The graph database market is projected to reach $5.6 billion by 2028, growing at a CAGR of 22.3% (Source: MarketsandMarkets). This highlights the increasing demand for graph-based solutions in handling connected data.
The open-source ecosystem has played a pivotal role in the growth of graph databases. It fosters innovation, community-driven development, and cost-effectiveness. Open-source options provide a fertile ground for experimentation and adoption, accelerating the maturation of graph technologies.
In the following sections, we will explore deeper into the core concepts, architecture, use cases, and performance characteristics of graph databases.
Expand your skills in graph databases by joining Index.dev’s global talent network and working on projects that match your expertise.
Top 10 Open Source Graph Databases
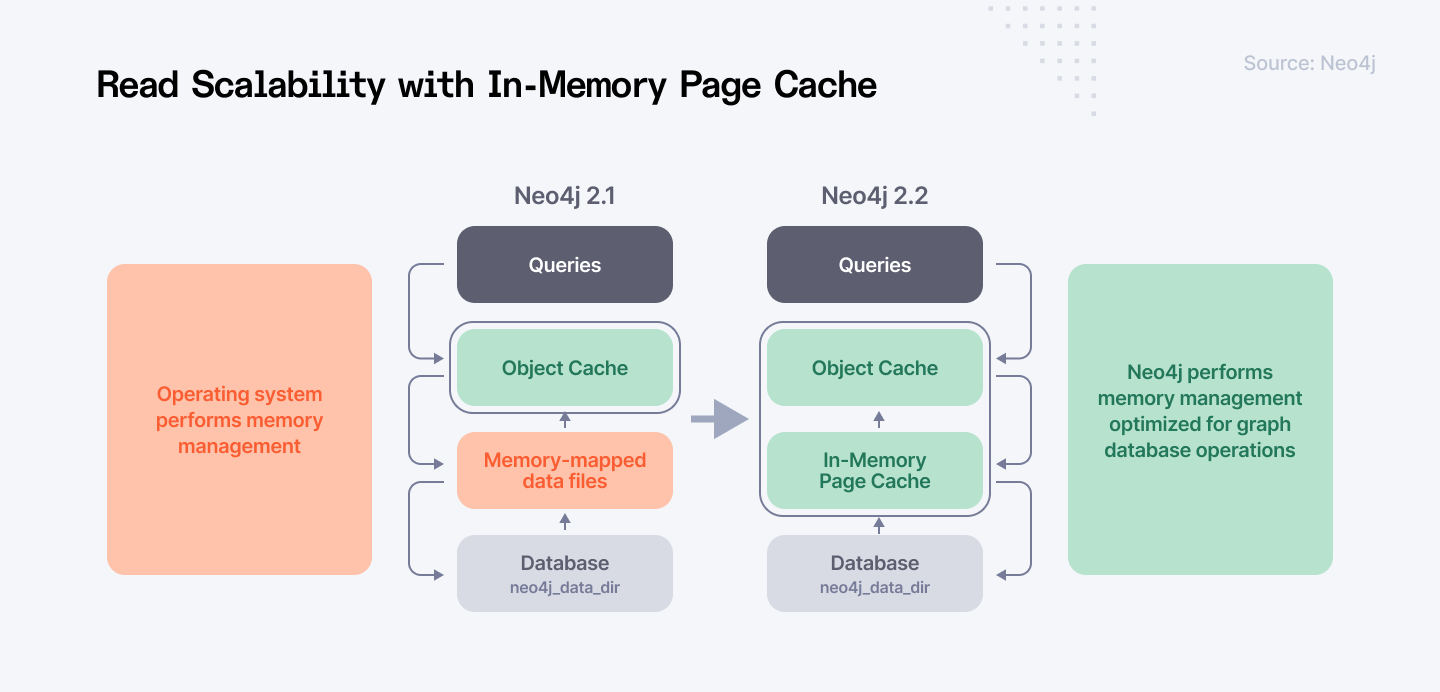
1. Neo4j Community Edition
Neo4j can traverse up to 1 billion relationships in under 500 milliseconds, making it a popular choice for real-time applications. Neo4j Community Edition is an efficient, open source graph database management system that has attracted a lot of users because of its effectiveness in handling and searching interconnected data.
In contrast to the databases where data are stored in table structures, Neo4j makes use of a graph data structure, nodes signifying entities whereas the relationships between the different entities are indicated by the links. It performs well in conditions where the data relationships are complex and constantly changing in some way.
Core Concepts
Before delving into the Community Edition, it's essential to grasp fundamental graph database concepts:
- Nodes: Users of the graph must be representative of entities or objects of the graph for instance person, place or thing.
- Relationships: G: Join nodes, indicating the relationships between nodes or activities (i.e. can be, friend of, location).
- Properties: Properties that are added to a node, or relationship and may contain more information ( i.e. name, age, city among others).
- Paths: Succession of the nodes and their associations with each other creating a network of entities.
- Cypher: Graph Data and Neo4j with its declarative query language used in traversing and controlling the graph data.
Architecture and Performance
Neo4j’s architecture is well thought out as it is laid out for the infrastructure of storing and accessing graphs. Key components include:
- Storage Engine: Responsible for the storage of data and indexing as well as fast lookup of nodes, relationships and properties.
- Query Processor: Specialized for processing and tuning Cypher queries while using indexes of the graph.
- Transaction Manager: Maintains data coherence and integrity with help of the ACID transactions.
- Clustering (Enterprise Edition): Though the clustering feature is not available in the Community Edition, it is crucial to know about clustering for scaling graph databases.
Community Edition Limitations and Use Cases
While the Community Edition is feature-rich, it has some limitations compared to Enterprise:
- Single Instance: Cannot be clustered for higher availability or scalability.
- Limited Backup Options: It has very limited backup and recovery options as compared to its competitors.
- Fewer Security Features: Less security features as distinguished from Enterprise.
2. JanusGraph
JanusGraph is described as a distributed graph database software developed under the open-source paradigm optimized for graphs containing billions of vertices and edges.
The specific benefits are high efficiency, capacities to develop, and the ability to apply this model in various ways, like social network and recommendations, fraud detection, knowledge graphs, and more. JanusGraph is built upon the Apache TinkerPop graph computing model, and it provides a unified approach to data structuring and analysis.
Core Concepts
- Property Graph Model: JanusGraph follows a property graph model where the data is nodes (vertices) and the connection between nodes (edges). The nodes and the edges can have labels which are key-value pairs containing further information about them.
- Distributed Architecture: In order to maintain responsiveness and process big graphs, JanusGraph uses the distributed environment. Data is split between different machines and thus, can be scaled horizontally.
- Storage Backends: JanusGraph works with a number of storage backends; Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle BerkeleyDB. There are many decisions made when choosing the storage backend and they include performance, scalability, and degree of required consistency.
- Index Backends: Query optimization is a crucial requirement in JanusGraph ms and the platform uses index backends for that. It supports both the composite and vertex centric indices that mean indexing is also flexible in this layer.
- Transactions: JanusGraph provides ACID transactions, which means that all changes in the graph will be isolated, atomic, and consistent. It also supports the eventual consistency for high-performance workloads.
- Gremlin: JanusGraph is based on the Gremlin graph traversal language for querying the graph data and changing it. Gremlin is a language that obviously gives a good way to deal with graph structures.
Architecture
JanusGraph builds its structure for high performance and scalability. Key components include:
- Graph Storage: The chosen storage backend is used to store the graph data which includes vertices, edges and properties of the graph.
- Index Store: The index backend is responsible for the administration of different types of indices to enhance queries’ performance.
- Transaction Manager: Isolates data through managing transactions so as to avoid data inconsistency.
- Query Engine: Handles Gremlin queries and their execution plans, including the handling of storage and index backends.
- Cluster Management: Responsible for data distribution, replication, and fault tolerance in the distributed graph environment.
Use Cases
JanusGraph is applicable to a wide range of domains. All in all, JanusGraph is useful in a variety of fields.
- Social Networks: Establishing relations among the users and friends, as well as groups.
- Recommendation Systems: An accurate selection or prescription of the different products or materials that an individual might be likely to be interested in based on their behavior.
- Fraud Detection: Identifying the general and specific tactics of the scammers in various complex interconnected environments.
- Knowledge Graphs: Concepts as texts and reasoning about the areas of knowledge and information.
- Supply Chain Management: An application of graph based analysis in a supply chain to improve a chain operation.
- IoT Data Management: Correlation of different IoT data and the ways of their processing and analysis.
Exlpore: Skill vs Skill for technology comprision.
3. ArangoDB
ArangoDB stands out with respect to other database management systems due to the multi-model nature of the system. Therefore, while the traditional database management systems are rigid in nature as they operate based on only one data model, ArangoDB is a versatile product that enables document, graph, and key-value stores.
It seems that this capability provides the greatest amount of flexibility and utility for dealing with complex data architectures and combining relations. In this analysis, a brief overview of ArangoDB will be provided followed by the explanation of the fundamental principles which include the ArangoDB architecture, its performance characteristics, and fields where this database can be utilized.
Core Concepts
The main foundation of ArangoDB are the multi-model data model capabilities. This allows for:
- Documents: Storage of hierarchies with arbitrary labels on their nodes, which is useful for expressing hierarchical relations.
- Graphs: Graph definition that involves the use of nodes (entities) and edges (relationships), which makes it possible to model complex data.
- Key-Value: Lightweight data storage system with native high through-put access pattern for key-value pairs.
Architecture
The fact that ArangoDB is based on distributed architecture ensures it is more optimized and future ready. Key components include:
- Storage Engine: The MMFiles’ default storage engine is tailored especially for memory pointer and orderly disk storage structures. RocksDB can also be used instead of LMDB.
- Query Processor: This will involve analyzing, improving, and running ArangoQL statements as part of the solution.
- Foxx Microservices Framework: Enables the development of server-side applications that utilize JavaScript in the database.
- Clustering: ArangoDB has ways of scaling out through clustering and has ways to solve distributed problems and is faster.
Use Cases
One of the most compelling reasons to use ArangoDB is that the platform incorporates multiple data models. ArangoDB's multi-model capabilities make it suitable for a wide range of applications:
- Graph-Based Applications: Recommendation systems, fraud detection, social networks and knowledge structures.
- Document-Based Applications: It can be implemented in content management systems, e-commerce facilities, data processing of IoT equipment.
- Hybrid Applications: The concept of updating the graph in real or near real-time, and the updating of the document models for the complex data representations.
4. OrientDB
OrientDB also, similarly to ArangoDB, is a multi-model database that combines document, graph, and object databases. This unique method enables it to perform well when handling different data structures. It is known for its performance and scalability, and offers SQL-like querying capabilities. Being a competitor of ArangoDB, it also has similarities with it but at the same time, it possesses certain peculiarities and advantages.
Core Concepts
- Records: Graphs and documents in OrientDB are built from ODV records, which are the core elements in OrientDB data model.
- Classes: Explain the structure of records while allowing for a certain level of expressiveness in the schema.
- Vertices: Be represented by nodes in the graph model and related through edges.
- Edges: Specify the relationships between the vertices, with attributes that can be used to describe the association.
- Documents: Store data in a JSON-like manner for greater flexibility where the data structure for the record is unknown or unimportant.
- Indexes: Facilitate various designs of indexes such as B-tree index, hash index, full-text index, etc.
- Transactions: Maintain data consistency and integrity by employment of transactions: ACID.
Architecture
OrientDB has been optimized for high performance and has been designed to scale horizontally.
- Storage Engine: PLocal is used to provide essential data access and manipulation operations as the base storage engine.
- Indexing: It has several indexes known as indexes for raising efficiency within the particular query.
- Distributed Architecture: Community Edition is used with a single instance while Enterprise Edition includes clustering.
Use Cases
OrientDB's versatility makes it suitable for a wide range of applications:
- Social Networks: Representing interaction and relationships of users in complex ways.
- Recommendation Systems: Understanding the manner in which users use applications and the kind of applications they prefer.
- Fraud Detection: Detecting different kinds of patterns in complex interdependent data.
- IoT: Collecting, archiving, and managing arrays of sensor information.
- Content Management: Search and management of a vast quantity of unstructured data.
- Master Data Management: Ensuring that there is one place where all enterprise data is stored.
5. Apache TinkerPop
Apache TinkerPop is not a database, but it is a graph computing solution. It defines a simple API to address graph databases, which enables developers to create graph applications that can run on different graph databases of the same type. This flexibility and portability have firmly established it as a fundament in the graph database tool landscape.
Core Concepts
- Graph: A kind of representation in terms of nodes and edges where each node is a vertex and the edges show the connection between the nodes.
- Vertex: Relates to some object within the graph that may be static or dynamic of any sort.
- Edge: Refers to the relationship between joining two nodes in a graph.
- Property: Information related with vertices or edges which is normally additional.
- Traversal: It is described as the process of finding routes in a graph, concrete edges or vertices joinery.
- Gremlin: TinkerPop, the graph traversal language. It provides a more powerful way without writing any complex instructions to compose graph queries.
Architecture
TinkerPop follows a layered architecture:
- Gremlin Console: A command driven application that allows a user to execute Gremlin scripts.
- Gremlin Driver: An abstraction layer and API for a graph database for using the database for interacting with it from more ‘compact’ languages.
- Gremlin Server: A server that would execute Gremlin scripts from a terminal that is located in a remote location.
- Graph Providers: Specific adaptations of the TinkerPop graph computing framework API for direct access of the graph DBMSs such as Neo4j, Titan, JanusGraph, etc.
Use Cases
TinkerPop follows a layered architecture:
- Gremlin Console: A command driven application that allows a user to execute Gremlin scripts.
- Gremlin Driver: An abstraction layer and API for a graph database for using the database for interacting with it from more ‘compact’ languages.
- Gremlin Server: A server that would execute Gremlin scripts from a terminal that is located in a remote location.
- Graph Providers: Specific adaptations of the TinkerPop graph computing framework API for direct access of the graph DBMSs such as Neo4j, Titan, JanusGraph, etc.
Ready to put your graph skills to the test? Join Index.dev's talent network and connect with innovative projects!
6. Dgraph
Dgraph is a special graph database with focus on scaling, high performance and flexibility. Contrary to other graph databases, Dgraph is implemented as a distributed system, which allows it to easily scale to large amounts of data and accommodate intricate graph models.
Core Concepts
- Schema-less: Dgraph functions based on the fact that it does not have the set schema which makes it more flexible in terms of data planning. This means that one can add new data types or relationships into it without the need to expand on the schema once more.
- Predicates: Unlike SQL that uses tables or classes, Dgraph employs predicates which are pretty much straightforward parts or relation.
- Triples: The fundamental data unit in Dgraph is a triple made up of a subject, a predicate, and an object.
- GraphQL: Again, Dgraph uses GraphQL and when constructing the search query, the query is built in GraphQL format for querying the Dgraph db.
- Distributed System: Dgraph is designed to be executed on nodes so as to be highly available and at the same time scalable.
- ACID Transactions: The data can be kept updated due to the support for ACID transactions in Dgraph.
Architecture
Dgraph's architecture is optimized for performance and scalability:
- Cluster: Dgraph is a cluster, where each node performs the roles of storing data and doing computations.
- Leader-Follower Replication: Every cluster has a chief node and several other nodes to cover the data duplication and ensure availability.
- Sharding: Scaling of data is done automatically by partitioning them across nodes so that it enhances scalability.
- Indexing: Dgraph is queried based on the predicates, and in this method, uses inverted indexes.
- GraphQL Backend: Dgraph has a GraphQL backend to serve queries in flexible format to be returned.
Use Cases
Dgraph's unique features make it suitable for a wide range of applications:
- Knowledge Graphs: Constructing and searching a large-scale knowledge base.
- Recommendation Systems: Studying user dynamics to determine compatibility and suggest relevant offerings.
- Fraud Detection: The use of complex network theories for detecting schemes of fraudulent behaviour.
- Supply Chain Management: The identification and documenting of the movement of products and resources through a supply system.
- Social Networks: It can help understand social connectedness and activity scripts.
- IoT: Collecting data from link smart devices and analyzing that data.
7. Titan
Titan is a graph database, which is based on a distributed database Apache Cassandra and ranks itself as one of the leaders in dealing with graph orientation of large-scale applications. It provides elasticity and the ability to easily scale up and down depending on a user’s needs when dealing with large and complex multifaceted datasets.
Core Concepts
The concept of Titan revolves around the graph database structure in which data is normalized into nodes and their links.
- Vertex: Any vertex of the graph which may point to an entity or an object in the information domain.
- Edge: Stands for interaction that occurs between two nodes or two vertices.
- Property: Additional details that can be associated with a vertex or an edge in a network.
- Label: A label assigned to a vertex or an edge.
- Index: Used for the quick finding of vertices or edges by the property values.
Architecture
Titan is designed above Apache Cassandra to help take advantage of its distributed architecture for scale and redundancy.
- Storage: Cassandra is used for the core storage of graph data.
- Graph Management: Titan added an API layer on top of Cassandra for graph-level transactions.
- Query Processing: Titan employs a query language based on Gremlin for traversal and operations on the graph structure.
- Indexing: Titan provides features to support different kinds of indexes to ensure that query response is fast.
Use Cases
Titan is good at serving acyclic, graph-based applications, which need to contain many nodes or edges or be frequently accessed. Some common use cases include:Some common use cases include:
- Social Networks: Using graphs to represent users, groups, and content and their connections.
- Recommendation Systems: Studying user activity and choosing an item or products based on their tendencies.
- Fraud Detection: Finding out the relationships between various data sets for detecting fraudulent behavior.
- Knowledge Graphs: Knowledge representation and reasoning in the knowledge domains.
- IoT: Explaining and categorizing the interactions of the devices and the sensor data.
8. Blazegraph
Blazegraph is a fast, easily scalable, open source graph database that is especially suited to query RDF data. It is highly applicable for scenarios that include querying, reasoning, and knowledge graph management with massive volumes of knowledge graphs.
Core Concepts
- RDF Triple Store: Fundamentally, Blazegraph can be defined as an RDF triple store. RDF data is stored using a simple data structure called triples that comprises a subject, predicate, and object. This model is the backbone of the semantic web and knowledge graphs.
- SPARQL: The best part is that the database is SPARQL compliant, the standard query language for invoking RDF data.
- Indexing: Blazegraph uses indexing methods so that the queries made to the database can be optimized especially when working with large data sets.
- Reasoning: Interestingly, external reasoners can be connected to Blazegraph in order to derive new information based on the information in the graph.
- Scalability: This type of data storage is suitable for large datasets and can be scaled up horizontally.
Architecture
Blazegraph has its architecture designed specifically for handling RDF data and executing queries.
- Triple Store: The first and major component is the triple store that is used to store RDF triples.
- Indexing: To enhance the performance of query execution, Blazegraph employs both B-Tree and inverted index approaches.
- Query Processor: The query handler deals with the analysis, optimization and execution of the SPARQL query against the loaded data.
- Scalability: The architecture is scalable, which means that distributed deployment can be used for large datasets and high query loads.
Use Cases
Blazegraph's strengths lie in managing and querying RDF data, making it suitable for a wide range of applications:
- Semantic Web Applications: For knowledge graphs construction, semantic search, and ontology-based reasoning systems.
- Linked Data: Combining data from multiple sources and using them to present information in a natural language query.
- Life Sciences: It encompasses the management and analysis of biological information such as genomics and drug discovery.
- Government and Intelligence: Processing a large amount of data and getting the most significant insights.
- Enterprise Knowledge Graphs: The role of business knowledge management and supporting organizational decision-making.
Read more: Understanding Data Types in Python Programming
9. AllegroGraph
AllegroGraph is a knowledge graph database which offers high performance for the management and the interaction of complex data. AllegroGraph is highly scalable and offers a range of relevant features, and it has been successfully employed in fields such as semantic search and recommendation, fraud detection, and life sciences.
Core Concepts
- Knowledge Graph: AllegroGraph is, at its core, a knowledge graph database. This means that it organizes knowledge in the form of nodes, entities and edges that define the relations between them.
- Resource Description Framework (RDF): RDF is naturally supported in the database since it operationally works with information as a graph. Tuples with subject, predicate, and object are at the core of data representation in AllegroGraph.
- Reasoning: AllegroGraph supports the reasoning functionality, which helps the system to find new information based on the input data and applied rules. This is particularly useful for the applications that involve data mining with high levels of knowledge aquisition.
- Querying: Data regarding the database can be accessed and modified using queries written in standard query language for RDF known as SPARQL. Additional features in AllegroGraph are based on extensions to SPARQL in order to include performance and expressiveness.
- Scalability: AllegroGraph is highly scalable, thus capable of supporting a distributed setup for its implementation that will enable it to handle enormous datasets and high numbers of queries.
Architecture
Reliability, flexibility and performance are achieved due to the specific architecture of AllegroGraph. Key components include:
- Storage Engine: AllegroGraph uses its own storage layer optimised for RDF data. It helps in maintaining and actually accessing data effectively.
- Reasoning Engine: The key component among them is a reasoning engine, which enables to derive new knowledge based on the rules defined. It is not very visible as it merely runs in the background and updates the knowledge base.
- Query Processor: As for the evaluation of SPARQL queries, the query processor deals with it by preparing the query for efficiency when it is executed.
- Indexing: Some of the indexing methods that AllegroGraph supports is important in enhancing the query performance.
- Distributed Architecture: AllegroGraph is highly scalable and for large-scale applications, multiple nodes can be used for running AllegroGraph.
Use Cases
AllegroGraph's capabilities make it suitable for a wide range of applications:
- Semantic Search: Developing smart search engines, which learn about the meaning of the submitted queries.
- Knowledge Management: Abstracting, sorting, and curating large volumes of information.
- Recommendation Systems: Selling and marketing products based on an understanding of users and past trends of similar products.
- Fraud Detection: Finding relations and patterns of fraudulent occurrences in complex datasets.
- Life Sciences: Data management and analysis of biological data for instance, drug discovery and genomics.
- Supply Chain Management: Applying ideas and information to improve supply chains.
10. AgensGraph
AgensGraph is an innovative graph database that focuses on a strong base, the PostgreSQL. It offers several benefits such as scalability, reliability besides being compliant with the ACID characteristics of transactions.
Core Concepts
- PostgreSQL Integration: AgensGraph is built-in with PostgreSQL in a way that it can share its storages, indices, as well as transaction management approaches. This makes it possible to create as well as scale a high-performance and efficient graph database.
- Graph Data Model: It follows the property graph model where the entities are the nodes and the relationships are the edges. Nodes as well as edges can have attributes that can be attributed to them.
- Cypher Support: Cypher is the programming language used in AgensGraph and those coming from other graph databases such as Neo4j will find it comfortable.
- SQL Integration: AgensGraph is built on PostgreSQL and can work in conjunction with SQL queries, which makes it possible to solve various tasks related to data decomposition and analysis.
Architecture
AGensGraph is a graph management software developed based on PostgreSQL to move its application beyond graph data. Key components include:
- PostgreSQL Core: Database support includes functions such as storage, indexing, transactions, and other functions based on the underlying database engine.
- Graph Layer: A high-level layer on top of PostgreSQL optimized for graph operations like creating nodes, creating edges and paths.
- Cypher Processor: It is responsible for analyzing and processing the Cypher queries and mapping them with the efficient operations of PostgreSQL.
Use Cases
AgensGraph's combination of graph capabilities and PostgreSQL's strengths makes it suitable for a wide range of applications:
- Social Networks: Managing multiple and intricate connections between the users, groups and the content.
- Recommendation Systems: Predicting customers’ behavior and their possible actions with a focus on making suggestions that they would find suitable.
- Fraud Detection: The process of establishment of relationships between the data components associated with fraud activities.
- Knowledge Graphs: Collecting, indexing, searching and retrieving objects and knowledge spaces that involve intricate interconnectivity.
- IoT Data Management: Long-term and short-term sensor data archive and analysis using temporal and spatial characteristics.
- Supply Chain Optimization: Developing complex supply chain network models and improving logistics.
Don't just talk graph databases, build them! Join Index.dev's vetted developer community and connect with companies actively seeking top tech talent in the graph database space!
The Bottom Line
The graph database is very effective in the case of many to many relationships, as it treats the data with nodes and relations. This structure enables faster execution of the query and analyzing complex patterns unlike the relational databases that lag behind in such matters. The rich open-source graph database market, which comprises platforms like Neo4j, JanusGraph, and ArangoDB, offers different strengths for organizations depending on the requirements of a particular task.
Thus, factors like popularity, features, performance, and the community around the graph database are also critical when making a selection. Therefore, understanding the essential idea of these databases and their application will help the business in making the right choices that will help in gaining access to those insights which will promote and foster innovation.
Index.dev. can assist organizations in this matter by providing the necessary information and tools that would allow for faster and more proficient analysis of the strengths and limitations of the planned graph database solutions so as to further maximize the organization’s potential in regards to data management.
For Developers:
Join Index.dev talent network to connect with leading companies and work on innovative projects that align with your expertise in graph databases.
For Clients:
Hire high-performing talent for your graph database projects with Index.dev! Join Index.dev talent network to access a pool of skilled developers who specialize in graph databases and find the right fit for your next project.
