A complicated project has a massive quantity of code.
Hundreds of methods and classes, thousands of lines of code.
If you want to avoid becoming lost in the jungle of code, relevant and easy-to-understand code is a must-have criterion in large projects.
Unfortunately, every developer had to deal with the issue of poor code readability. Everyone remembers wasting a lot of time trying to figure out why a code was obfuscated.
When you read someone else’s poorly named methods, classes, and variables, you spend far more time decrypting the code than writing new functional code.
But it shouldn’t be that way, and there’s no reason to write this way.
Here are 7 signs I encountered the most in the projects:
1) Meaningless names for variables, functions, and classes
This one sounds easy but sometimes it’s very hard to name variables, functions, or classes properly. There is also a quote about this that says:
There are only two hard things in Computer Science: cache invalidation and naming things.
Let’s take a look at this example:

When you read code like this, you ask yourself immediately, what do variables w and a mean, and what do they represent? Does w stand for wins, weight, or width? Is the variable a related to age or maybe average?
Now consider this:

Here, it is crystal clear that formula for the score is a number of wins added to the average KDA multiplied by 5.
One tip that helps me with naming is to not be stingy with namings and to make a variable name a bit longer.
I would rather read a bit longer variable name than spend 30 minutes reading tons of code to conclude what that variable is doing.
If the variable name becomes too long, then it’s probably a good idea to add some comments to that code.
A good name for a variable, class, or function should be descriptive and self-explanatory.
There is no need to include further comments if the name adequately describes the associated variable.
2) Huge scripts
When you open a script that you need to add a new change to, and you see it contains over 2000 lines of code, you instantly become depressed knowing that you will need to go through all that code to be able to know where to implement your change.
My rule of thumb is, if a script contains more than 500 lines of code, it needs cleanup and refactoring of that code, exporting pieces of business logic to separate scripts, components, or reusable functions.
Hoarding the code lines like that in huge scripts indicates that you don’t think about code modularity at all.
It means you just throw your thoughts into the code without thinking of code readability, the DRY principle, the KISS principle, reusability, and many other things good developers think about.
3) Magic numbers
This one is classic. Consider this code:

When you read this, you have a conversation with yourself like this:
- What does 0 stands for?
- Hmm, I see that it’s some type of user status but what type of status exactly
- I will probably need to read all of this code to make a conclusion about what 0 means here
- How am I supposed to implement the change in the code if I don’t know what type of user statuses this project has, otherwise I can introduce bugs.
Now compare it with this code:

Much better.
When you encounter numbers in your code, always ask yourself if you would like to read this in real life:
I went to the #17 cinema to watch #36 movie
Instead of
I went to the CineStar cinema to watch the Avatar movie.
The same is with the code as well, when you read it there should not be a number.
4) Big fat one-liners
Developers like to show off how good their skills are.
One of the worst ways people show that is by shortening their code, and instead of writing 20 lines of code they smash it into a single line.
You can do crazy one-liners in almost any programming language, but I think Python goes in the top 3.
It’s really crazy what you can type there and fit into a single line.
Consider this code:

Do you know what it does? Is this readable to you? How much time would you spend to understand this?
This is a code for a quick sort algorithm.
I would personally prefer a longer but more readable version than this crazy one-liner.
5) Ambiguous class designs
The subject of object-oriented programming is broad. It’s difficult to comprehend and put the theory of class design into practice.
The relationships between several classes may become more complicated as a project grows in size. The SOLID principles are the ideal method for writing object-oriented code in this situation.
Consider this class I encountered once:

First, the name of this class is really confusing. The author probably wanted to create something for use cases when some entity is never available.
Second, this class is doing nothing, it just returns a false value.
Why encapsulate such a simple thing as a false value in the class static method when you can just handle these cases without a class?
If you need to add a class, make sure it makes sense.
6) Code duplication
Software development follows the somewhat contentious rule of “don’t repeat yourself,” or “DRY.”
It seeks to make the code clearer, or less error-prone and challenging to deal with.
DRY aims to do this by eliminating redundant code from your codebase and substituting it with abstractions like functions, classes, and methods.
It is very simple to notice code repetition and extract repetitive code chunks into functions or components or classes, whatever suits you the best.
This is one of the craziest examples I have seen in projects that violate the DRY principle and common sense:
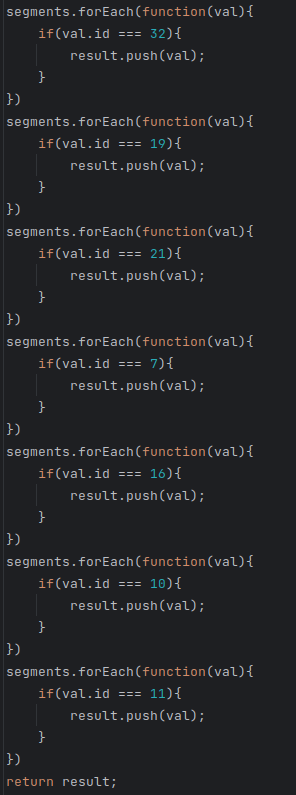
Not sure how this code ended in production but it is mind-boggling how unreadable and unoptimized this code is:
- it iterates through the segments array multiple times without any need
- it compares the conditions with magic numbers
- it doesn’t use or operator
All this code above can be replaced by 2 lines:

7) Dead code
In legacy projects, you will always find some dead code. A field, method, variable, or class is no longer in use (typically because it is outdated).
This happens because nobody had the time to refactor the outdated code when the software’s specifications changed or repairs needed to be made.
There are also developers who like to keep that old code, just in case there is the possibility that they will need it in the future.
It doesn’t make much sense, as it is used in every project and you can easily find that code.
Using a good IDE is the quickest approach to discovering dead code:
- remove unnecessary files and unused code.
- eliminate unnecessary parameters
- remove the redundant class, by merging the subclass and superclass in one or move all features from the class to another one.
The benefits of removing dead code are smaller code size and easier maintenance of the project.
