Chinese large language models are rapidly evolving and now compete seriously in enterprise use cases. In this comparison, we evaluate Kimi 2.5, Qwen 3.5, and DeepSeek R2 across structured business analysis, backend engineering, and European expansion strategy tasks.
Instead of relying solely on benchmark scores, we tested them in practical, real-world enterprise scenarios. Each model received identical prompts and was evaluated on reasoning depth, regulatory awareness, code quality, pricing logic, and roadmap realism.
Scale your AI roadmap faster with proven developers experienced in enterprise LLM integration and deployment.
What is Kimi 2.5?
Kimi 2.5 is an advanced large language model developed by Moonshot AI. It is built to handle long context inputs, complex reasoning tasks, and enterprise-level problem-solving. The model is optimized for structured analysis, technical depth, and multilingual capability, especially in Chinese and English.
It performs strongly in financial modeling, regulatory discussions, software engineering tasks, and strategic planning scenarios. Kimi 2.5 is designed to support professional workflows that require clarity, precision, and logical consistency. Its architecture focuses on stable, long-term document understanding, making it suitable for research, compliance analysis, coding assistance, and enterprise decision-support use cases.
What is Qwen 3.5?
Qwen 3.5 is a large language model developed by Alibaba Cloud as part of the Tongyi Qwen series. It is designed for enterprise applications, multilingual reasoning, coding support, and structured business tasks. The model supports strong English and Chinese performance and is optimized for commercial deployment across cloud and on premise environments.
Qwen 3.5 focuses on balanced reasoning, regulatory awareness, and scalable API integration. It is commonly used for enterprise automation, document intelligence, developer assistance, and data analysis workflows that require reliability and production-readiness.
What is DeepSeek R2?
DeepSeek R2 is a reasoning-focused large language model developed by DeepSeek AI. It emphasizes logical consistency, mathematical reasoning, and structured analytical output. The model is optimized for technical problem solving, code generation, and business analysis scenarios.
DeepSeek R2 supports multilingual tasks and is designed for enterprise deployment with a focus on cost efficiency and performance. It aims to compete in high reasoning benchmarks while maintaining practical usability for developers and organizations that require reliable decision support and structured outputs.
⭢ Explore the top Chinese AI models like DeepSeek and see which LLM stands out for real enterprise use.
How we compared (our testing process)
To fairly compare Kimi 2.5, Qwen 3.5, and DeepSeek R2, we created three enterprise-focused evaluation tasks covering business analysis, backend debugging and refactoring, and European market expansion strategy. Each model received identical prompts to ensure consistency and remove bias.
We evaluated responses against clearly defined criteria for each task, including calculation accuracy, regulatory understanding, unit economics reasoning, code robustness, input validation, pricing logic, GTM clarity, and roadmap realism.
For coding tasks, we manually reviewed logic, validation depth, discount modeling, and test coverage.
We focused on analytical depth, execution detail, and how enterprise-ready each response was for real decision-making scenarios.
Here are the tasks we performed
1. Enterprise data analysis and insight extraction
What it tests: Reasoning, structured thinking, business understanding, clarity, and decision making.
Task: Give the model messy business data and ask for insights + actions.
Prompt:
“You are a senior business analyst.
Below is the quarterly revenue data of a SaaS company:
Q1:
Marketing Spend: $120,000
New Customers: 800
Churn Rate: 8%
Revenue: $480,000
Q2:
Marketing Spend: $150,000
New Customers: 950
Churn Rate: 10%
Revenue: $520,000
Q3:
Marketing Spend: $200,000
New Customers: 1,100
Churn Rate: 14%
Revenue: $540,000
Q4:
Marketing Spend: $180,000
New Customers: 1,050
Churn Rate: 9%
Revenue: $610,000
Tasks:
1. Identify 5 key insights.
2. Explain possible root causes of churn changes.
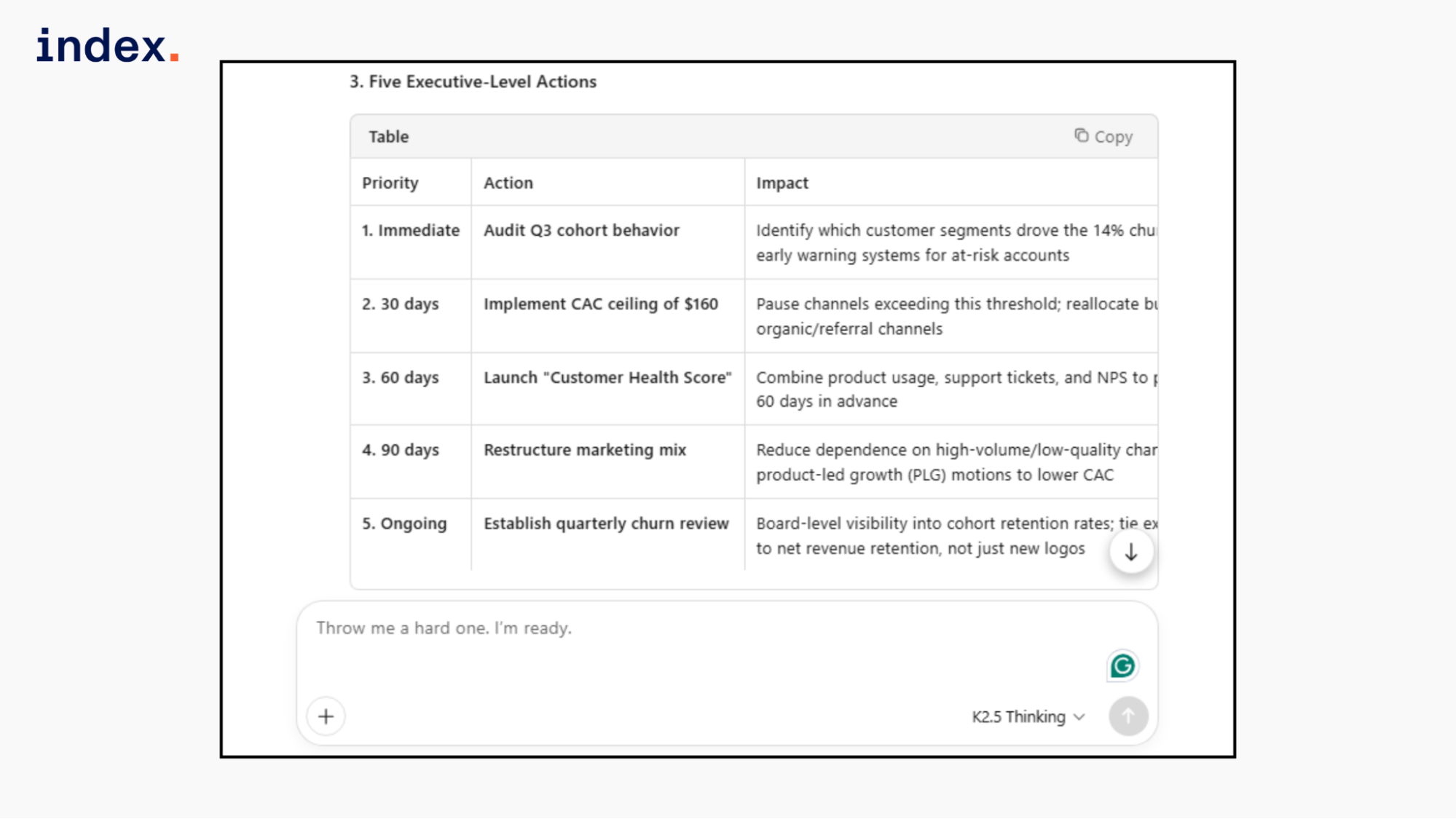
3. Suggest 5 executive-level actions.
4. Summarize in under 150 words for the CEO.”
Kimi 2.5 response:
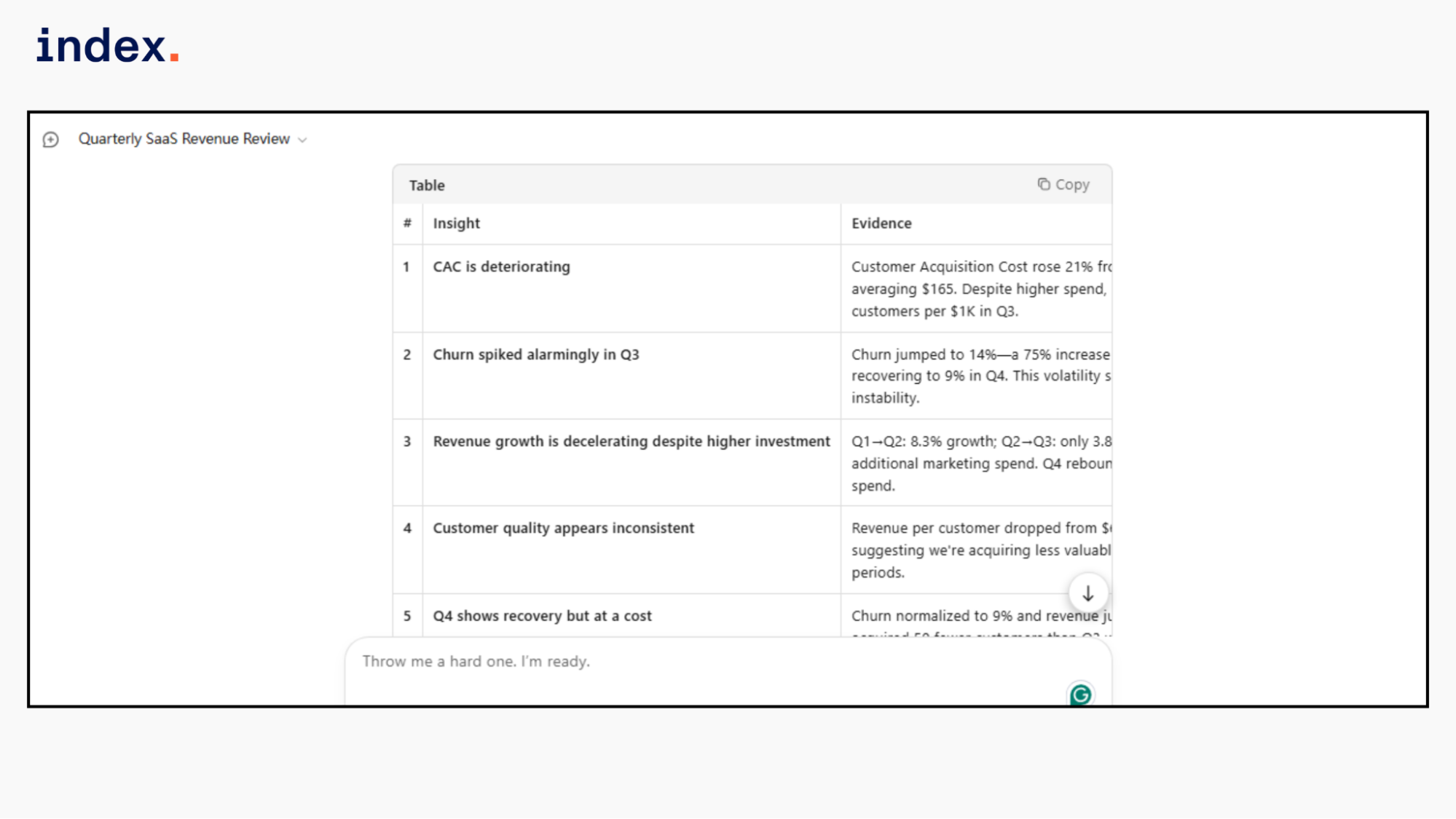
Kimi correctly calculated the customer acquisition cost and revenue per customer, which added deeper unit economics analysis. It clearly linked higher marketing spend to declining customer quality and rising churn. Executive actions were specific and operational.
However, it stated that revenue grew 27% year over year. The dataset only contains one year of quarterly data, so this is not year-over-year growth. The math from Q1 to Q4 is correct, but the growth label is inaccurate. This is a framing error, not a calculation mistake.

Overall, this response shows the strongest financial reasoning among the three models.
Qwen 3.5 plus response:
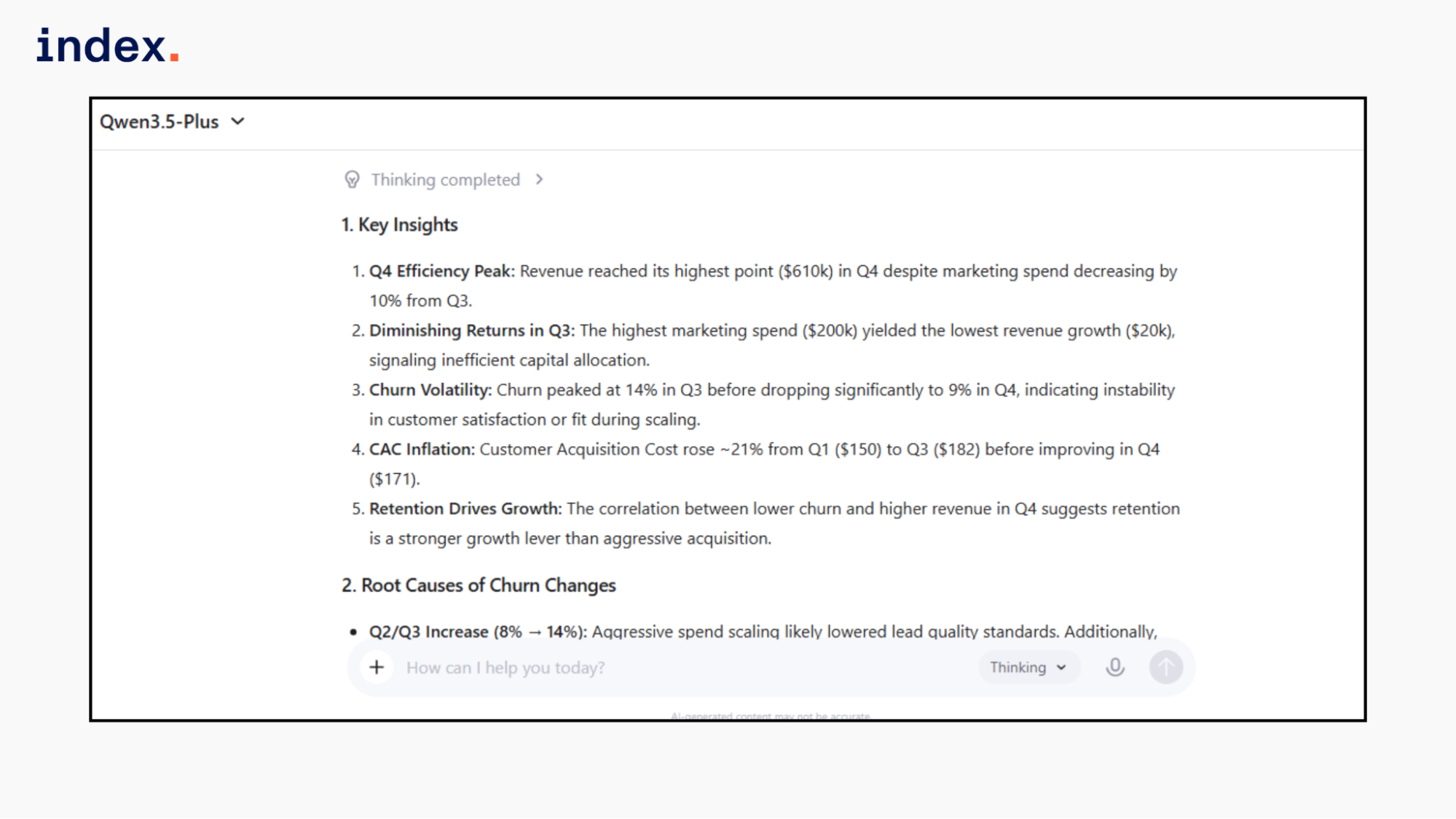
Qwen calculated customer acquisition cost correctly and identified inefficient capital allocation in Q3. It connected lower churn in Q4 with stronger revenue growth. However, it did not calculate revenue per customer or deeper efficiency metrics such as customer value trends.
It correctly stated that revenue grew 27% from Q1 to Q4 without labeling it as year-over-year growth, which is accurate based on the dataset.
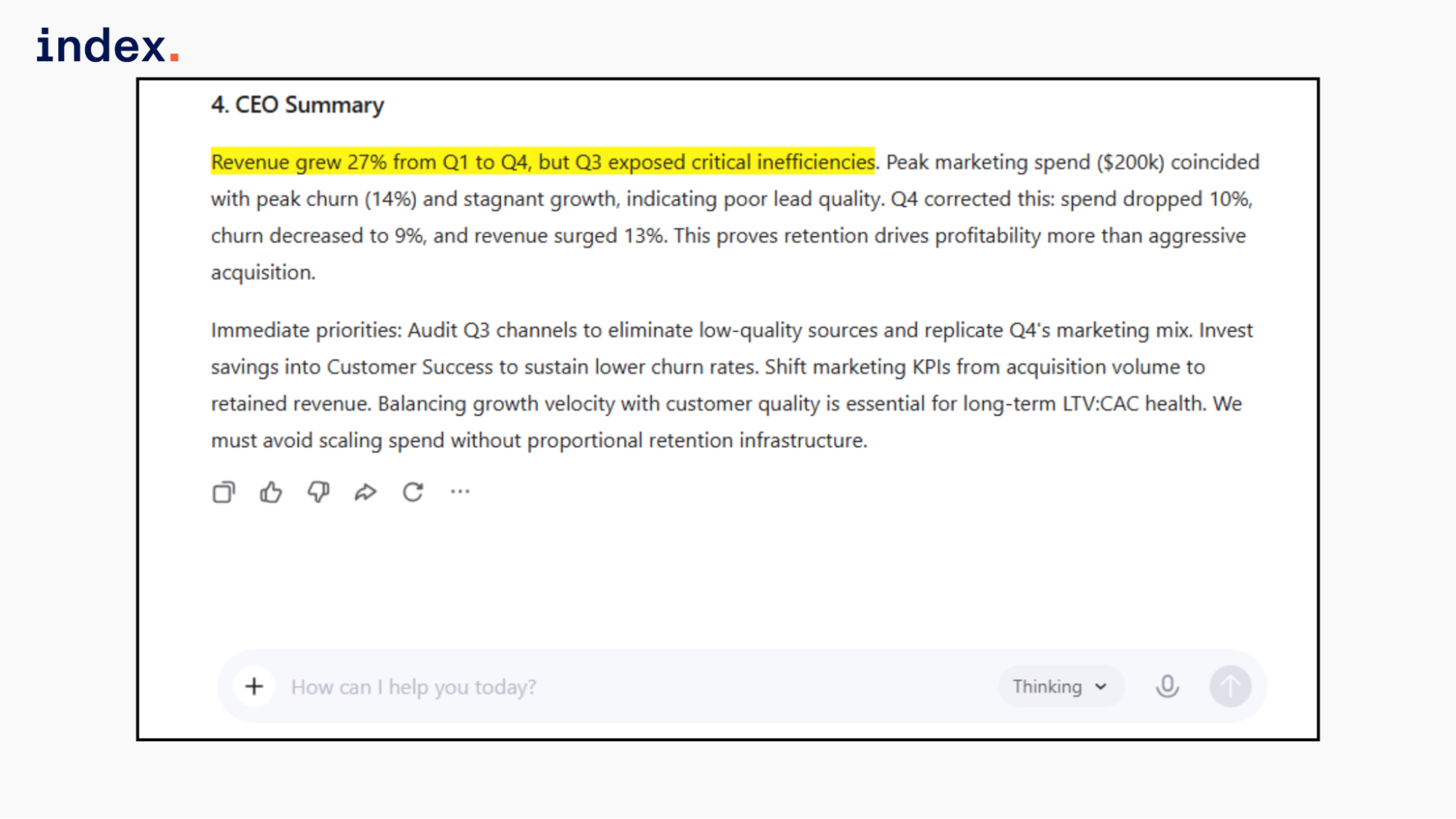
The analysis was clean and accurate, but remained surface-level compared to the others.
DeepSeek R2 response:

DeepSeek correctly calculated customer acquisition costs for each quarter and clearly identified churn as the primary performance risk. It explained how high marketing spend in Q3 did not translate into proportional revenue growth.
However, it did not calculate revenue per customer, which limits the depth of unit economics analysis.
It also mentioned 27% growth from Q1 to Q4, but did not incorrectly label it as year-over-year growth. The framing remained accurate. The reasoning was logical and aligned with the data, but the financial layer was less detailed than Kimi's response.

Final verdict:
All three models produced correct calculations and structured analysis.
Qwen delivered accurate but surface-level reasoning without deeper unit economics.
DeepSeek showed stronger strategic thinking but did not extend financial modeling further.
Kimi demonstrated the strongest depth by calculating revenue per customer and connecting churn, customer quality, and marketing efficiency. Its only issue was mislabeling sequential growth as year-over-year growth.
⭢ Explore the leading Chinese open-source LLM models and find out which ones are ready for production use.
2. Enterprise code debug and refactor
What it tests: Code accuracy, debugging depth, explanation clarity, refactoring quality.
Task: Give broken backend logic and ask for correction and code improvement.
Prompt:
“ You are a senior backend engineer.
The following Python function calculates total order value after discount. It has bugs and bad design.
def calculate_total(price, quantity, discount):
total = price * quantity
if discount > 0:
total = total - discount
if quantity > 100:
total = total * 0.90
return total
Requirements:
1. Identify logical errors.
2. Fix edge cases.
3. Refactor for enterprise-grade readability.
4. Add input validation.
5. Write unit tests.
6. Explain what was wrong and why your solution is better.”
Kimi 2.5 response:
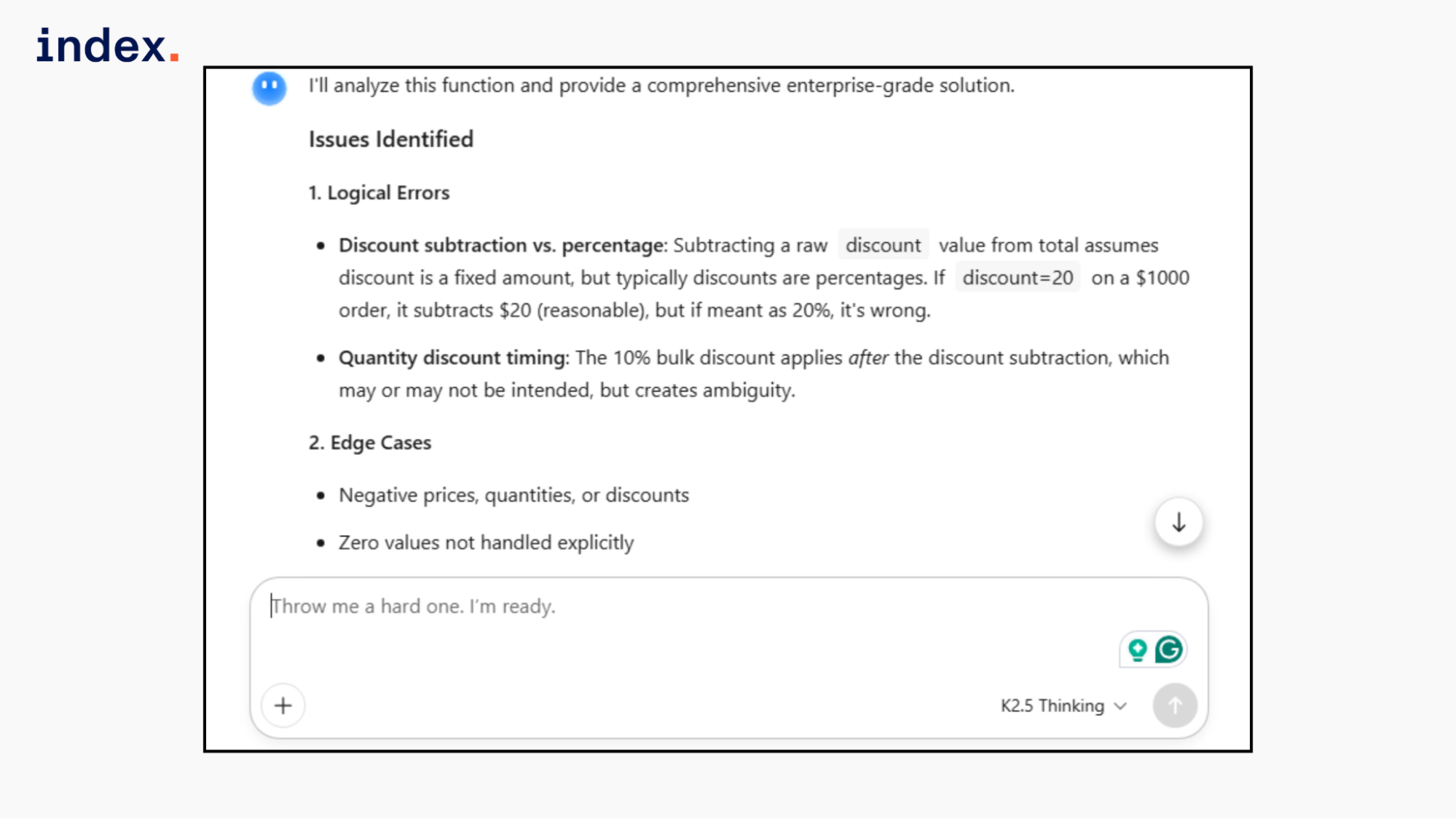
Kimi fully separated fixed and percentage discount logic using an explicit Discount type, which correctly resolves the ambiguity in the original function. It added strong input validation for negative prices, quantities, and invalid discount values. It handled float precision using Decimal and proper rounding.
Unit tests covered edge cases, boundaries, and precision issues. The explanation clearly identified original design flaws and justified architectural improvements. This is enterprise-grade depth with strong engineering discipline.
Qwen 3.5 plus response:
Qwen correctly replaced float with Decimal and implemented proper rounding to currency precision. It validated negative price, quantity, and discount inputs and prevented negative totals by capping discounts. It clarified the discount order and made bulk rules configurable via constants.
Unit tests covered boundary conditions, combined discounts, validation failures, and floating-point precision. However, it treated discount only as a fixed amount and did not model percentage discount types explicitly. The explanation was structured, practical, and technically sound.
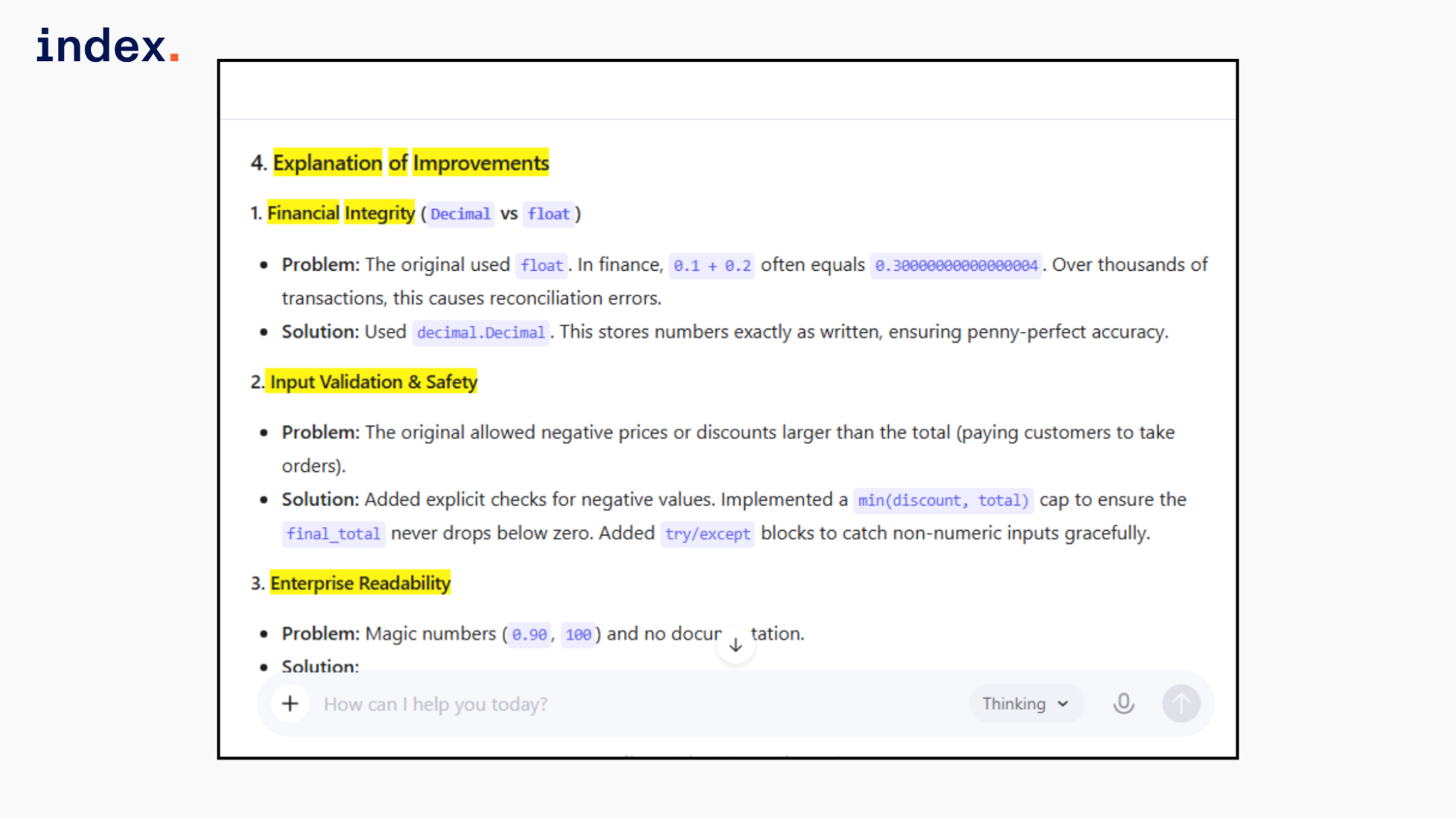
DeepSeek R2 response:
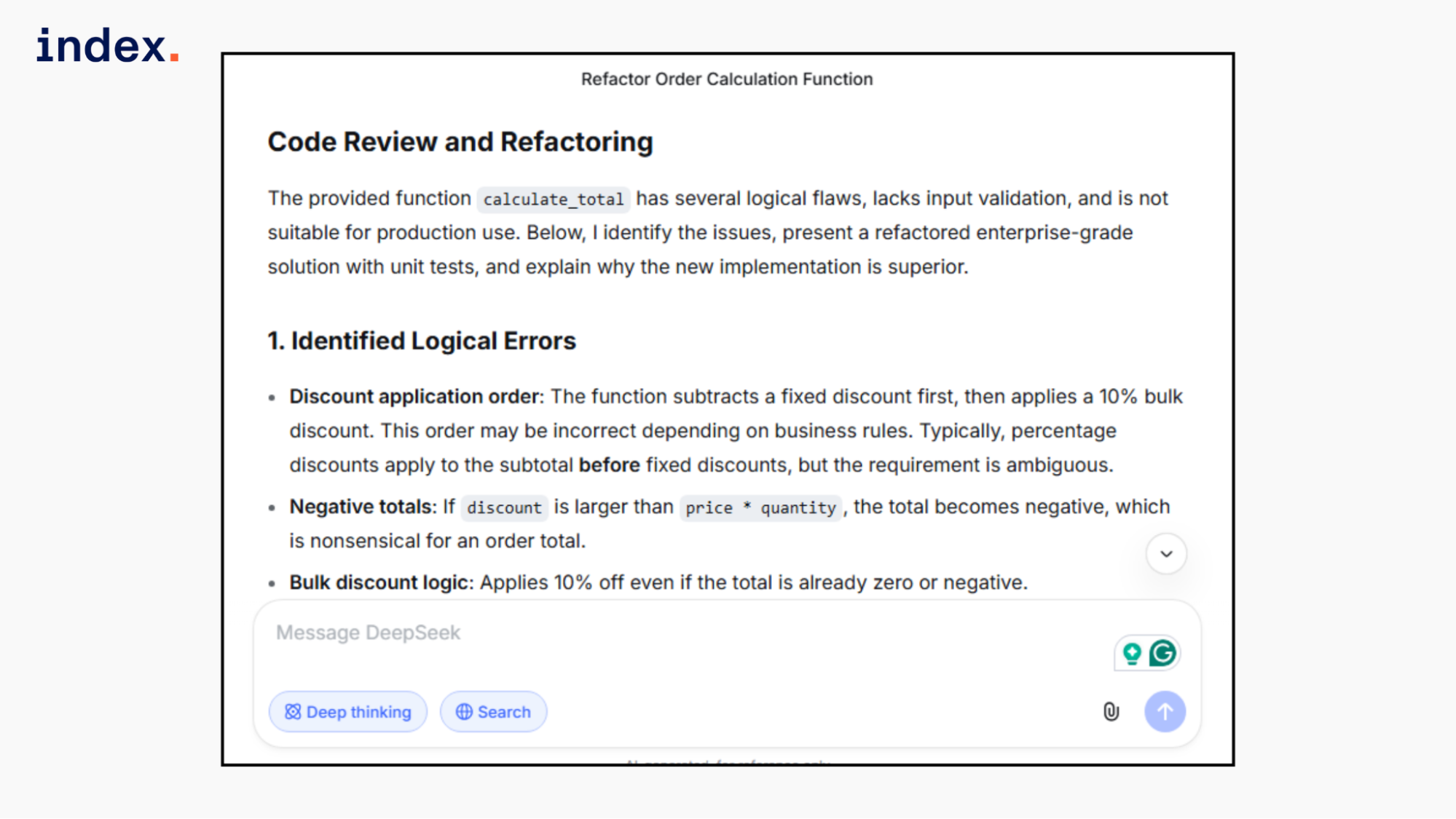
DeepSeek fixed floating-point precision using Decimal and added strong input validation for negative values and invalid types. It prevented negative totals by clamping to zero. However, it treated the discount only as a fixed amount and did not fully resolve the ambiguity between percentage and fixed amounts.
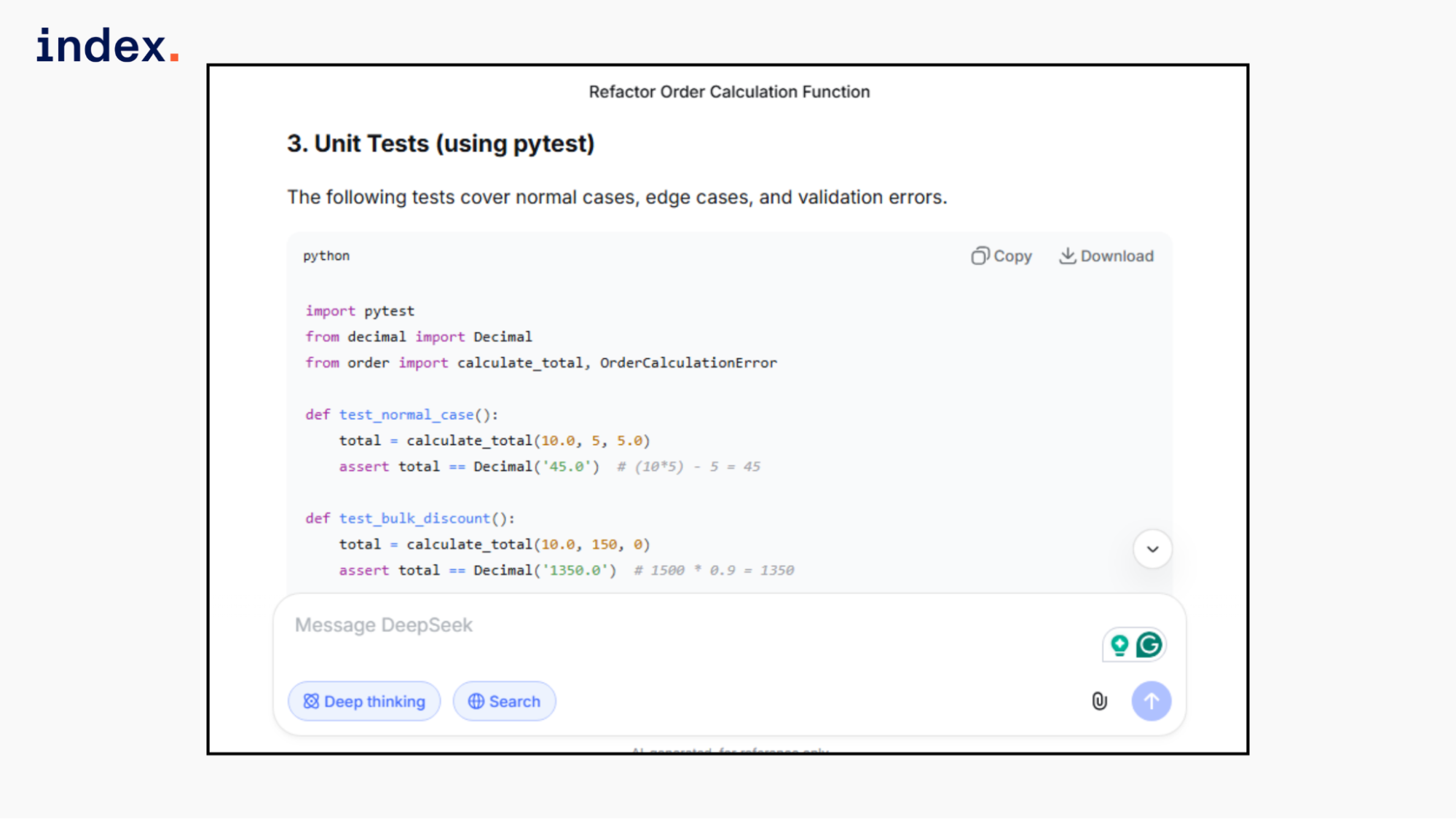
Unit tests covered edge cases and validation paths. The explanation was clear and structured, but the architectural depth was simpler than Kimi's and less explicit in discount modeling.
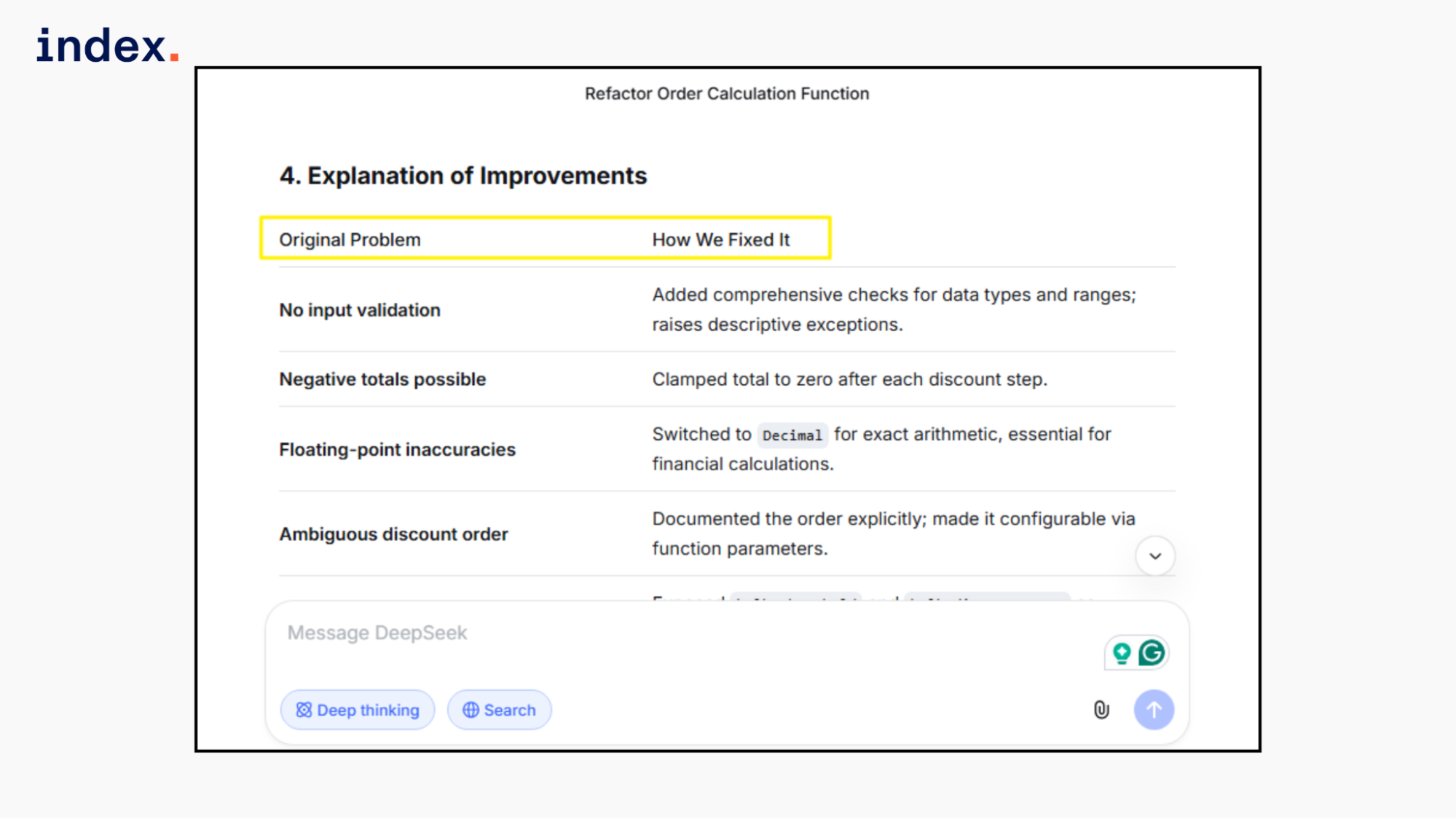
Final verdict:
All three models corrected precision and added validation.
DeepSeek delivered a clean, production-ready implementation while keeping the discount logic simple.
Qwen improved structure and auditability with a result object and solid tests.
Kimi demonstrated the strongest architectural depth with explicit discount modeling, financial abstraction, and comprehensive testing. For enterprise backend extensibility and safety, Kimi performs best.
3. Enterprise strategy simulation
What it tests: Long reasoning, business modeling, structured output, practical thinking.
Task: Ask for a structured enterprise expansion strategy.
Prompt:
“You are a strategy consultant.
A Chinese AI company wants to expand into Europe with its enterprise LLM product.
Company profile:
- Strong in Chinese and English
- Good pricing advantage
- Limited brand awareness outside Asia
- Strong on-prem deployment capability
Tasks:
1. Identify the top 3 target industries in Europe.
2. List regulatory risks.
3. Suggest GTM strategy.
4. Define pricing model.
5. Provide a 12-month expansion roadmap.
6. Present answer in structured sections with bullet clarity.”
Kimi 2.5 response:

Kimi showed stronger regulatory specificity. It mentioned DORA, MiFID II, FDI screening, and conformity assessments, not just GDPR and AI Act. The roadmap included measurable targets such as ARR goals and geographic sequencing. Pricing tiers were numerically defined. The GTM positioning was clearly framed against US hyperscalers. This reflects more enterprise-level financial and competitive thinking.
Qwen 3.5 plus response:

Qwen showed strong regulatory awareness by mentioning the EU AI Act, GDPR, NIS2, and cross-border transfer risks. The GTM strategy was clearly structured around channel partnerships and trust building. Pricing avoided cheap positioning and focused on TCO and enterprise signaling. The roadmap was phased with measurable ARR targets. Compared to others, it balanced geopolitical risk, positioning, and execution detail effectively.
DeepSeek R2 response:
DeepSeek covered GDPR and AI Act well, but remained broader in regulatory depth. It added geopolitical concerns around jurisdiction, which was a useful angle. The GTM strategy was clear and partnership-driven, but financial targets and measurable milestones were lighter. Pricing strategy was directional rather than numerically anchored. Strong reasoning, but slightly less execution detail than Kimi.
Final verdict:
All three models demonstrated strong strategic reasoning and regulatory awareness. DeepSeek was commercially sound but slightly lighter in measurable execution metrics. Kimi showed strong regulatory specificity and competitive positioning. Qwen delivered the most balanced plan across regulation, GTM clarity, pricing psychology, and realistic milestones.
Qwen excels at enterprise expansion planning because it combines compliance depth, trust strategy, financial targets, and positioning discipline in a cohesive, execution-focused manner.
Summary table: Kimi 2.5 vs Qwen 3.5 vs DeepSeek R2
| Criteria | Kimi 2.5 | Qwen 3.5 | DeepSeek R2 |
| Business analysis | Deep unit economics. Strong metric linkage. | Clear insights. Less depth. | Logical analysis. Moderate depth. |
| Code quality | Enterprise architecture. Strong validation. Full tests. | Good validation. Code not fully visible. | Clean logic. Strong validation. Simpler design. |
| Regulatory depth | Detailed EU AI Act. Sector rules included. | GDPR, AI Act, and NIS2 are covered well. | GDPR and AI Act covered. Broader view. |
| GTM clarity | Strong competitive positioning. Clear targets. | Balanced trust and pricing focus. | Practical strategy. Fewer metrics. |
| Roadmap | Phased. Measurable goals. | Phased. Revenue targets included. | Structured. Fewer financial anchors. |
| Enterprise readiness | Highest overall maturity. | Strong and balanced. | Solid but slightly lighter depth. |
Verdict at a Glance
| Model | Overall Strength | Key Weakness | Best For |
| Kimi 2.5 | Deep analysis and strong architecture | Minor framing inconsistencies | Enterprise financial analysis and backend engineering |
| Qwen 3.5 | Balanced strategy and regulatory clarity | Slightly lighter analytical depth | Market expansion and compliance-focused planning |
| DeepSeek R2 | Practical reasoning and solid validation | Less architectural modeling depth | Structured analysis and production-ready logic |
⭢ Read next to understand how AI models from the US, China, and Europe compare in innovation, scale, and performance.
Final Words
Kimi 2.5, Qwen 3.5, and DeepSeek R2 all demonstrate strong enterprise capability, but they differ in depth and emphasis. Kimi 2.5 stands out in financial modeling, architectural design, and unit economics reasoning. Qwen 3.5 performs best in balanced strategic planning, regulatory clarity, and structured go-to-market execution. DeepSeek R2 delivers practical, production-ready logic with clean reasoning and solid validation.
The right choice depends on your priority. If you need deeper analytical rigor, choose Kimi. If you need a structured expansion strategy, choose Qwen. If you need clean, dependable logic for implementation tasks, choose DeepSeek.
➡︎ Choosing the best LLM is one thing. Building enterprise AI products with it is another. Looking to hire AI and backend engineers who understand real-world enterprise systems? Index.dev connects you with vetted, AI-enabled talent ready to ship at scale.
