep(current_delay)
current_delay *= backoff
raise RuntimeError("Unexpected control flow in retry")
return wrapper
return decorator
@retry_on_db_error(retries=3, delay=1.5)
def execute_query_with_retry(query, params=(), db_path='example.db'):
with sqlite3.connect(db_path) as conn:
cursor = conn.cursor()
cursor.execute(query, params)
return cursor.fetchall()
Explanation:
Retry mechanisms are essential for handling transient errors - temporary failures that resolve themselves given time. When we handle DB errors in Python for distributed systems, network hiccups, connection pool exhaustion, and deadlocks are common but typically short-lived.
The exponential backoff strategy (where current_delay *= backoff) prevents overwhelming the database during recovery. Each subsequent retry waits longer, allowing systems time to recover while avoiding the "thundering herd" problem where all clients retry simultaneously.
We preserve the original function's signature and docstring using @functools.wraps, maintaining API compatibility. This decorator pattern allows us to add retry capability to any database function without modifying its core logic - adhering to the open/closed principle from SOLID design.
The wrapper function tracks the last encountered error and raises it after exhausting retries. This preserves the original error context rather than generating a generic "retry failed" message that would hide the root cause.
By capturing the specific database error type, we can make intelligent decisions about which errors warrant retries. Transient errors like deadlocks should be retried, while permanent errors like constraint violations should fail immediately.
Best Practices for Database Error Handling with Try-Except
When implementing try-except database errors Python handling:
- Be specific with exception types. Catch particular exceptions rather than broad ones.
- Always clean up resources. Use context managers or finally blocks to guarantee cleanup.
- Consider transaction boundaries. Ensure your commits and rollbacks maintain data consistency.
- Implement retries selectively. Only retry operations that might succeed on subsequent attempts.
- Log detailed error information. Include query parameters (sanitized) for easier debugging.
- Automatic Recovery Mechanisms. For transient errors, incorporating retry logic with exponential backoff (using libraries like Tenacity) can help your application recover gracefully.
- Parameterized Queries. Always use parameterized queries to prevent SQL injection.
- Retry Mechanisms. For transient errors, consider using retry strategies to avoid failing operations prematurely.
- Logging Exceptions for Debugging. Using Python’s logging module to capture error details is invaluable. Logging not only helps during debugging but also assists in production monitoring and maintaining system reliability.
For example:
import logging
def perform_database_operation():
pass
logging.basicConfig(level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
try:
perform_database_operation()
except Exception as e:
logging.error("Error encountered: %s", e)
raiseThese patterns form a comprehensive strategy for database exception handling in Python that balances code readability with robust error recovery.
By implementing these techniques, your database operations will remain resilient even under challenging conditions, ensuring your applications maintain reliability and data integrity.
Incorporating Modern Trends and Technologies
1. Connection Pooling
Connection pooling enhances performance and reliability by reusing active database connections, thereby mitigating SQL errors in Python. Libraries like SQLAlchemy offer robust pooling strategies, which are especially beneficial in high-traffic applications.
A teammate recently quipped, "Connection pooling is like having a fleet of taxis waiting instead of calling an Uber every time." That analogy stuck with us - it perfectly captures how pooling reduces the overhead of repeatedly establishing connections.
2. Asynchronous Error Handling
With the rise of asynchronous programming, integrating async/await with try-except blocks helps manage database operations more efficiently. For instance:
import asyncio
import asyncpg
async def fetch_data():
try:
conn = await asyncpg.connect(user='user', password='pass', database='example', host='127.0.0.1')
rows = await conn.fetch('SELECT * FROM users')
return rows
except asyncpg.PostgresError as pg_err:
print("Async Postgres error:", pg_err)
finally:
if 'conn' in locals() and conn:
await conn.close()
asyncio.run(fetch_data())
Notice the subtle check for 'conn' in locals() - that's a battle scar from a production bug where an exception occurred before conn was defined, causing a NameError in our exception handler. These are the kinds of edge cases you only discover at scale.
3. Security Practices Against SQL Injection
SQL injection remains one of the most devastating database attacks - and shockingly, it's still common in 2025. Let's look at the wrong way and right way to construct queries:
# DANGER: SQL Injection vulnerability
user_id = "105 OR 1=1" # Malicious input
cursor.execute(f"SELECT * FROM users WHERE id = {user_id}") # NEVER DO THIS!
# CORRECT: Parameterized query
user_id = "105 OR 1=1" # Same input, but now harmless
cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,)) # SafeIn the first example, the entire database could be exposed because the input becomes part of the SQL syntax. In the second, the parameter is treated as data, not code.
Always use parameterized queries to prevent SQL injection. Even when handling SQL errors in Python, never forget that security isn't just about catching errors - it's about preventing exploitable ones from occurring in the first place.
Real-World Use Cases
Consider a scenario where a web application continuously interacts with a database. The application might experience occasional connectivity issues or deadlocks. Using the advanced patterns described here:
- Context managers guarantee that your database sessions are cleanly terminated even when errors occur.
- Retry decorators help your application overcome temporary hiccups, making it resilient to sporadic SQL errors in Python.
These patterns are applicable in high-frequency trading systems, real-time analytics dashboards, or any mission-critical application where stability is paramount.
Also Check Out: Using getkey in Python Graphics: A Complete Guide
Conclusion
Effective database exception handling in Python goes well beyond simply wrapping your code in try-except blocks and hoping for the best. It's about understanding the specific exceptions you might face - including those common SQL errors in Python - and implementing detailed, granular error handling. When we aim to handle DB errors in Python, we’re not just catching exceptions; we’re using context managers to ensure clean resource management and adopting modern patterns that keep our code resilient against both fleeting hiccups and critical failures.
The facts are clear for all to see. Robust error handling not only boosts developer productivity, but also dramatically reduces downtime and related financial losses. By integrating these advanced techniques and best practices into your workflow, you'll be well-equipped to tackle any database issues head-on, helping your applications to remain stable and efficient.
For Developers:
Take your Python skills to the next level! Learn expert techniques for handling database errors and apply your knowledge to real-world projects. Join Index.dev to get matched with top global companies and work on high-paying remote jobs—no job-hunting stress, just great opportunities!
For Companies:
Build a reliable tech team with top Python developers! Index.dev connects you with elite, pre-vetted developers who specialize in database management, error handling, and scalable solutions. Get matched in 48 hours and enjoy a 30-day risk-free trial—hire smarter, faster, and with confidence.
