In this era of Artificial Intelligence, developers are always looking for innovative approaches to improve language model performance. The Retrieval-Augmented Generation (RAG) has come out as an innovative and revolutionary strategy. Imagine a language model that can produce human-like writing while also being able to access a massive database in real time and intelligently incorporate that data into its responses.
This hybrid model promises previously unheard-of accuracy and relevance by combining the generative power of sophisticated neural networks with the depth and precision of retrieval processes. We shall examine the specifics of RAG LLM in this guide. Because of its potential to completely change how engineers use AI for knowledge discovery and issue-solving, this technology will surely captivate and thrill engineers.
Find high-paying, long-term remote generative AI jobs with top US, UK, and EU companies at Index.dev. Join now!
What is LLM?
An advanced artificial intelligence that can comprehend and produce human language is called a Large Language Model (LLM). These models are trained on enormous volumes of text data and are constructed using deep learning techniques, namely neural networks with numerous layers (hence "large").
With the help of this training, LLMs may produce prose with great fluency and coherence, respond to inquiries, translate across languages, summarise documents, and carry out other language-related tasks. Google's BERT, OpenAI's GPT-3 and GPT-4, and numerous others are examples of LLMs. Their ability to pick up on the subtleties and intricacies of human language comes from their considerable training.
Read more: What is a Large Language Model? Everything you need to know!
Advantages:
- Capable of performing a wide range of language-related tasks with high accuracy.
- Continuously improving with advancements in AI research and larger training datasets.
Limitations:
- Knowledge is static and limited to the information available during training.
- Can produce incorrect or nonsensical outputs if the input is ambiguous or misleading.
- May require significant computational resources for training and operation.
Read more: 7 Best-Paying Tech Skills Companies Are Hiring for Now
What is RAG?
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models by incorporating facts from external sources.
LLMs are essentially neural networks characterized by the number of parameters they contain. These parameters represent human language patterns, enabling LLMs to generate coherent and contextually appropriate responses to general prompts at incredible speeds. However, traditional LLMs can fall short when diving deeper into current or highly specific topics because they rely solely on their pre-existing, parameterised knowledge.
RAG addresses this limitation by combining LLMs' generative capabilities with a retrieval system that pulls relevant information from external, up-to-date resources. Lewis and his colleagues from Meta AI, University College London, and New York University developed this concept, which is described as “a general-purpose fine-tuning recipe.” It allows nearly any LLM to connect with virtually any external resource, enriching the model’s responses with current and specific data.
To understand this in a more easy way, let's take an example. Imagine you're an engineer working on a complex project and need specific information about the latest industry standards. Instead of sifting through numerous documents and websites, you could use a RAG-augmented AI model. This model would instantly retrieve the most relevant and recent standards from trusted databases and incorporate that information into a coherent and precise response. This saves time and ensures that you have the most accurate and current information at your fingertips.
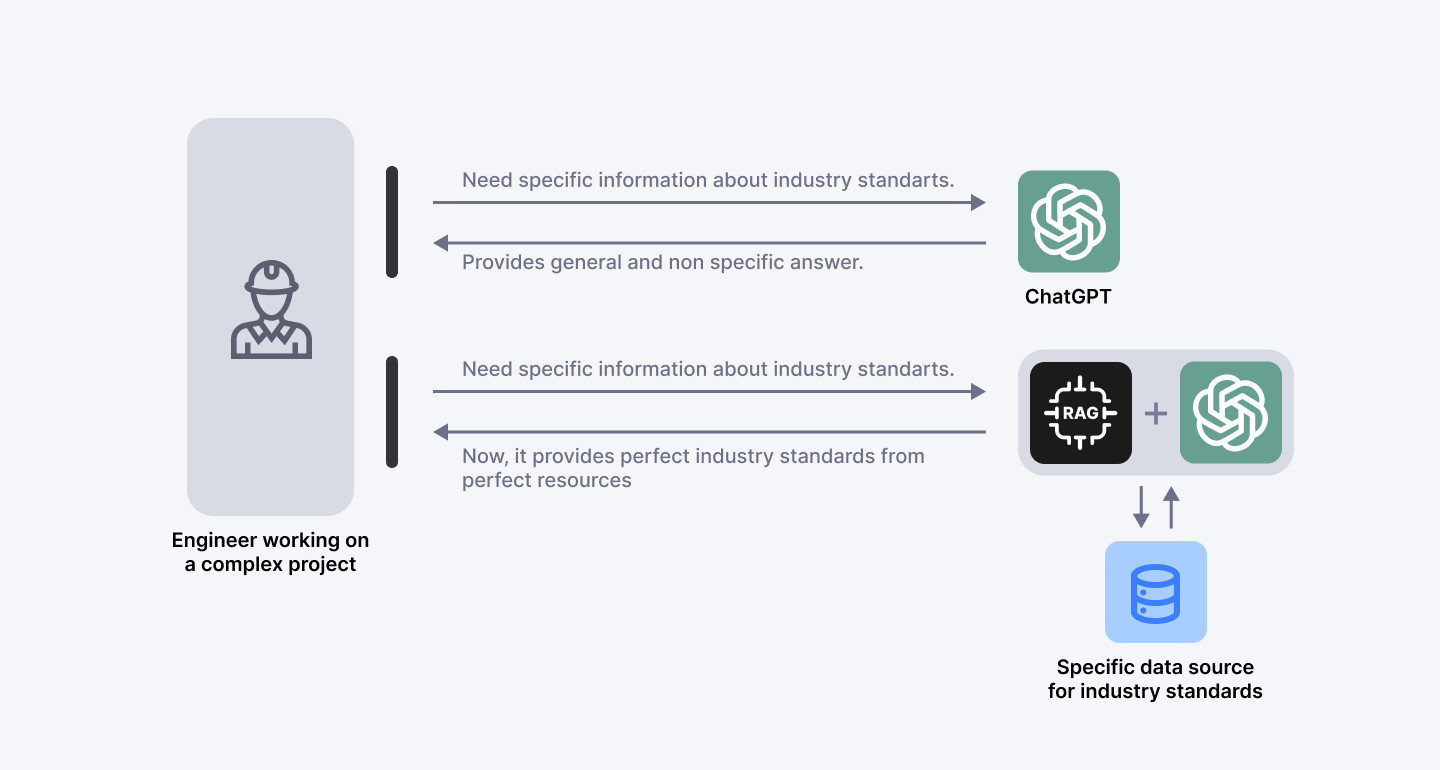
Figure 1: The importance of RAG
The above image illustrates the practical application of Retrieval-Augmented Generation (RAG) in enhancing the capabilities of generative AI models. The image shows an engineer working on a complex project, symbolizing a professional who needs specific and accurate information to complete their tasks.
The standard ChatGPT model represents a traditional large language model (LLM) in the top part of the image. This model can provide general answers but might lack the specificity and accuracy needed for detailed inquiries about industry standards. In the middle section, the image features a combination of RAG and ChatGPT, indicating an enhanced version of the LLM.
This hybrid model integrates the generative abilities of ChatGPT with the retrieval capabilities of RAG. The bottom part of the image shows a database symbolizing a specific data source containing detailed industry standards. The RAG component accesses this data source to fetch precise and up-to-date information.
The process begins with the engineer asking for specific information about industry standards. The standard ChatGPT model provides a general answer, which may not be specific or detailed enough. The engineer then asks the same question to the RAG-augmented ChatGPT model. The RAG component retrieves specific and accurate information from the external data source (industry standards database). The RAG-augmented ChatGPT model integrates the retrieved information and provides a precise and relevant answer, making it more useful and reliable for the engineer's needs.
This example demonstrates the key benefits of RAG in this use case. The RAG-augmented model provides accurate and relevant information by accessing up-to-date and specific data sources.
The engineer saves time by receiving precise answers without manually searching through numerous documents, and the ability to cite specific data sources builds trust in the AI model’s responses. This example showcases how RAG enhances the functionality of generative AI models by combining their natural language processing capabilities with real-time data retrieval, leading to more accurate and reliable outputs.
Transform your LLM development with vetted LLM Training & Development engineers. Get 3 to 5 interview-ready candidates in 48hrs →
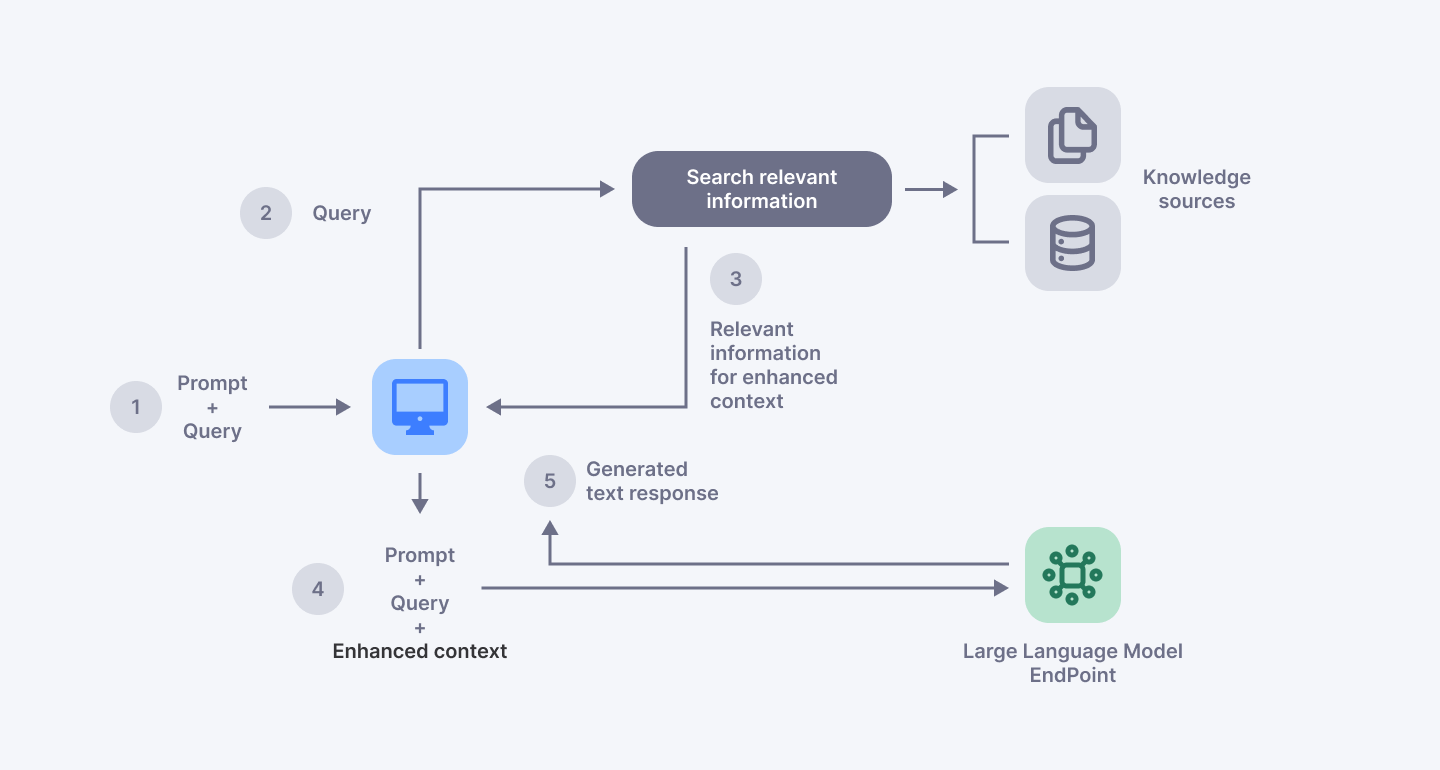
Figure 2: Conceptual flow of using RAG with LLMs
Technical Implementation of RAG
The implementation of RAG involves a few key steps. First, the retrieval component searches external data sources for relevant information when a query is made. This could involve searching online databases, APIs, or other structured and unstructured data repositories. The retrieved data is then processed and filtered to ensure relevance and accuracy. Next, this information is fed into the generative model, which integrates it with its pre-existing knowledge to produce a coherent and contextually appropriate response.
Here’s how you can implement a simple RAG system using Python. We will use the transformers library by Hugging Face to load a pre-trained language model, and the fails library for efficient similarity search. Ensure you have these libraries installed:
pip install transformers faiss-cpu
Example Code
Python
Copy code
import numpy as np
import fails
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
# Sample dataset
documents = [
"The Eiffel Tower is located in Paris, France."
"The Great Wall of China is one of the wonders of the world.",
"Python is a popular programming language for data science."
"The capital of Japan is Tokyo."
"Machine learning is a subset of artificial intelligence."
]
# Tokenizer and model for the retriever
retriever_tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
retriever_model = pipeline('feature-extraction, model='sentence-transformers/all-MiniLM-L6-v2')
# Tokenizer and model for the generator
generator_tokenizer = AutoTokenizer.from_pretrained('t5-small')
generator_model = AutoModelForSeq2SeqLM.from_pretrained('t5-small')
# Embed documents using the retriever model
document_embeddings = retriever_model(documents)
document_embeddings = np.array([np.mean(embed, axis=0) for embed in document_embeddings])
# Build FAISS index
dimension = document_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(document_embeddings)
def retrieve_documents(query, k=2):
query_embedding = retriever_model(query)
query_embedding = np.mean(query_embedding, axis=0).reshape(1, -1)
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
def generate_response(query):
# Retrieve relevant documents
retrieved_docs = retrieve_documents(query)
# Concatenate retrieved documents and query
input_text = " ".join(retrieved_docs) + " " + query
# Generate response
inputs = generator_tokenizer.encode("summarize: " + input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator_model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
response = generator_tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Example query
query = "Tell me about the Eiffel Tower and its location."
response = generate_response(query)
print("Query:", query)
print("Response:", response)Explanation of the Code
- Dataset: We have a small dataset of documents containing various facts.
- Retrieval Model: We use a sentence transformer model to convert documents and queries into embeddings.
- FAISS Index: We use FAISS to create an index of document embeddings for efficient similarity search.
- Retrieval Function: retrieve_documents fetches the top k documents similar to the query.
- Generation Function: generate_response concatenates the retrieved documents with the query and uses a generative model (T5) to produce a coherent response.
Output
When you run the example query, you should see an output similar to the following:
Sample Output:
Query: Tell me about the Eiffel Tower and its location.
Response: The Eiffel Tower is located in Paris, France. It is one of the most iconic landmarks in the world.
This example demonstrates the core idea of RAG: using a retrieval system to fetch relevant information and a generative model to synthesize a coherent response. The retrieval system would access a larger and more complex dataset in a real-world scenario, and the generative model might be more sophisticated.
Work from anywhere: Apply for remote Generative AI jobs on Index.dev. Sign up now →
Conclusion
In summary, RAG represents a significant leap forward in the capabilities of generative AI, offering enhanced accuracy, reliability, and user trust by seamlessly integrating external data sources into the generation process. This innovation transforms how engineers, medical professionals, financial analysts, and others leverage AI for specific needs. By combining the strengths of retrieval and generation, RAG LLMs provide a powerful tool for accessing and utilizing the most accurate and up-to-date information.
Are you a skilled generative AI engineer seeking a long-term remote opportunity? Join Index.dev to unlock high-paying remote careers with leading companies in the US, UK, and EU. Sign up today and take your career to the next level!
Looking to hire high-performing tech talent remotely? Index.dev offer a global talent network of 15,000 vetted engineers, ready to join your team. Get interview-ready candidates in 48 hours and save up to 60% on hiring and development costs. Hire qualified tech talent risk free: only pay if you're happy!
