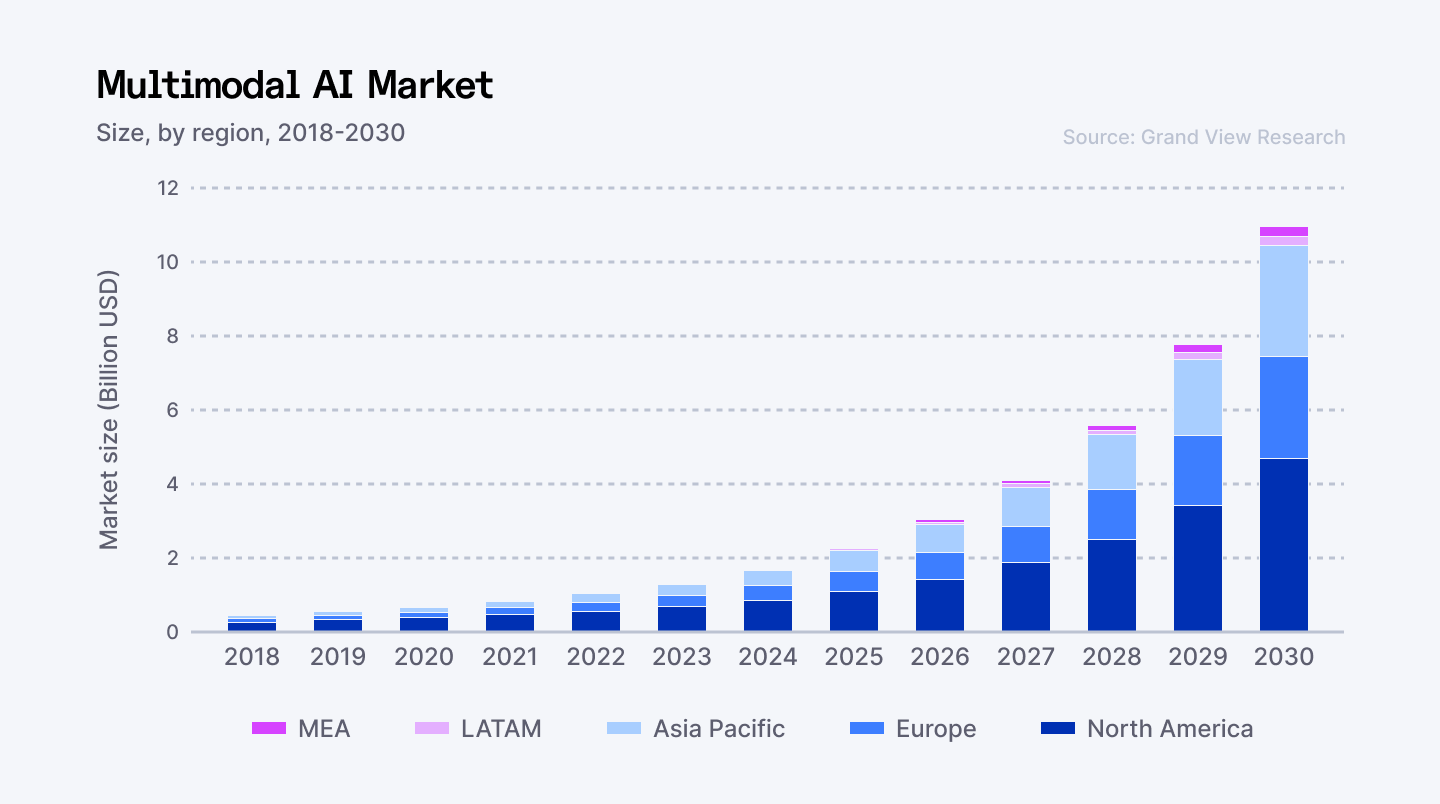
The multimodal AI market recently reached $2.51 billion in 2025 and is expected to reach $42.38 billion in 2034. Companies utilizing these models have shown considerable efficiency improvements and shorter development cycles, making this technology essential for competitive advantage. But there’s one major hurdle: most fail at adoption.
If you're building AI features, you need to know which model actually works for your use case. This guide cuts through the noise and tells you exactly what to ship, based on real production data from companies already using these systems.
Supercharge your apps with multimodal AI. Index.dev’s expert developers help you adopt and deploy AI efficiently, turning complex models into real-world solutions.
What Makes Multimodal AI Different?
Multimodal AI processes text, images, audio, and video in a single model. No more duct-taping together three different APIs and praying they work.
Remember building an AI astrology app that had to interpret a birth chart? You’d calculate planetary positions, map houses and aspects, then pass the results through separate rule engines and text generators. Every handoff added complexity, latency, and inconsistencies. Multimodal models eliminate much of that mess: send the birth details, chart image, and user question together, get a structured interpretation back.
Here's what actually changes when you switch: instead of managing separate Whisper instances for audio, CLIP for images, and GPT for text, you make one API call. Companies report cutting their pipeline complexity by half. Support tickets that needed three model calls now need one.
Which Model Fits Your Use Case?
1. GPT-4o
OpenAI built GPT-4o to handle real conversations. We're talking 320-millisecond response times, fast enough that users don't notice the delay. The model processes text, images, and audio without separate preprocessing steps.
Here's what makes GPT-4o different: native audio understanding. Not transcribe-then-process like older systems. The model understands tone, pauses, and emphasis. A support agent built on GPT-4o can detect customer frustration from voice patterns while simultaneously analyzing their screenshot.
Technical reality check
- Context:
- 128K tokens in, 4K out (enough for most conversations, not enough for full documents)
- 128K tokens in, 4K out (enough for most conversations, not enough for full documents)
- Accuracy:
- 88.7% on Massive Multitask Language Understanding (MMLU)—solid but not perfect
- 88.7% on Massive Multitask Language Understanding (MMLU)—solid but not perfect
- Languages:
- Works reliably in 50+ languages without switching models
- Works reliably in 50+ languages without switching models
- Cost:
- $5 per million input tokens (budget accordingly)
- $5 per million input tokens (budget accordingly)
The Azure integration matters more than people realize. You get enterprise SSO, VNet isolation, and compliance certifications out of the box. For regulated industries, that's months of security review avoided.
When to actually use GPT-4o
Your product needs voice + vision + text in real-time. Think customer support that handles screenshots and voice simultaneously. Educational apps where students can point cameras at problems and talk through solutions. Troubleshooting flows where technicians show equipment issues while describing symptoms.
Common mistake
Using GPT-4o for document-heavy workflows. The 4K output limit becomes a bottleneck fast. If you're processing contracts or research papers, look elsewhere.
Explore ChatGPT-5: Hands-on look at the latest AI model
2. Gemini 2.5 Pro

Google built something absurd with Gemini 2.5 Pro: 2 million token context. To put that in perspective, you can feed it an entire codebase, every email from a lawsuit, or two hours of video footage, all at once.
Law firms are using Gemini to review discovery documents. Instead of paralegals searching through thousands of pages, they dump entire case files into the model. "Find every mention of the merger discussion between June and August, including any euphemisms or indirect references." It finds them all, with timestamps and context.
Real capabilities
- Processes 2,000 pages of text simultaneously
- Analyzes 2-hour videos with frame-level understanding
- Maintains context across 19 hours of audio transcripts
- 92% accuracy on benchmarks (highest among commercial models)
The Vertex AI integration gives you more than just the model. You get built-in data pipelines, batch processing, and most importantly—data residency controls. For European companies dealing with GDPR, that's mandatory.
Actual use cases that work
Legal document review where missing one reference costs millions. Research synthesis across hundreds of papers. Video content moderation at scale. Multi-hour meeting transcription with speaker attribution and topic tracking.
The catch
Processing 1M tokens (2M coming soon) costs real money. Each full-context request runs several dollars. Fine for high-value workflows, killer for consumer apps.
3. Claude Opus/Sonnet 4

Anthropic took a different approach with Claude—they optimized for being right over being fast. Claude Opus hits 72.5% on SWE-bench (coding tasks) versus GPT-4o's 30.8%. For visual tasks, it's even more dramatic.
Healthcare companies trust Claude for a reason. The model includes constitutional training that makes it refuse dangerous medical advice consistently. It won't diagnose conditions from symptoms. It won't recommend dosages. It flags when it's uncertain. For liability reasons alone, that's huge.
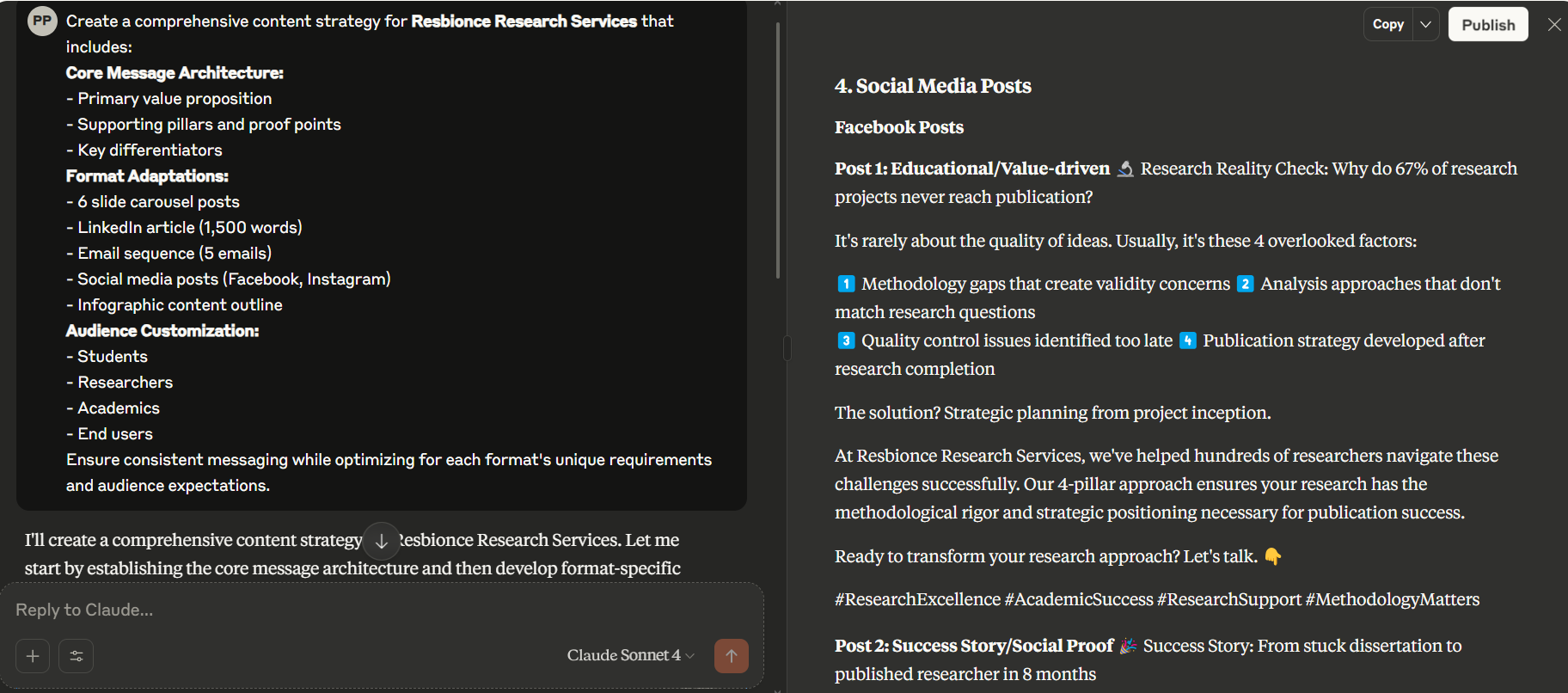
Where Claude excels
- Document extraction with 95%+ accuracy on forms and invoices
- Financial report analysis with built-in skepticism about numbers
- Code review that catches security issues other models miss
- Medical image annotation (with appropriate disclaimers)
The 200K context handles most business documents for you. But the real advantage? Predictable outputs. Claude generates similar responses to similar inputs—critical for auditable workflows.
Implementation that works
Banks use Claude for compliance reporting. Every output gets logged with model version, temperature settings, and input hash. When regulators ask why a transaction got flagged, there's a complete audit trail.
Warning
Claude refuses certain requests other models handle. It won't write marketing copy that makes unverifiable claims. It won't generate code for web scraping without permission checks. Plan for these guardrails.
Discover how Gemini and Claude stack up in coding tasks, from API builds to debugging.
4. AI Grok 3

xAI trained Grok 3 on 200,000 H100 GPUs. That's computational overkill. But the result? A phenomenal model that integrates live data streams better than anything else available.
Grok pulls from X (Twitter) in real-time. Not hourly updates—actual real-time. Hedge funds use it to track market sentiment during earnings calls. News organizations monitor breaking stories. The model understands context: distinguishing between jokes, rumors, and verified information thanks to its DeepSearch feature for transparent reasoning and Big Brain Mode for complex problem-solving.
Unique capabilities
- DeepSearch mode that shows reasoning steps (not just answers)
- 1400 ELO rating on technical problem-solving
- Direct access to trending topics and viral content
- Transparent reasoning paths you can audit
Pricing reality
$40/month for Premium+ or $30/month for SuperGrok. Sounds expensive until you compare it to Bloomberg Terminal at $2,000/month.
Best deployment pattern
Combine Grok with traditional data sources. Use it to catch emerging trends, then verify with established APIs. Financial firms run Grok alerts for unusual social sentiment, then trigger traditional analysis workflows.
See which AI tool comes out on top: Grok 3 or DeepSeek R1 in real-world coding challenges.
5. Llama 4 Maverick
Meta open-sourced Llama 4 Maverick with 400 billion parameters. But here's what matters: you can run it yourself. No API limits. No usage monitoring. No sudden price changes.
The mixture-of-experts architecture means only 17 billion parameters activate per token. Translation: it runs on realistic hardware while performing like a massive model. Companies with spare GPU capacity run Llama for free after initial setup
Why teams actually choose Llama
- Complete control over data (never leaves your infrastructure)
- Customizable for vertical-specific terminology
- No per-token costs at scale
- Works with existing MLOps pipelines
Oracle and Cloudflare offer hosted versions if you don't want to manage infrastructure. But the real value? Fine-tuning on your data. Law firms train Llama on their case history. Biotech companies add proprietary research. The base model becomes yours.
Pick Llama 4 when customization, control and scale matter—especially for vertical assistants or hybrid on-prem deployments. Use Llama 4 for customized domain models where license flexibility and control trump turnkey performance.
Production reality
Budget 8x A100 GPUs minimum for responsive inference. Quantize to FP8 for better throughput. Expect two weeks for proper fine-tuning. The upfront investment pays off at 10M+ tokens/month.
6) Phi-4 Multimodal

Microsoft's Phi-4 runs on phones. Not cloud-connected phones—actual on-device processing designed for multilingual and hybrid use. At 5.6 billion parameters, it fits in mobile memory while handling text, image, and audio inputs.
Manufacturing companies deploy Phi-4 on production lines. Cameras detect defects, microphones monitor equipment sounds, all processed locally. No internet dependency. No data leaving the facility. Latency measured in milliseconds, not seconds.
Edge-first capabilities
- 6.14% word error rate for speech (beats WhisperV3)
- Runs on Snapdragon chips without modification
- Processes 25+ languages for text, 8 for audio
- 128K token context fits most edge scenarios
The real innovation? Mixture-of-LoRAs architecture. Different lightweight adapters handle different languages and modalities. The base model stays small while capabilities expand.
Actual deployments
Retailers run Phi-4 in stores for inventory checks. Hospitals use it in ambulances for initial triage. Construction sites deploy it for safety monitoring.
No cloud dependencies mean it works in tunnels, rural areas, anywhere. Its low resource requirements make it cost-effective for businesses seeking high-performance multimodal AI without heavy computational overhead.
7. Sora

OpenAI's Sora generates short-form (up to ~20-60 sec depending on UI/tier) videos from text. Before you get excited—these aren't Pixar quality. They're prototypes for testing ideas quickly by converting text and image seeds into short, animated video clips.
Marketing teams use Sora to rough out commercial concepts. Instead of storyboards, they generate actual video clips in minutes. It’s not a full production studio yet; but you can use Sora to iterate concepts quickly. The creative director sees movement, timing, transitions—impossible with static boards. Then professional editors create the real version.
Practical limitations
- 20 to 60-second maximum length video clips (no feature films)
- Visible watermarks on all outputs
- Inconsistent character appearance between scenes
- Physics occasionally breaks in obvious ways
Workflow that works
Generate 20 variants of a concept. Show stakeholders actual moving footage, not descriptions. Pick the winner. Hand to production team with clear direction. You've compressed weeks of back-and-forth into hours.
Cost consideration
Each video generation costs tokens. Iterating through dozens of concepts adds up. Budget for experimentation, not just final outputs.
8. EduBrain
EduBrain is an AI platform for education and content support from basic homework to polished writing. It accepts text, images, PDFs, or formulas and turns them into answers that explain concepts step by step. The platform EduBrain handles homework from math and science to history and code. It also includes tools for diagrams, flashcards, and structured notes.
Interactive visual tools generate diagrams, flowcharts, pie charts, and mind maps to make complex material clearer. Presentations come from the AI PPT generator, which builds ordered slides from your topic and key points. An AI answer generator adapts solutions to your chosen style, from quick results to detailed walkthroughs.
EduBrain’s built-in AI detector checks text for machine-generated content before submission. A humanizer tool refines robotic writing into natural, readable text that fits academic style guidelines. You can refine answers, ask follow-ups, and adjust explanations until clarity improves.
Real capabilities
- Handles homework across subjects with image and text inputs.
- Generates visual diagrams, mind maps, flowcharts, and timelines.
- Creates presentations and study materials from raw notes.
- Checks if text looks AI-generated with an AI detector.
- Humanizes rough AI output into natural writing.
Practical benefits
- Users get step-by-step reasoning instead of vague summaries.
- The model points out gaps in understanding and suggests specific next steps.
- The interface stays clean, so beginners do not feel overwhelmed.
Which Model Should You Choose?
You need to pick your AI primary on modality and governance. Before diving into specific models, consider these critical factors:
- Primary modality requirements:
- Does your application primarily handle images, audio, video, or mixed inputs?
- Context length needs:
- Are you processing short interactions or multi-document analysis?
- Deployment constraints:
- On-premises, cloud-only, or hybrid requirements?
- Compliance requirements:
- Regulated industries need specific safety and auditability features.
- Cost sensitivity:
- Balance between performance and operational expenses.
- Customization needs:
- Open-source flexibility versus managed service convenience.
The decision matrix table near the end maps concrete use cases and technical specifications.
Making the Right Choice (Decision Matrix)
Forget the marketing. Here's how you actually pick:
Start with constraints
- Regulated industry? → Claude (audit trails) or on-premise Llama
- Real-time required? → GPT-4o or Phi-4 (edge)
- Massive documents? → Gemini 2.5 Pro
- Live data needed? → Grok 3
- Video generation? → Sora (with human polish)
Then validate with real data
Run 200 actual user inputs through your top choice. Measure what matters: accuracy on your specific task, latency for your users, cost at your scale. Marketing benchmarks don't predict production performance.
Model | Modalities | Best for | Open / Closed | Risk level | Cost tier | Recommended deployment |
| GPT-4o (OpenAI) | Text, Image, Audio | Real-time chat, visual support, voice assistants | Closed | Medium | Higher (managed API) | Cloud (ChatGPT/Azure) with RAG + citation checks |
| Gemini 2.5 Pro (Google) | Text, Image, Video | Long-document legal/research, video/audio analysis | Closed | Medium | High (enterprise cloud) | Google Cloud / Vertex AI; use managed endpoints for governance |
| Claude Opus / Sonnet (Anthropic) | Text, Image | Safety-sensitive enterprise assistants (health, finance) | Closed | Low-Medium | Medium–High | Hosted API (Bedrock/partners) + strict logging & H-in-loop |
| Grok 3 (xAI) | Text, Image, Web streams | Real-time knowledge integration, social feed + web-augmented assistants | Closed | Medium-High | Medium | Cloud / platform-integrated; lock trusted domain retrieval and provenance |
| Llama 4 Maverick (Meta) | Text, Image | Custom vertical assistants, large-scale multimodal workloads | Open / Community license | Medium | Medium (deploy cost-optimized MoE) | Hybrid: cloud or on-prem; MoE tuning and quantized FP8/BF16 |
| Phi-4 Multimodal (Microsoft) | Text, Image, Audio | Multilingual, on-device / hybrid, edge apps | Open / Hybrid | Medium | Low–Medium (efficient) | Hybrid/edge-first: Azure + on-device runtimes |
| Sora (OpenAI) | Text → Video (also image seeds) | Marketing prototyping, storyboards, social clips | Closed | Medium-High (creative risk & policy) | Medium (creative API) | Cloud (managed); use for prototypes only, human polish required |
Conclusion
The multimodal shift is happening whether you participate or watch. Companies implementing now report efficiency gains that compound monthly. The question isn't whether to adopt, it's how fast you can ship something that matters.
Choose a model. Run real tests. Deploy behind flags. Measure everything. Scale what works.
Need developers who understand multimodal AI inside-out?
Index.dev connects you with the top 5% of AI-specialized developers in 48 hours. Get matched with experts who've shipped GPT-4o, Gemini, and Claude integrations. Start your 30-day free trial.
