China is making fast progress in artificial intelligence (AI) with smart language models that can compete with top AI like GPT-5.1 and Claude Sonnet 4.6.
Models like DeepSeek-V3.2, Qwen3-Max, and Doubao Seed 1.6 are great at solving problems, writing code, and understanding text, images, and videos. In fact, these AI models can handle long pieces of text and think more like humans.
In this listicle comparison guide, we will explore their main features, how they work, and how they compare to other top AI models in 2026.
Chinese LLM models (similar to ChatGPT)
1. DeepSeek-V3
Developer/founder(s): Liang Wenfeng
Founded in: 2024 (latest release: DeepSeek-V3.2-Exp, September 2025)
What it is: DeepSeek-V3 is a large language model (LLM) with 671 billion parameters. It understands and generates human-like text. The best part of DeepSeek-V3 is that it excels in coding and mathematical tasks. By late 2025, the lineage moved on to DeepSeek-V3.1 and DeepSeek-V3.2-Exp, which kept the same backbone but added sparse attention for faster long-context work.
To enhance logical inference, mathematical reasoning, and real-time problem-solving capabilities, you now have DeepSeek R1 (launched January 2025) and DeepSeek R2 (released May 2025), with the wider community using R2 as the default reasoning model through 2026.
Both reasoning models build upon the V3 base model, incorporating reinforcement learning techniques to improve reasoning abilities.
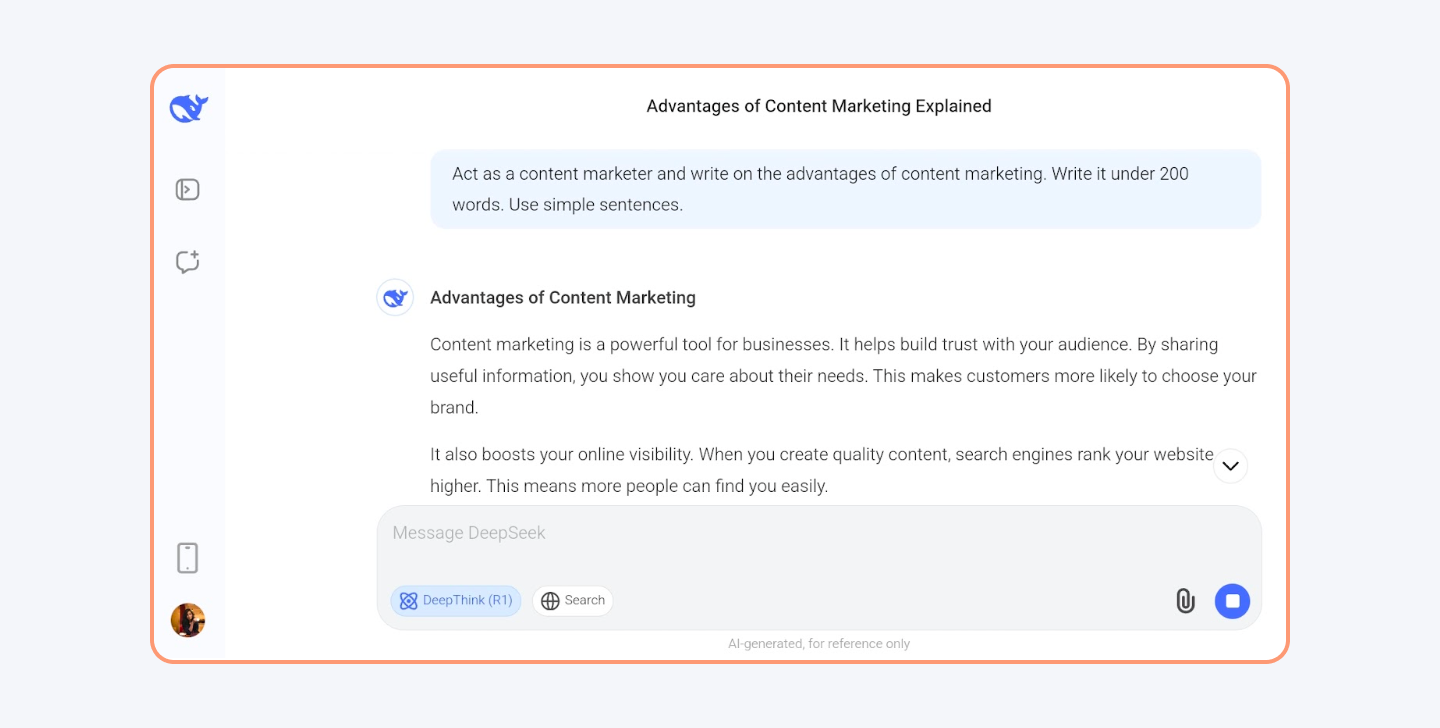
However, DeepSeek AI settings have no option to control what data is shared with its servers in China. There are some topics that the LLM will avoid answering, like the 1989 Tiananmen Square massacre.
Key features
Mixture-of-Experts (MoE) Architecture:
DeepSeek-V3 has 671 billion parameters, but only 37 billion are active per input. This makes it highly efficient compared to dense models that activate all parameters at once. V3.2-Exp carries the same parameter count and adds a new sparse-attention design that cuts inference costs by more than half.
The model selects 8 out of 256 experts dynamically for each task, optimizing both performance and cost.
Multi-Head Latent Attention:
The model implements an advanced form of attention mechanism that reduces memory usage while improving the accuracy of responses.
Extended Context Length:
DeepSeek-V3 (and V3.2) can process up to 128,000 tokens in a single prompt, making it ideal for long-form content generation, such as legal documents, books, and research papers.
Multi-Token Prediction:
Instead of predicting one token at a time, DeepSeek-V3 predicts multiple tokens simultaneously, drastically increasing inference speed.
It uses parallel token generation to generate responses up to 40% faster than its previous versions.
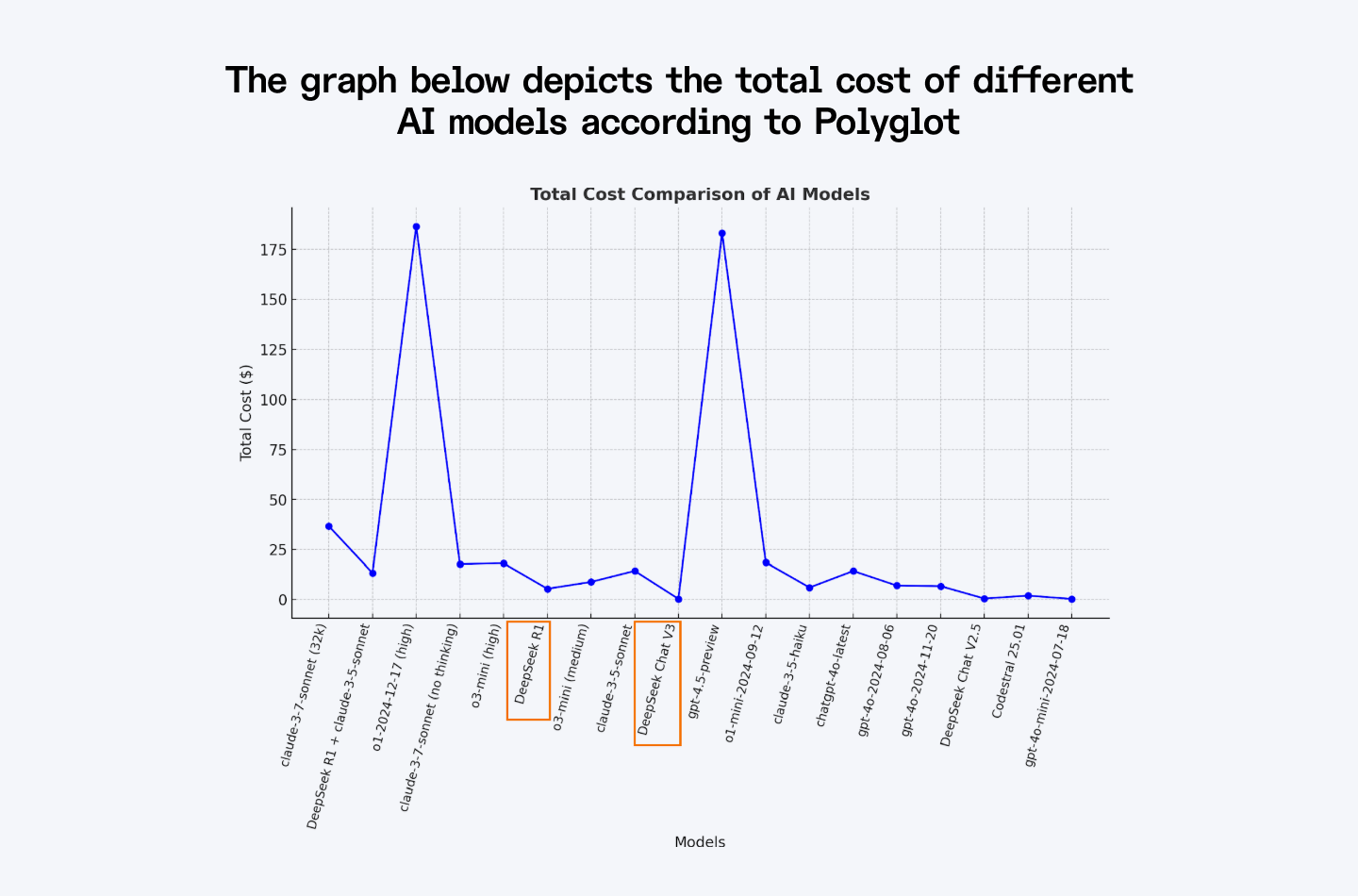
Cost Efficiency
Training DeepSeek-V3 cost approximately $5.6 million, which is significantly lower than comparable models like GPT-4o. This cost-effectiveness occurs because of its MoE architecture, which reduces computational requirements. In September 2025, DeepSeek-V3.2-Exp cut official API prices by more than 50%, so input tokens now sit around $0.28 per million and output tokens around $0.42 per million.
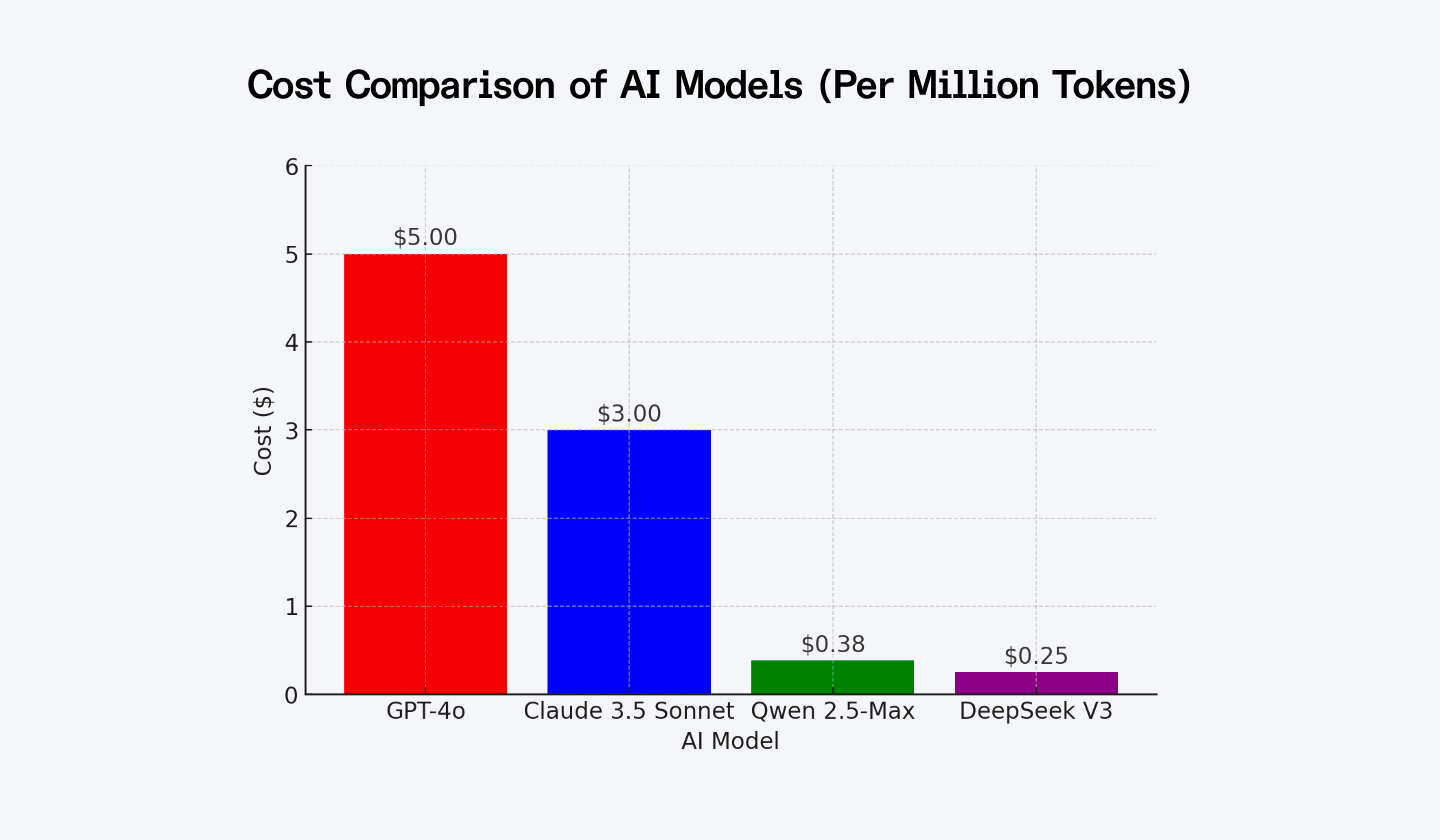
The graph below depicts the total cost of different AI models according to Polyglot.
Performance
According to the Weights & Biases report, DeepSeek V3 (and the newer V3.2) is marking a significant development in the world of LLMs.
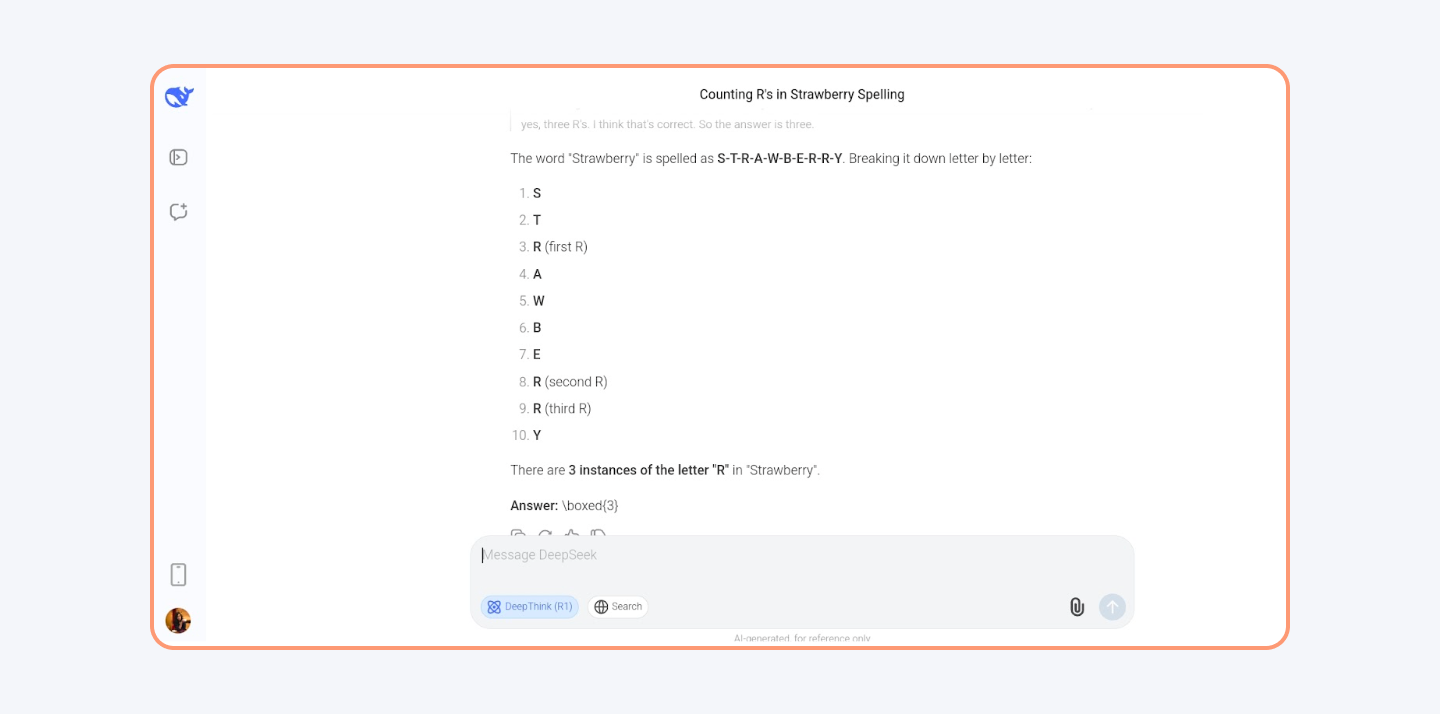
It achieves a score of 88.5 on MMLU (Massive Multitask Language Understanding), and DeepSeek-V3.2-Exp pushes MMLU-Pro to 85.0, sitting alongside Llama 3.3, Qwen3, and Claude Sonnet 4.6 in the same band.
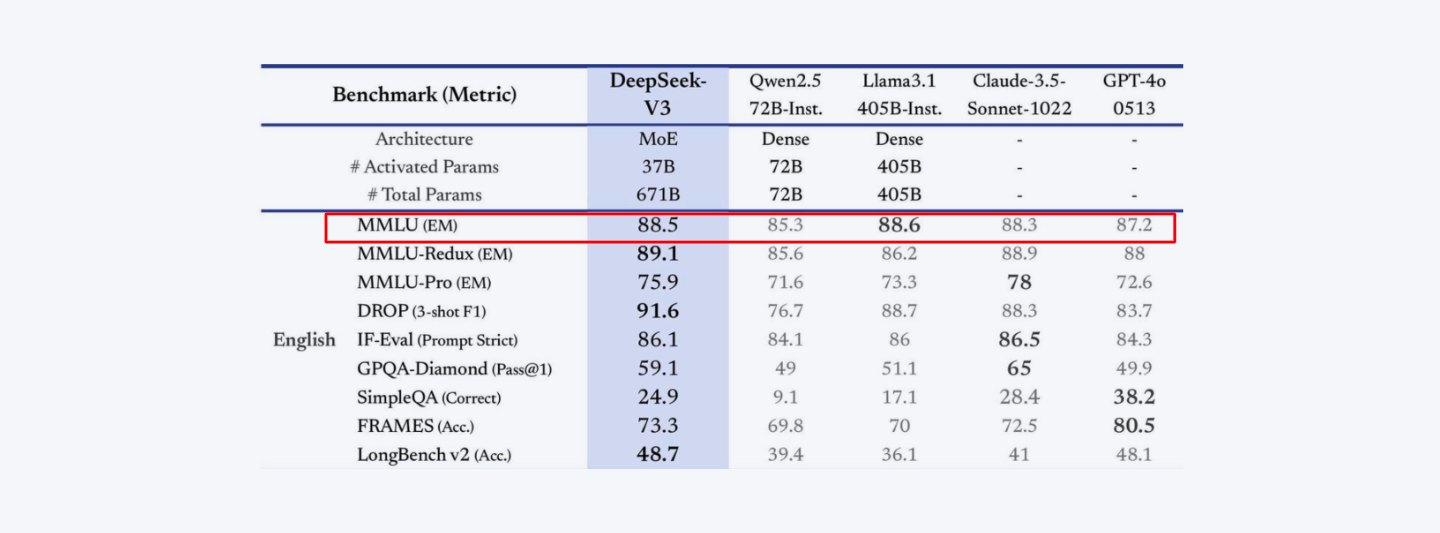
Some of its other performance stats are:
- DROP Benchmark: V3 scored 91.6 (F1), and V3.2-Exp holds at 91.4, still outperforming Llama 3.1's 88.7.
- Codeforces Benchmark: DeepSeek V3 scored 51.6, while V3.2-Exp jumps to 2121 Elo (about the 96th percentile) with the help of R2 reasoning traces.
- MATH-500 Benchmark: V3 achieved 90.2, and DeepSeek-R2 pushes this to 94.0+ on the same benchmark, demonstrating exceptional mathematical reasoning.
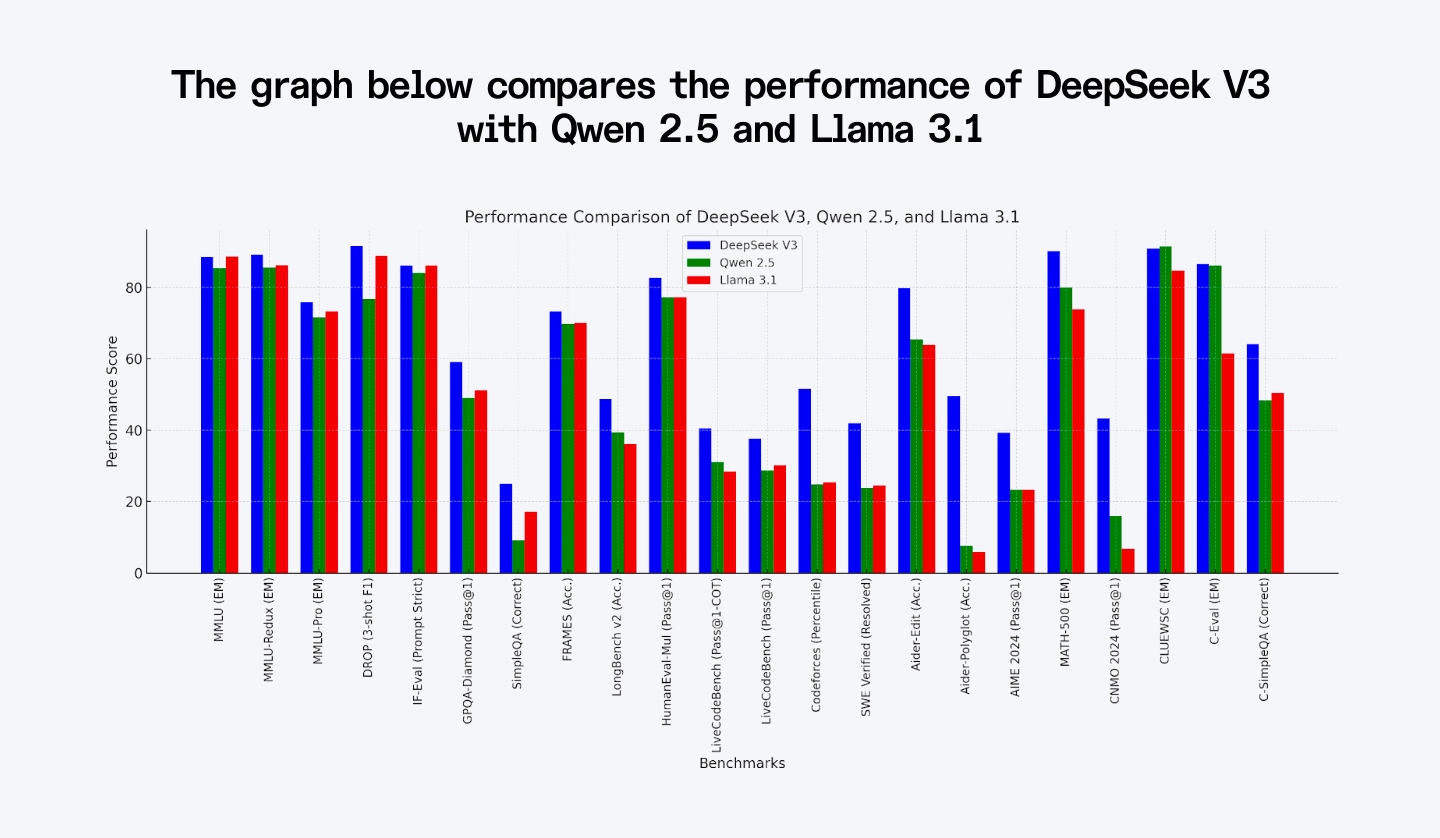
The graph below compares the performance of DeepSeek V3 with Qwen 2.5 and Llama 3.1.
2. Qwen3-Max
Developer/founder(s): Alibaba Cloud
Founded in: 2025 (Qwen3-Max general availability, September 2025)
What it is: Qwen3-Max is Alibaba’s latest flagship AI model, built with advanced architecture for efficiency and performance. It supports large-scale AI applications across various industries and is available via Alibaba Cloud’s API and the open-source Qwen3 family on Hugging Face. This LLM competes with top models like GPT-5.1 and Claude Sonnet 4.6 and excels in reasoning, coding, and multimodal processing.
Key features
MoE Architecture = More Power, Less Cost
Unlike traditional AI models that activate all parameters at once, Qwen3-Max only uses the relevant parts for a given task. This makes it about 30% more efficient on inference, meaning it delivers high performance without burning through computing power.
Trained on 36 Trillion Tokens
This model has learned from a massive 36-trillion-token dataset that includes research papers, code, multilingual content, and real-world scenarios. Plus, Alibaba fine-tuned it with Supervised Learning (SFT) and Human Feedback (RLHF) to improve its accuracy.
Handles 262K Tokens Natively (1M with Extension)
Qwen3-Max ships with a 262K context window out of the box and stretches to 1 million tokens with Dual Chunk Attention. You can drop entire legal bundles, long research papers, or whole codebases into a single call.
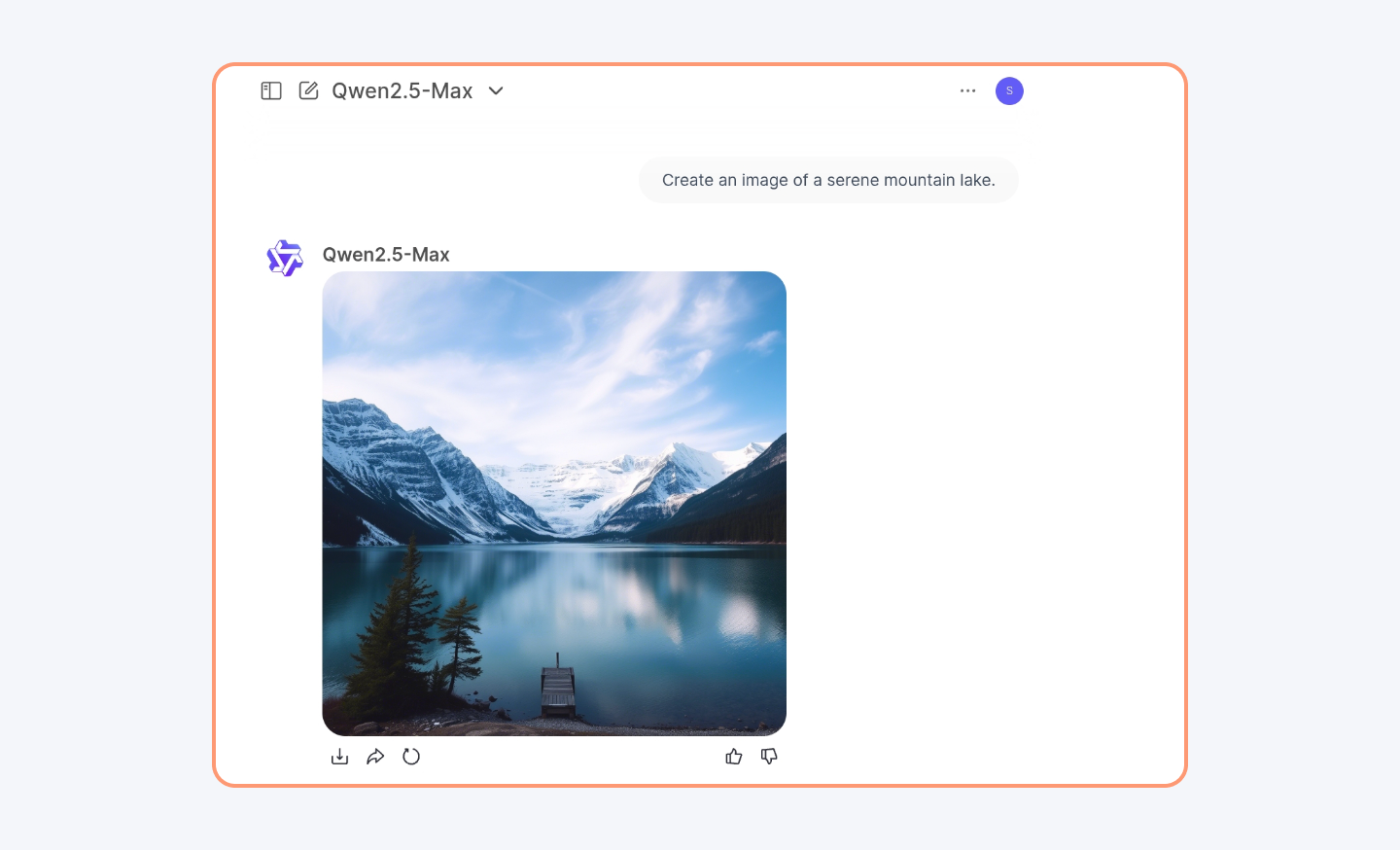
Understands Text, Images, & Video
Unlike some AI models that are just text-based, Qwen3-Max is multimodal. That means it can analyze images, process audio, and even understand video content.
It can easily create an image with any prompt you provide.
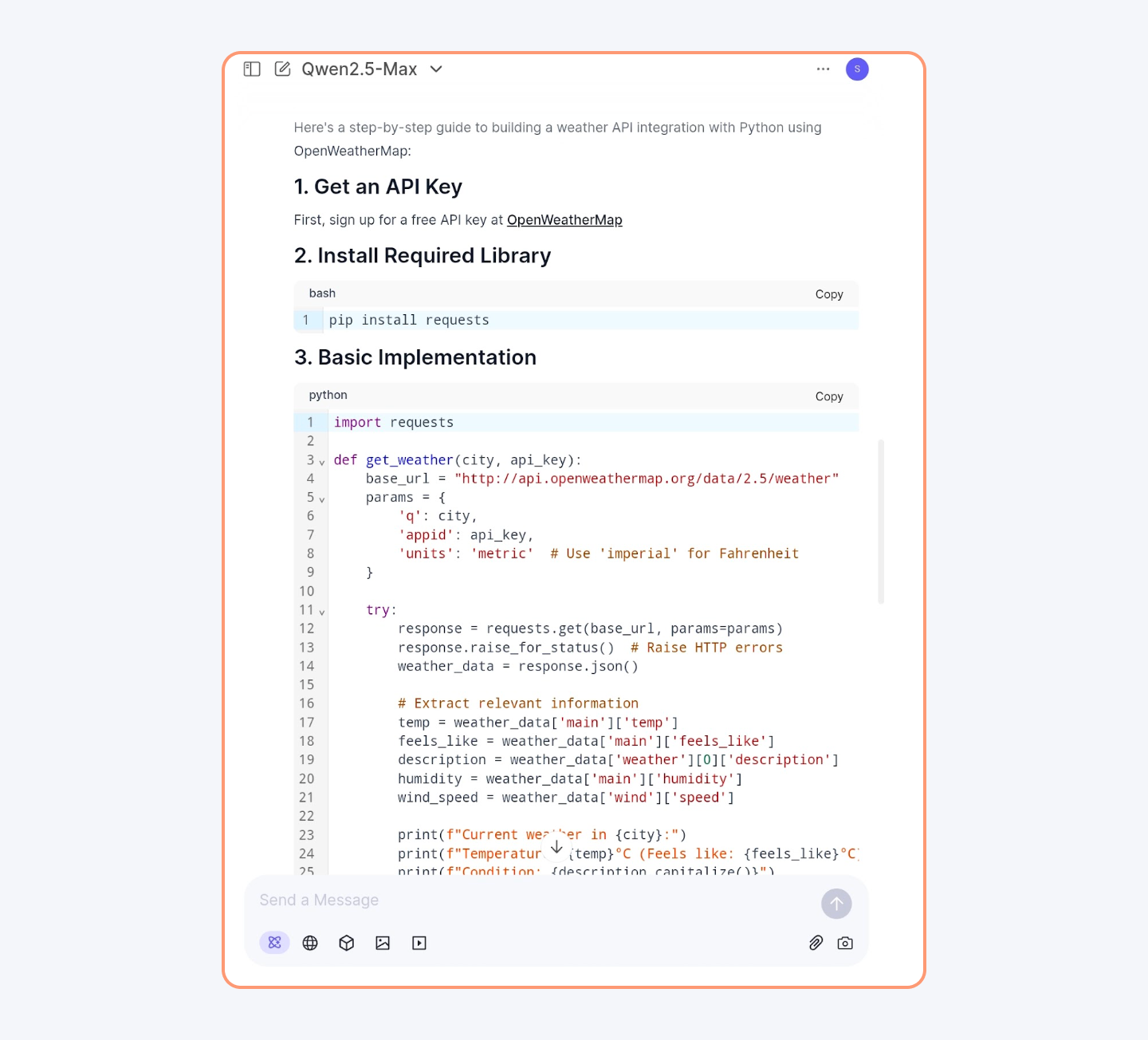
This LLM is so efficient in logical thinking that it can generate proper Python code with your instructions.
Cost Efficiency
Qwen3-Max is one of the more cost-effective frontier models available in 2026. Alibaba Cloud lists input tokens around $1.20 per million and output tokens around $6.00 per million, well below GPT-5.1 and Claude Sonnet 4.6 for similar quality.
| AI Model | Cost ($) |
| GPT-4o | 5.00 |
| Claude 3.5 Sonnet | 3.00 |
| Qwen 2.5-Max | 0.38 |
| DeepSeek V3 | 0.25 |
Qwen3-Max achieves this cost efficiency using its Mixture-of-Experts (MoE) architecture, which reduces computational costs by 30% compared to traditional dense models.
Performance
Here’s how Qwen 2.5-Max performs compared to leading AI models like GPT-5.1, Claude Sonnet 4.6, and DeepSeek V3.2:
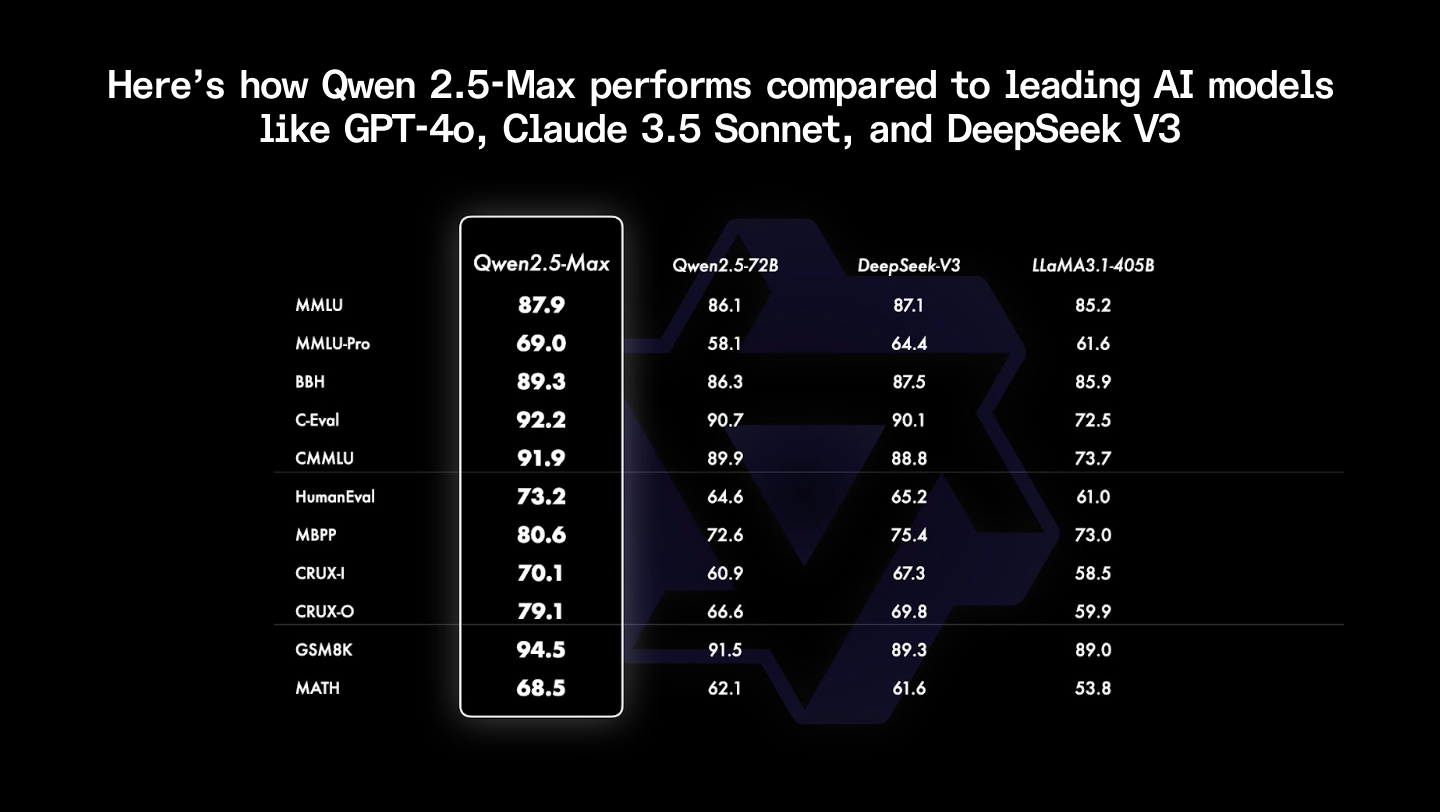
- Arena-Hard (User Preference Alignment): Qwen3-Max scores 90.5, ahead of DeepSeek V3.2 (87.1) and Claude Sonnet 4.6 (86.4).
- MMLU-Pro (Knowledge and Reasoning): It scores 81.2, surpassing DeepSeek V3.2 (80.4) and matching Claude Sonnet 4.6 (81.0).
- LiveCodeBench & HumanEval (Coding Ability): Qwen3-Max-Coder reaches 74.1 on LiveCodeBench v6 and 95.4% on HumanEval, outperforming GPT-5.1 and DeepSeek V3.2.
- LiveBench (Overall AI Tasks): Qwen3-Max leads with 70.3, exceeding DeepSeek V3.2 (67.8) and Claude Sonnet 4.6 (68.1).
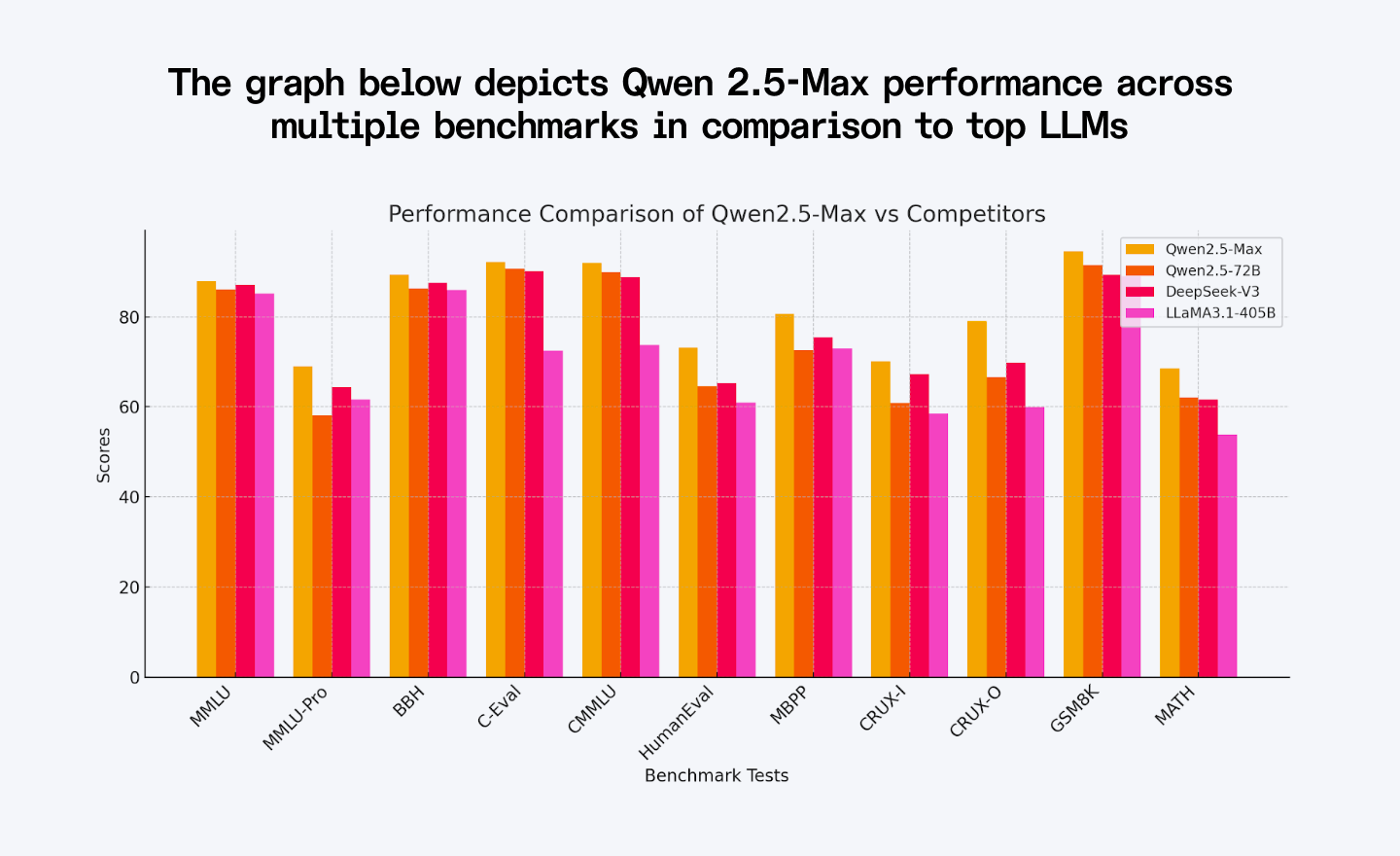
The graph below depicts the Qwen 2.5-Max baseline performance across multiple benchmarks; Qwen3-Max improves on every one of these scores.
3. Doubao Seed 1.6 (Doubao 1.6 Pro)
Developer/founder(s): ByteDance
Founded in: 2025 (Doubao Seed 1.6 release; ByteDance, June 2025)
What it is: Doubao Seed 1.6 (also marketed as Doubao 1.6 Pro) is ByteDance’s flagship AI model with deep thinking abilities. It addresses long context understanding and balances computational efficiency with accuracy, and it is now the engine behind Doubao’s consumer app, Volcengine APIs, and the Cici assistant.
Key features
Sparse Mixture-of-Experts (MoE) architecture:
It activates only a fraction of parameters per operation, reducing computational costs while maintaining high performance. Seed 1.6 outperforms dense models with seven times the activation parameters and ranks among the top open-weight Chinese models in 2026.
Multimodal capabilities:
It supports text, vision, and speech for diverse applications. Doubao Seed 1.6 improves document recognition, fine-grained visual understanding, and adds native video reasoning.
Advanced deep thinking & reasoning:
Doubao Seed 1.6 uses reinforcement learning (RL) to enhance logical and analytical capabilities. The "thinking" variant performs well in complex problem-solving and competition-level math.
Heterogeneous system design
Its heterogeneous system design is suitable for pre-fill decode and attention FNN tasks, optimising throughput and minimising latency.
Extended context window
It can process up to 256,000 tokens in a single pass, suitable for legal document analysis, academic research, and customer service.
Cost Efficiency
Doubao Seed 1.6 is roughly 5 times cheaper than DeepSeek on equivalent workloads and dramatically cheaper than OpenAI’s o3 and GPT-5.1. Doubao Seed 1.6 uses a server cluster that supports lower-end domestic chips, reducing infrastructure costs.
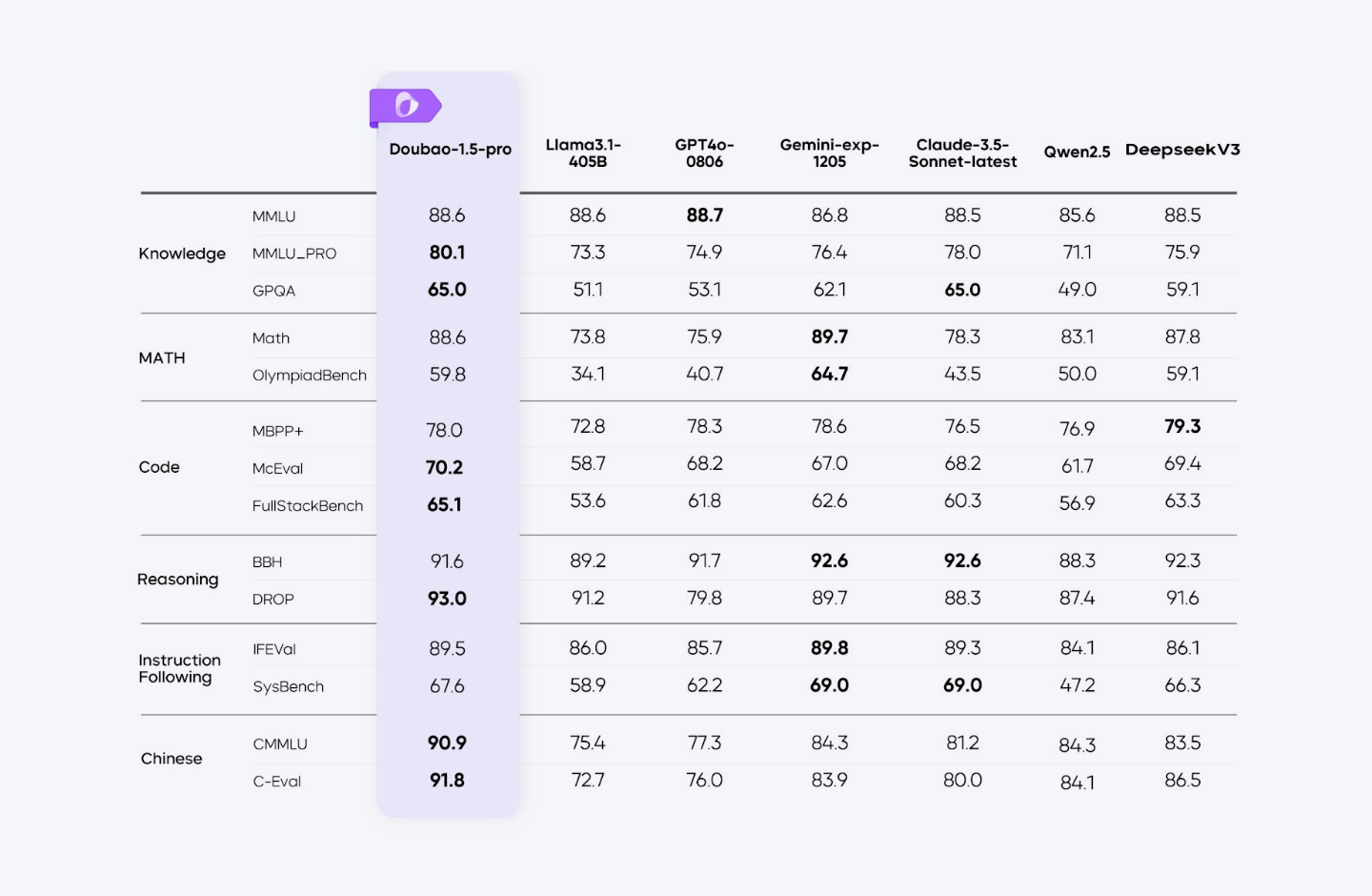
Performance
Doubao Seed 1.6 matches or surpasses models like GPT-5.1 and Claude Sonnet 4.6 in various benchmarks, demonstrating robust capabilities in language understanding and generation tasks.
Some of the area where it performs the best are:
- DROP (93.6): Excels in reading comprehension and reasoning.
- BBH (92.4): High performance in complex reasoning tasks.
- CMMLU (91.5) & C-Eval (92.1): Strong results in Chinese language understanding.
- IFEval (90.8): High proficiency in instruction following.
Here's how Doubao Seed 1.6 performs in comparison to other tools:
4. Kimi (Kimi K2 / Kimi K2 Thinking)
Developer/founder(s): Moonshot AI
Founded in: 2023 (Kimi K2 released July 11, 2025; Kimi K2 Thinking released November 6, 2025)
What it is: Kimi K2 is a 1-trillion-parameter Mixture-of-Experts model (32B active) from Moonshot AI, with the newer K2 Thinking variant adding interleaved tool use and long-horizon reasoning. Unlike DeepSeek V3.2 and the R-series, which lean primarily on reasoning, Kimi K2 is built as a frontier "agentic" model that handles complex problems across mathematics, coding, browsing, and multimodal reasoning.
Key features
Long-Context Processing (256K Tokens)
Kimi K2 Thinking can process large amounts of text (up to 256,000 tokens) in a single pass, making it ideal for analyzing books, research papers, and lengthy reports.
Enhanced Policy Optimization
It employs an advanced policy optimization technique called online mirror descent for the reasoning loop, ensuring stable decision-making across long chains of thought.
Multimodal Integration
Kimi K2 can process both text and images together, enabling it to analyze charts, graphs, and visual data. This makes it particularly useful for applications like medical imaging and financial data interpretation.
The diagram below shows how the tool analyses an image and solves a puzzle. It provides the entire logic behind the solution.
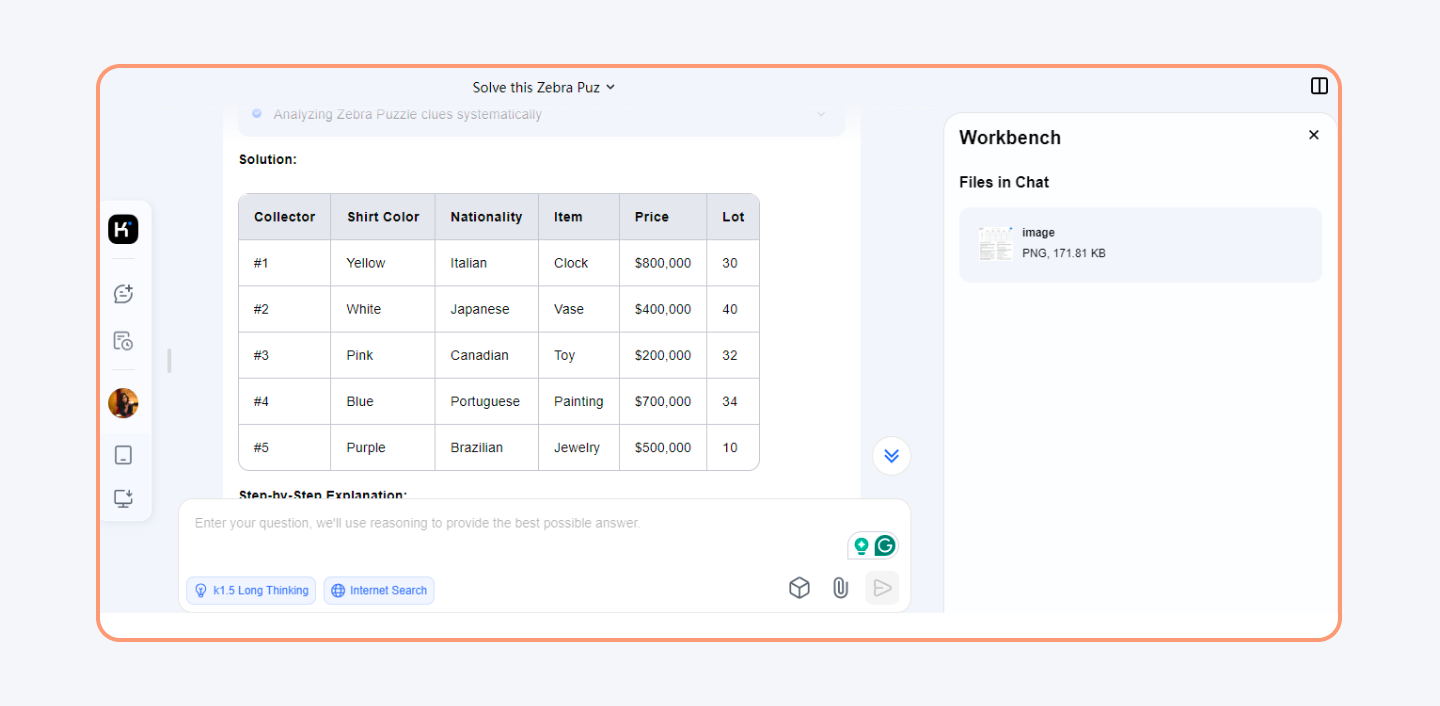
Enhanced Chain of Thought (CoT) reasoning: Kimi K2 Thinking strings together 200 to 300 sequential tool calls without human help, with detailed and concise reasoning modes that improve problem-solving abilities.
Here is how Kimi K2 solves logical problems in seconds.
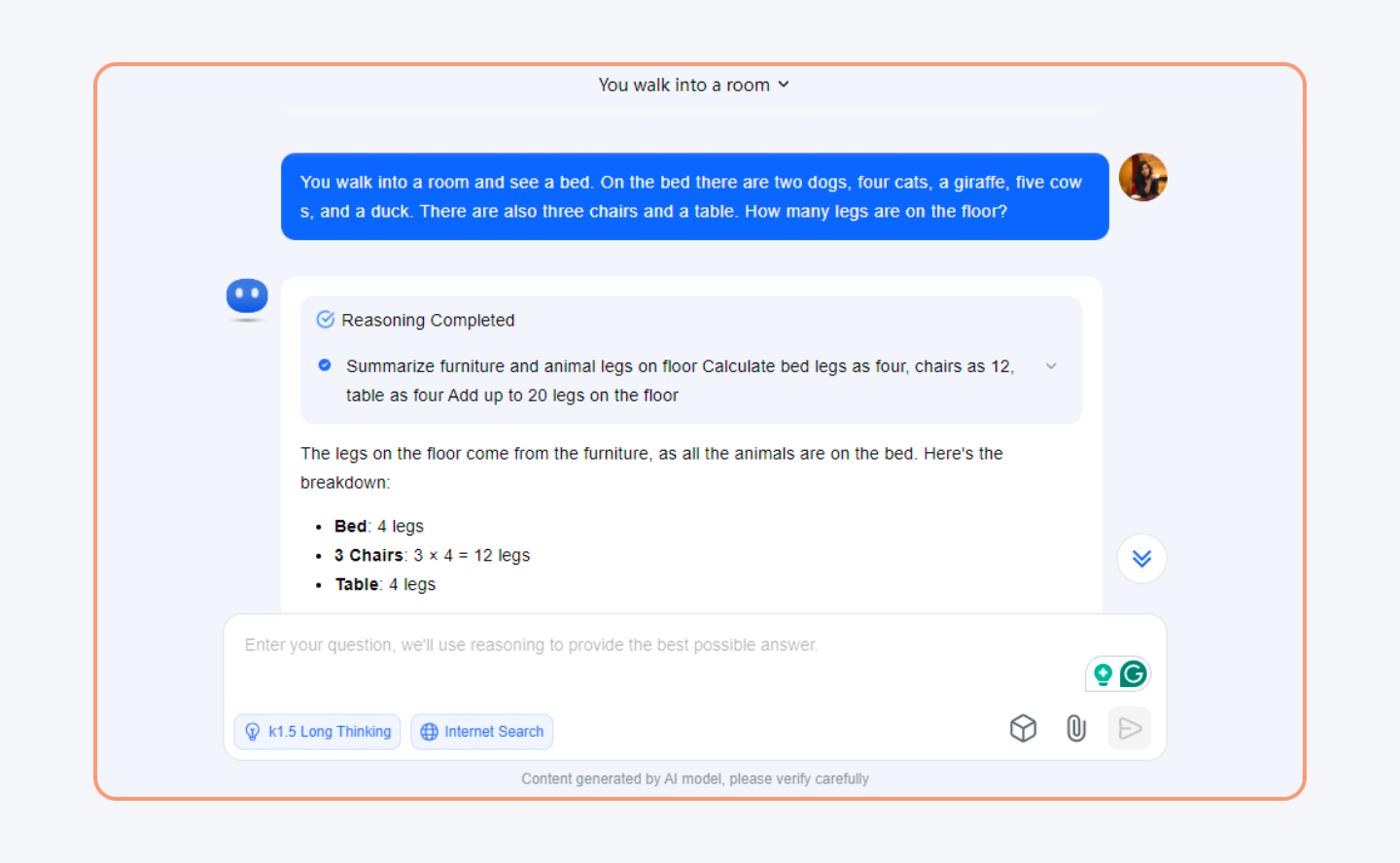
Parallel Computing Infrastructure
It employs three-way parallel computing—pipeline, expert, and tensor parallelism—to optimize speed and efficiency. This allows it to process large-scale computations across thousands of GPUs.
Cost Efficiency
Kimi K2 is open-weight under a permissive license, and the hosted API is priced at roughly $0.60 per million input tokens and $2.50 per million output tokens, undercutting GPT-5.1 and Claude Sonnet 4.6 on cost.
Performance
Kimi K2 Thinking excels in text, reasoning, and vision benchmarks. The long-CoT model enhances long-term reasoning via supervised fine-tuning and reinforcement learning.
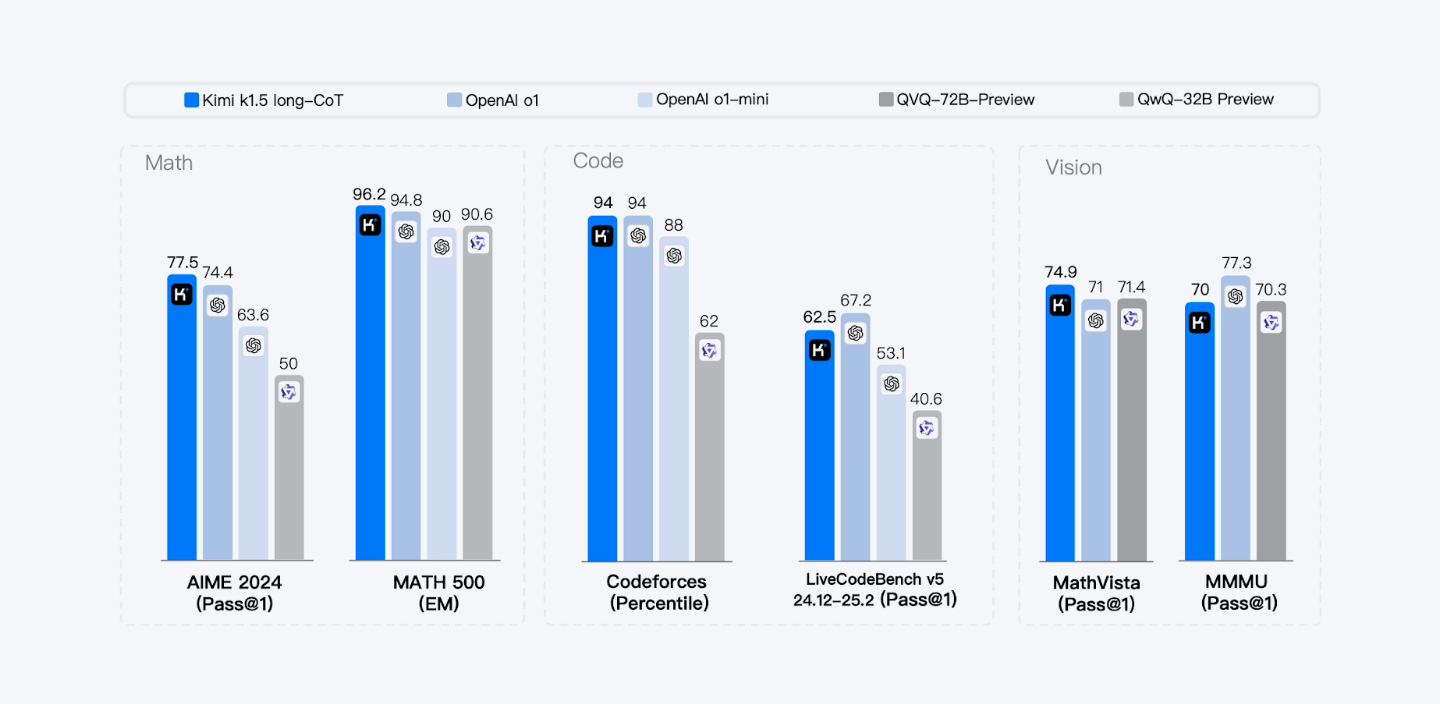
The short-CoT model optimizes token efficiency, while Kimi K2 Thinking achieves 44.9% on Humanity’s Last Exam (HLE) with tools, outperforming GPT-5.1 and Claude Sonnet 4.6 on agentic search, AIME 2025, and LiveCodeBench v6.
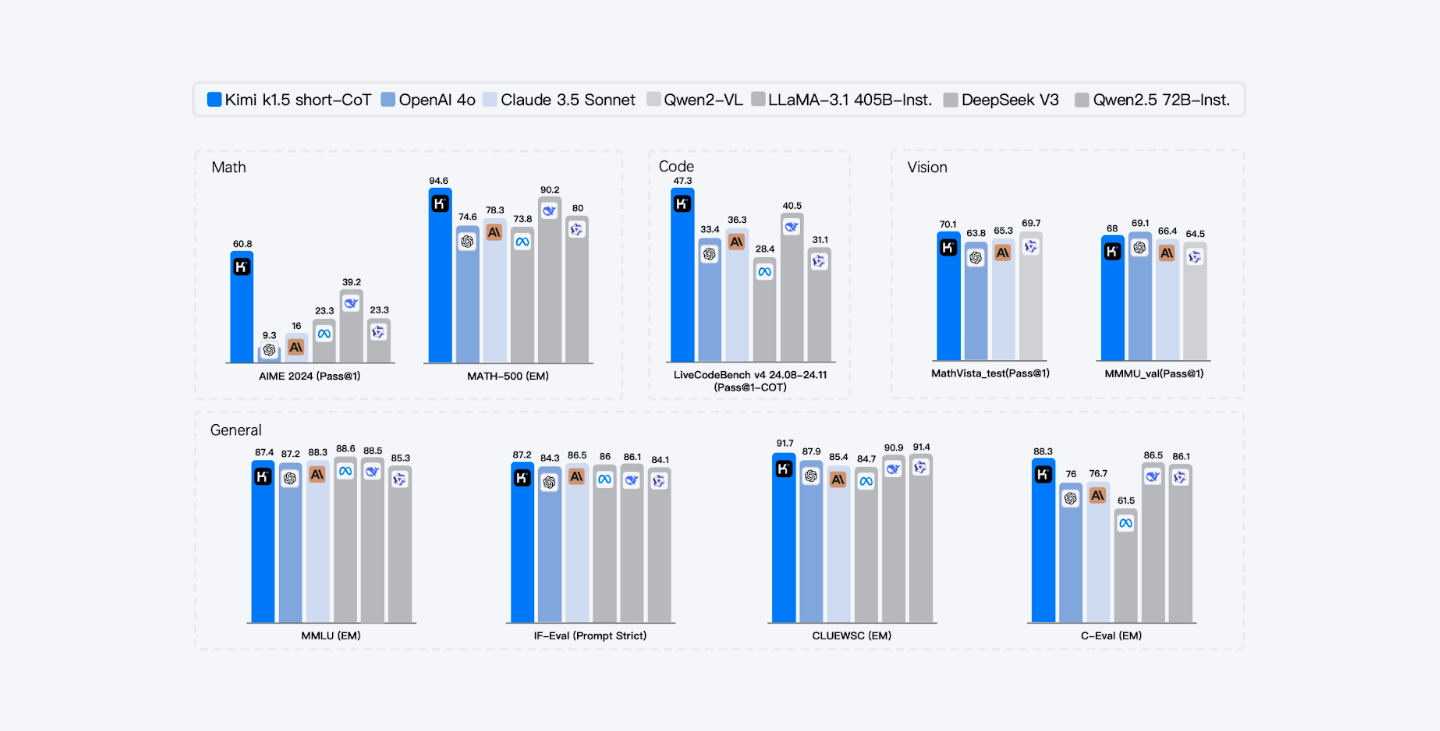
Kimi K2 Thinking achieves leading results in MATH-500, AIME 2025, HLE, and BrowseComp, demonstrating state-of-the-art agentic and reasoning capabilities across diverse tasks.
5. GLM-4.6 (ChatGLM)
Developer/founder(s): Zhipu AI
Founded in: 2024 (Zhipu AI; latest release: GLM-4.6, October 2025)
What it is: GLM-4.6 is Zhipu AI’s latest flagship model, offering significant improvements in agentic abilities, advanced reasoning, and code generation over GLM-4-Plus. It uses Proximal Policy Optimization (PPO) for better performance in mathematical and coding tasks. The model competes with top-tier AI like Claude Sonnet 4.6 and supports multi-modal interactions, with the GLM-4.5V variant adding vision.
Key features
Advanced Conversational Abilities
The GLM-4.6 model and the open-weight GLM-4.5-Air variant support multi-round conversations, ensuring more natural and coherent interactions. They can maintain long discussions while understanding context effectively.
Powerful Tool Integration
This model can browse the web, execute code, make custom tool calls (Function Call), and process long text reasoning with native support for up to 200,000 tokens.
Multilingual Capabilities
GLM-4.6 supports more than 30 languages, including Japanese, Korean, and German. This makes it more accessible to a global audience.
Extended Context Length
GLM-4.6 lifts the native context window to 200,000 tokens, while the GLM-4-9B-Chat-1M variant still handles up to 1 million tokens for extremely long documents.
Advanced Multimodal Understanding
GLM-4.5V can generate and analyze high-resolution images (1120×1120) while maintaining strong conversational abilities in both Chinese and English.
PPO Optimization
Proximal Policy Optimization (PPO) enhances its ability to solve mathematical and coding tasks efficiently.
Cost Efficiency
| Feature | Cost Efficiency of GLM-4, ChatGLM |
| Free to Use | Open-source, no license fees. Companies can use it for free. |
| Cheaper to Train | Training ChatGLM-6B cost $1.5M, while GPT-3 cost $4.6M. Uses fewer GPUs (1,000 vs. 5,000). |
| Runs on Smaller Computers | Works on cheaper GPUs with as little as 6GB memory, reducing hardware costs. |
| Faster and More Efficient | 42% faster than older models and uses less power, cutting cloud and energy costs. |
Performance
Language Capabilities: GLM-4.6 performs at the level of top-tier models like Claude Sonnet 4.6, excelling in reasoning tasks such as mathematics and code algorithms.
It demonstrates roughly 100% to 105% efficiency compared to models like Claude Sonnet 4.6 and GPT-5.1 in benchmarks like AlignBench, MMLU-Pro, and MATH.
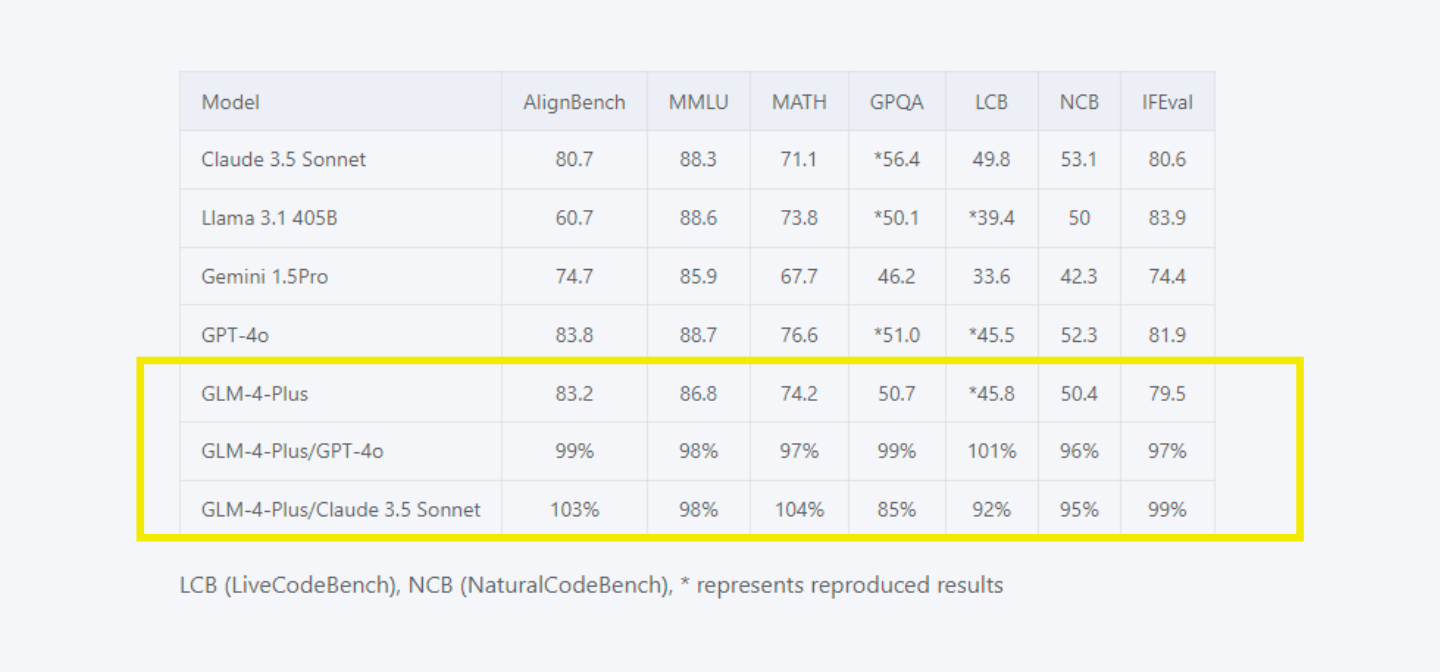
Long Text Processing: The model efficiently handles long text reasoning, matching Claude Sonnet 4.6 and surpassing GPT-5.1 on InfiniteBench/EN.MC. It ensures better comprehension of extended content.
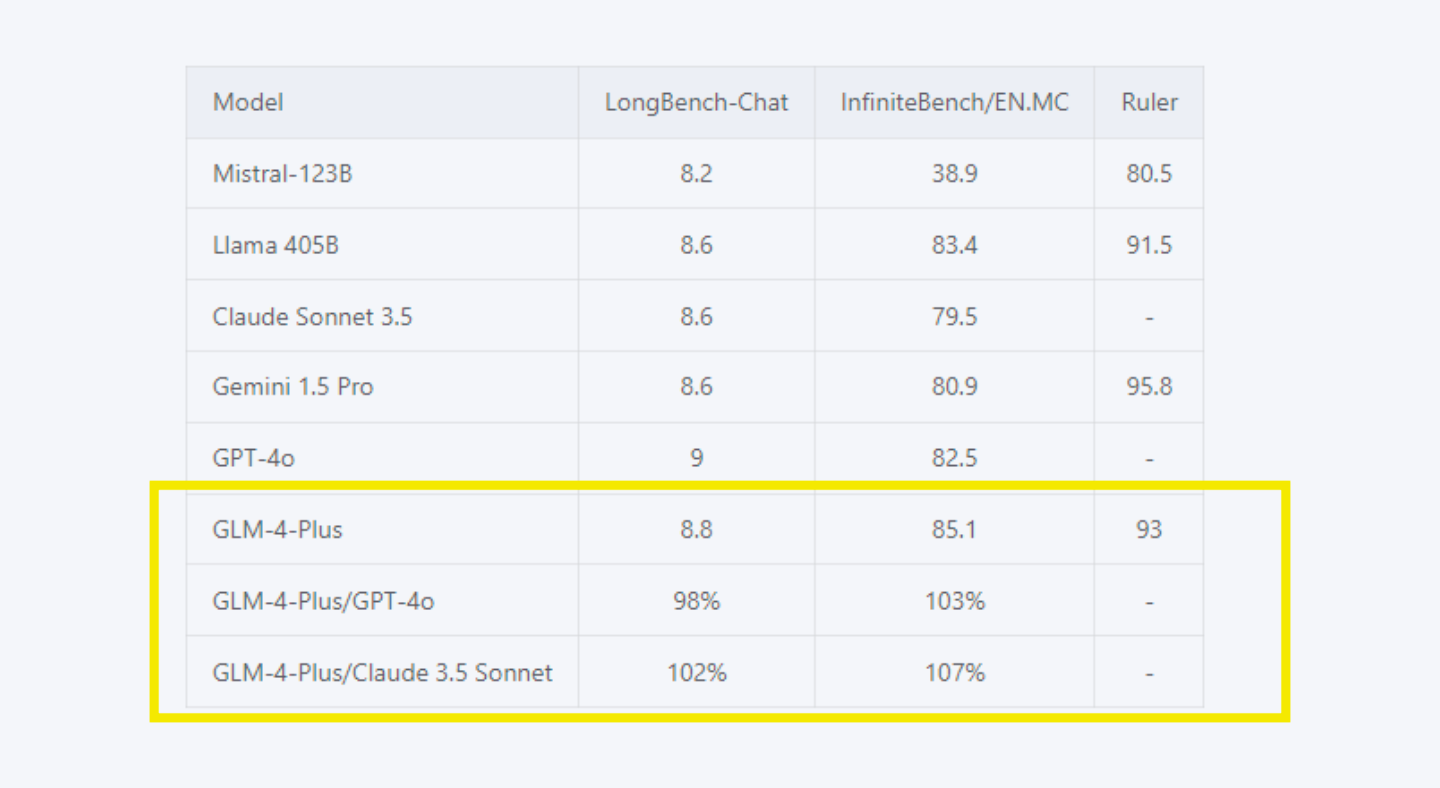
6. WuDao 3.0
Developer/founder(s): Beijing Academy of Artificial Intelligence (BAAI)
Founded in: 2023 (Aquila2 update released 2024; lineup maintained by BAAI through 2026)
What it is: WuDao 3.0 is a collection of smaller, dense, open-source large language models (LLMs) under the name Wu Dao Aquila, designed to enable Chinese startups and smaller entities to build their own generative AI applications. The Aquila2 update added stronger bilingual reasoning and remains popular with research teams in 2026.
Key features
Multilingual support
It understands and processes both Chinese and English, making it useful for a wide range of users.
Multimodal capabilities
WuDao 3.0 can process both text and images, enabling applications in chatbots, content creation, and image analysis.
AquilaChat Dialogue Model
WuDao 3.0 includes AquilaChat, a powerful dialogue model that enables fluent and natural conversations in multiple languages, including Chinese and English.
AquilaCode for Code Generation
The model can generate code from text inputs, making it useful for developers looking to automate programming tasks or assist in software development.
Advanced Visual Processing
WuDao 3.0 supports multimodal AI, allowing it to generate images from text descriptions and understand visual content, making it useful for applications in design and media.
Cost Efficiency
WuDao 3.0's smaller, dense models are more cost-efficient compared to larger models like WuDao 2.0. It uses a sparse model approach, activating only a subset of parameters during inference.
This makes WuDao 3.0 a cost-effective choice for startups and growing businesses. Its open-source model removes licensing fees, and teams can work with a custom software development company to adapt the technology to their specific goals. This helps align the tools with real business needs while keeping performance high and systems scalable.
Performance
| Feature | Wu Dao 2.0 | GPT-3 |
| Parameters | 1.75 trillion | 175 billion |
| Training Data Size | 4.9 TB | 570 GB |
| Languages | English + Chinese | English only |
| Modality | Text + Image | Text or Image |
| Codebase | Open-source (PyTorch) | Closed-source (Microsoft) |
- Zero-Shot Learning: Outperformed OpenAI’s CLIP on ImageNet and UC Merced Land-Use classification.
- Few-Shot Learning: Beat GPT-3 in SuperGLUE (FewGLUE).
- Knowledge & Language Understanding: Retrieved factual knowledge better than AutoPrompt (LAMA) and surpassed Microsoft Turing-NLG in reading comprehension (LAMBADA).
- Text-Image Tasks: Generated better images from text than OpenAI’s DALL·E and outperformed CLIP & Google ALIGN in image-text retrieval (MS COCO).
Comparison of top Chinese AI models LLMs
| Feature | DeepSeek-V3 | Qwen 2.5-Max | Doubao 1.5 Pro | Kimi k1.5 | GLM-4 Plus | WuDao 3.0 |
| Architecture | MoE (671B parameters, 37B active) | MoE (30% more efficient) | Sparse MoE | Parallel computing infrastructure | PPO technology | Collection of smaller, dense models |
| Context Length | 128K tokens | 128K tokens | 256K tokens | 128K tokens | 128K tokens (1M for GLM-4-9B-Chat-1M) | Not specified |
| Multimodal | No | Yes (text, images, video) | Yes (text, vision, speech) | Yes (text, images, video) | Yes (high-res images) | Yes (text, images) |
| Cost Efficiency | $0.25 per million tokens; $5.6M training cost | $0.38 per million tokens; 30% reduced computational cost | 5x cheaper than DeepSeek; 200x cheaper than OpenAI's O1 | Lower development costs | Open-source, $1.5M training cost (for GLM-6B) | Open-source, reduced GPU and energy costs |
| USP | Multi-token prediction, Multi-head latent attention, Excel in coding and math | Trained on 20T tokens, Strong in reasoning & coding, Multimodal processing | Heterogeneous system design, Advanced deep thinking, Strong in Chinese language | Enhanced Chain of Thought reasoning, Advanced policy optimization, Math problem-solving | 26 languages support, Tool integration, 1M token version available | Multilingual (Chinese/English), AquilaChat dialogue model, AquilaCode generator |
| MMLU Score | 88.5 | 85.3 | Not specified | Not specified | Comparable to GPT-4o | Not specified |
| Math/Reasoning | MATH-500: 90.2 | MMLU-Pro: 76.1 | DROP: 93.0<br>BBH: 91.6 | Outperforms GPT-4o on AIME, MATH-500 | 99-104% efficiency vs. GPT-4o | Outperformed GPT-3 in SuperGLUE |
| Coding Ability | Codeforces: 51.6 | LiveCodeBench: 92.7% | Not specified | Outperforms GPT-4o on LiveCodeBench | Excel in coding algorithms | Code generation capabilities |
Final words
Chinese AI models are catching up fast with popular Western AI like GPT-5.1 and Claude Sonnet 4.6. Models like DeepSeek-V3.2, Qwen3-Max, and Kimi K2 Thinking offer great value for companies looking to build AI products.
They’re much cheaper but still very smart, perfect for the talented developers you can hire through Index.dev.
When your new tech team starts working on AI projects in 2026, these affordable Chinese models can help them build amazing applications without spending too much money.
This makes Index.dev’s talent network even more valuable for growing your business with AI.
Build your AI team with top developers! Hire vetted experts through Index.dev with 48-hour matching and a 30-day free trial. Get started today!
