Two years ago this comparison was GPT-4 against Claude 3.5 Sonnet, and the gaps were wide. In 2026 it is GPT-5.5 (OpenAI, released April 2026) against Claude Opus 4.8 (Anthropic, released May 2026), and the gaps have mostly closed. Both now ship a 1 million token context window, both browse the web, and both score within a tenth of a point of each other on SWE-bench Verified.
The interesting differences have moved from raw code generation to how each model behaves inside an agent: multi-file edits, long debugging loops, and terminal workflows. This guide compares them across ten day-to-day coding tasks, then backs the verdict with current benchmarks, a decision matrix, and where each one wins in production.
How we compared: This comparison is built from published 2026 benchmarks (SWE-bench Verified and Pro, Terminal-Bench, MMLU, GPQA) and from vendor model cards and community testing reports. The benchmark figures are sourced directly from those references.
The task-by-task observations describe documented behavior patterns for each model family, including findings carried forward from testing of earlier versions, and are not a fresh first-party benchmark run. Treat the per-task verdicts as informed guidance, then validate them on your own codebase before you standardize on one model.
5 Key Takeaways
- SWE-bench Verified is a tie: GPT-5.5 scores 88.7%, Claude Opus 4.8 scores 88.6%. On standard bug-fix tasks they are interchangeable.
- SWE-bench Pro is the real gap: Claude Opus 4.8 leads 69.2% to 58.6% on the harder, multi-file benchmark that better predicts production work.
- The context gap is gone: both models now offer a 1,000,000 token window. The old 200K vs 128K split no longer applies.
- Claude is cheaper on output ($25 vs $30 per 1M tokens) and adds parallel-subagent workflows in Claude Code, which matters for agentic coding cost and speed.
- GPT-5.5 still wins breadth: higher MMLU (92.4%) and stronger niche-language coverage. Near-parity means you should choose by workflow, not by a single leaderboard number.
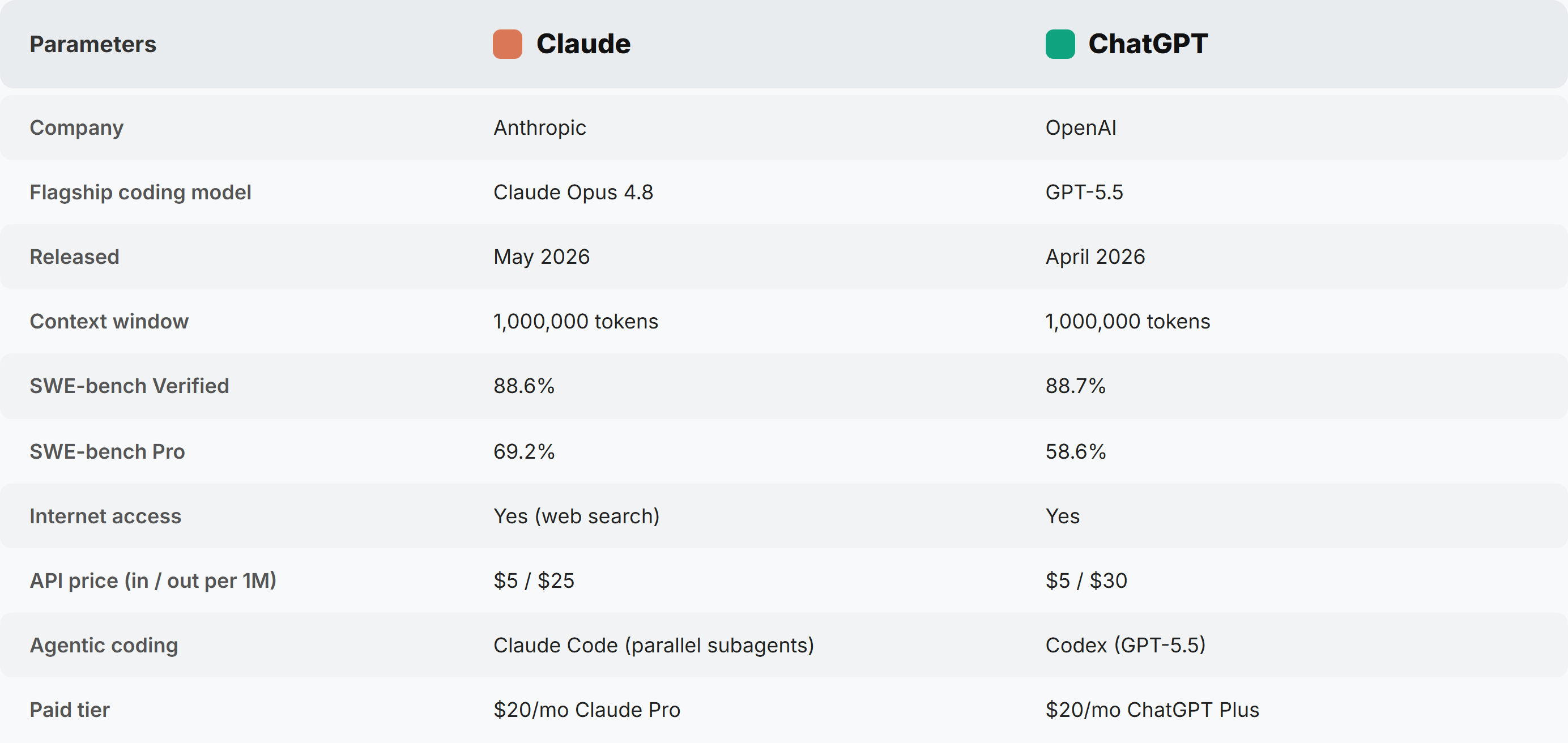
Claude vs ChatGPT at a glance
Here is a quick rundown of the two models as they stand in 2026.
What the benchmarks say (2026)
For coding, three numbers matter most. SWE-bench Verified measures real GitHub bug fixes. SWE-bench Pro is the harder, multi-file version that is now the more meaningful signal. Terminal-Bench measures agentic, command-line task completion.
| Benchmark | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|
| SWE-bench Verified (real bug fixes) | 88.7% | 88.6% |
| SWE-bench Pro (harder, multi-file) | 58.6% | 69.2% |
| Context window | 1M tokens | 1M tokens |
| API price, output per 1M | $30 | $25 |
Beyond the table, GPT-5.5 posts a higher MMLU at 92.4%, which shows up as broader general knowledge and stronger reasoning on unusual problems. Claude Opus 4.8 answers back with 93.6% on GPQA Diamond and 74.6% on Terminal-Bench 2.1, plus measurable honesty gains in Anthropic's alignment testing, which reduces confident wrong answers during long sessions. The pattern is clear: GPT-5.5 is the better generalist, Claude Opus 4.8 is the better coding agent. Scores are from each vendor's 2026 model cards and independent benchmark trackers.
1. Natural Language Understanding and Code Interpretation
Both models read plain-English requests and turn them into working code. Ask either one "how do I implement a binary search in Python" or "optimize this JavaScript function" and you get clean, code-ready output with an explanation. In reported side-by-side testing, GPT-5.5 tends to add a sharper note on edge cases, such as flagging performance issues on very large arrays and suggesting reduce() as an alternative. Claude Opus 4.8 tends to go further on intent, proposing useful extras (balancing a tree, extra traversal methods) and asking what you want before it assumes.
Verdict: Tie. GPT-5.5 for tighter edge-case analysis, Claude Opus 4.8 for anticipating what you actually need.
2. Coding Language Support
Both handle Python, Java, JavaScript, and C++ with clean, idiomatic output. They cover frontend and backend work, memory management, and object-oriented patterns well. The historic split was niche languages: GPT-5.5 still has a slight edge on Rust, Haskell, and Julia, producing more reliable solutions for ownership models and complex numerical tasks. Claude Opus 4.8 has closed most of that gap and now handles less common languages competently, though it can need a more detailed prompt for advanced functional patterns.
Illustrative task: a Python factorial
def factorial(n):
if not isinstance(n, int):
raise TypeError("Factorial is only defined for integers")
if n < 0:
raise ValueError("Factorial is not defined for negatives")
return 1 if n in (0, 1) else n * factorial(n - 1)Both models produce this almost identically. The difference shows up in framing: Claude leads with input validation and limits, GPT-5.5 leads with a recursive and an iterative version side by side.
Verdict: GPT-5.5 for niche-language breadth. Near-parity on mainstream languages.
3. Code Generation Accuracy
Accurate generation lets you skip boilerplate and focus on architecture. GPT-5.5 is strong on complex algorithms and edge cases, often returning well-explained, optimized solutions. Claude Opus 4.8 leans toward safety and reliability, adding validation and guarding against bad input. On the harder, multi-file generation that SWE-bench Pro measures, Claude's 69.2% to 58.6% lead is the clearest accuracy signal in this comparison.
Verdict: Claude Opus 4.8 for multi-file accuracy. GPT-5.5 for single-shot algorithm depth.
4. Code Completion and Suggestions
Both are fast and context-aware in 2026. Each can read across a large codebase, infer intent, and match your existing style, whether that is concise functional code or verbose object-oriented structure. Ask either to handle a Python error case and you get a clean try-except block with notes on best practice. With both at a 1M token window, whole-repo awareness is no longer a differentiator.
Verdict: Tie. Both are excellent in-editor completers.
5. Debugging and Error Handling
Both identify syntax errors, logic bugs, and performance bottlenecks, and explain why each occurred. Give either a TypeError from mixing a string and an integer and you get the fix plus the reasoning. GPT-5.5 still shines on complex, multi-system debugging with thorough explanations, which makes it a strong teaching tool. Claude Opus 4.8 is fast on quick fixes and, thanks to its 2026 honesty gains, is less likely to invent a confident but wrong root cause during a long session.
Verdict: GPT-5.5 for deep, multi-system debugging. Claude Opus 4.8 for fast, trustworthy fixes.
6. Documentation, Framework and Library Knowledge
Both write clean README files, API docs, and step-by-step library guides for NumPy, Pandas, React, TensorFlow, and PyTorch. Asked to scaffold a Flask app README, Claude returns a comprehensive walkthrough with detailed sections, while GPT-5.5 returns a tighter, essentials-first version. On framework concepts, such as static versus dynamic graphs, Claude tends to add deployment and performance context, while GPT-5.5 keeps it concise and use-case driven.
Verdict: Claude Opus 4.8 for thorough docs. GPT-5.5 for a quick, clean overview.
7. Refactoring and Code Optimization
Both suggest more efficient algorithms, cut redundant work, and improve time and space complexity. They rename variables, split long functions, and simplify nested logic without losing behavior. In practice the results are close: Claude often makes intent more explicit (early returns, clearer names), while GPT-5.5 favors compact, combined conditions. For large agentic refactors that touch many files, Claude Opus 4.8's parallel subagents in Claude Code give it a real throughput edge.
Verdict: Claude Opus 4.8 for large, multi-file refactors. Near-parity on single functions.
8. Problem-Solving and Algorithms
Both break hard problems into clear steps and explain the logic. Ask for Dijkstra's shortest path with a priority queue and adjacency list and each returns a well-commented, correct implementation. They explain time and space complexity and can move a solution from O(n squared) to O(n log n) with a reason for the change. The practical difference is speed: Claude Opus 4.8 usually returns long algorithmic answers faster.
Verdict: Tie on correctness. Claude Opus 4.8 for speed on long answers.
9. Response Time and Efficiency
Both are quick, with timing that depends on task size and model variant. Claude Opus 4.8 is generally faster on large tasks such as debugging multi-module codebases or generating long scripts, and it now offers an optional 2.5x fast mode for latency-sensitive work. GPT-5.5 trades a little speed for thoroughness on the largest jobs, but holds accuracy as input grows.
Verdict: Claude Opus 4.8 for speed, especially with fast mode enabled.
10. User Experience and Interface
ChatGPT's interface is polished and familiar, and its ecosystem (custom GPTs, Codex, broad integrations) is the widest. Claude's interface is clean and focused, and Claude Code has become the reference agentic coding tool, with parallel subagents and mid-task steering. For chat-style help, ChatGPT feels the most natural. For driving an autonomous coding agent, Claude is the smoother experience in 2026.
Verdict: GPT-5.5 for ecosystem breadth. Claude Opus 4.8 for the agentic coding workflow.
Decision matrix: which to pick by workload
| Workload | Better pick | Why |
|---|---|---|
| Agentic, multi-file refactors | Claude Opus 4.8 | SWE-bench Pro lead, parallel subagents in Claude Code |
| Quick code generation, boilerplate | GPT-5.5 | Fast, broad language and framework coverage |
| Complex, multi-system debugging | GPT-5.5 | Deeper step-by-step explanations |
| Niche languages (Rust, Haskell, Julia) | GPT-5.5 | Broader niche-language training |
| Long-context codebase review | Either | Both ship a 1M token window |
| Cost-sensitive, high-output jobs | Claude Opus 4.8 | $25 vs $30 per 1M output tokens |
| Learning and detailed walkthroughs | Claude Opus 4.8 | More thorough explanations, honesty gains |
Where each wins in production
ChatGPT (GPT-5.5)
GPT-5.5 powers ChatGPT and OpenAI's Codex, and is available in GitHub Copilot alongside other models. Teams pick it as the default for general engineering chat, broad-language prototyping, and product work where the wider ecosystem of custom GPTs and integrations matters. Its higher MMLU makes it the safer choice when coding bleeds into research, data analysis, or unfamiliar domains.
Claude (Claude Opus 4.8)
Claude Opus 4.8 is the model many teams now set as the default coding agent in tools like Cursor, Windsurf, and Cline, and it is the engine behind Claude Code. Its SWE-bench Pro lead and parallel-subagent workflows make it the stronger pick for autonomous, multi-file work: large refactors, migrations, and long-running tasks where a cheaper output price compounds across thousands of tokens.
The honest verdict
Here is the contrarian point most listicles miss: in 2026 there is no single winner, and chasing the top leaderboard number is the wrong move. The two models are within a tenth of a point on standard SWE-bench Verified, both have 1M context, and both browse the web. The real decision is workflow. If your work is agentic, multi-file, and cost-sensitive, Claude Opus 4.8 is the better default. If you want the broadest generalist and ecosystem, GPT-5.5 is the safer all-rounder. Many strong teams keep both: GPT-5.5 for breadth, Claude Opus 4.8 as the coding agent.
For developers: get matched to roles that use these tools
Index.dev is an AI-first engineering talent platform that connects companies with the top 1% of senior engineers from LATAM and CEE, around 30,000 developers, each human-vetted through technical and live interviews from a pool of 2.5M+. Roughly a 1.2% acceptance rate, with matches in 48 hours. If you build with GPT-5.5 and Claude Opus 4.8 daily, join Index.dev and get matched to teams that value AI-native engineers.
For clients: hire AI-native engineers, fast
Index.dev is an AI-first engineering talent platform that connects companies with the top 1% of senior engineers from LATAM and CEE to build software and AI products. Clients include Omio, Vodafone, Entrupy, and Stuart, as well as companies backed by Kleiner Perkins, Goldman Sachs, and Y Combinator. Engineers are human-vetted, matched in 48 hours, and deliver 40-60% cost savings on engineering projects. 97% of clients return for a second engagement. Hire through Index.dev to ship faster with senior talent who already work fluently with these AI tools.
