Working with Java Maps can be tricky when you need to retrieve elements by index. Unlike Lists, Maps don’t have a built-in way to access values sequentially. They’re built for fast key-based lookups, not index-based retrieval.
But sometimes, you still need to grab elements in order—maybe for iteration, pagination, or debugging. So, how do you do it?
I’ll walk you through a few ways to handle this:
- Converting a Map to a List
- Using an Iterator
- Leveraging the Streams API
- Taking advantage of LinkedHashMap's predictable order
Each approach has trade-offs in performance, readability, and memory usage. Let’s break them down.
Join Index.dev today and work with top global companies on innovative remote projects. Start your remote career now!
Understanding Map Indexing Limitations
Maps in Java are great for fast lookups by key, but they don’t work like Lists or Arrays when you need to access elements by index. Since Maps use structures like hash tables or trees, they’re optimized for key-based retrieval—not sequential access.
Even if you’re using a LinkedHashMap, which maintains insertion order, you won’t find a built-in indexOf() method. So if you ever need to get an element by index, you’ll have to work around it.
Why is this by design?
- Key-Based Retrieval: Maps provide rapid access (O(1) on average for HashMap, or O(log n) for TreeMap) using keys, which is essential for many applications.
- Order Preservation is Optional: Only certain implementations like LinkedHashMap guarantee insertion order, but even then, the concept of an "index" isn’t part of the Map interface.
When you need index-like access, you must convert the Map’s entries or values into a sequential structure (like a List) or use other traversal methods (such as iterators or streams). The following methods explore several techniques to simulate index-based retrieval while discussing their trade-offs.
Read More: How to Convert a Java Web API to .NET
Method 1: List Conversion (Using entrySet() or values())
When you need index-based access, one straightforward method is to convert the Map’s entries or values into a List. This conversion allows you to retrieve elements using their list index.
Ideal Use Scenario
- You have a moderate-sized Map.
- Insertion order is important.
- Performance is acceptable with one-time conversion overhead.
Code Example
import java.util.*;
public class MapIndexRetriever {
public static <K, V> V getValueByIndex(Map<K, V> map, int index) {
// Validate input parameters
Objects.requireNonNull(map, "Map cannot be null");
if (index < 0) {
throw new IllegalArgumentException("Index must be non-negative");
}
// Use LinkedHashMap to preserve insertion order
List<V> valuesList = new ArrayList<>(map.values());
// Check index bounds
return (index < valuesList.size()) ? valuesList.get(index) : null;
}
public static void main(String[] args) {
Map<String, Integer> scores = new LinkedHashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);
scores.put("Charlie", 78);
scores.put("David", 92);
// Retrieve value at index 2
Integer value = getValueByIndex(scores, 2);
System.out.println("Value at index 2: " + value);
// Performance measurement
long startTime = System.nanoTime();
getValueByIndex(scores, 2);
long endTime = System.nanoTime();
System.out.printf("Method execution time: %d nanoseconds%n", endTime - startTime);
}
}Explanation
- What was implemented? We converted the Map's values into a List, creating a mechanism for index-based access. The method uses a generic approach to retrieve values from any Map implementation while preserving the insertion order.
- Where and Why? This method provides a straightforward solution for developers needing sequential access to Map values. By converting to a List, we overcome the Map's inherent key-based retrieval limitation, enabling index-based lookups while maintaining the original data's order through the use of LinkedHashMap.
Pros
- Simple and easy to implement
- Provides fast lookup via get(index)
Cons
- Conversion incurs an O(n) time complexity.
- Additional memory is used for the List.
Performance Profile
- Time Complexity: O(n) for conversion, O(1) for index access.
- Space Complexity: O(n).
Method 2: Stream-Based Index Resolution
Java Streams provide a modern, functional approach for retrieving an element at a specific index. This method uses the skip() operation, which is concise and can potentially benefit from parallel processing.
Ideal Scenario
- When working with large datasets.
- When streaming operations are preferred.
- When you prefer a functional programming style.
Code Example
import java.util.*;
import java.util.stream.*;
public class StreamMapIndexResolver {
public static <V> V getValueByIndexStream(Map<String, V> map, int index) {
Objects.requireNonNull(map, "Map cannot be null");
return map.values().stream()
.skip(index)
.findFirst()
.orElse(null);
}
public static void main(String[] args) {
Map<String, Integer> scores = new LinkedHashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);
scores.put("Charlie", 78);
scores.put("David", 92);
Integer value = getValueByIndexStream(scores, 2);
System.out.println("Stream Value at index 2: " + value);
// Parallel stream demonstration
Integer parallelValue = scores.values().parallelStream()
.skip(2)
.findFirst()
.orElse(null);
System.out.println("Parallel Stream Value: " + parallelValue);
}
}Explanation
- What was implemented? We created a stream from the Map's values and used the skip() and findFirst() methods to retrieve an element at a specific index. This approach leverages the Stream API's lazy evaluation capabilities.
- Where and Why? This method is particularly useful when working with large datasets or when you prefer a functional programming approach. By using streams, we can achieve index-based retrieval with a concise, readable syntax that supports potential parallel processing.
Pros
- Concise and expressive.
- Suitable for parallel stream operations in large datasets.
- Lazy evaluation minimizes memory overhead.
Cons
- Requires familiarity with the Streams API.
- Still performs in O(n) time complexity.
Performance Profile
- Time Complexity: O(n) in the worst-case.
- Space Complexity: O(1).
Method 3: Iterator-Based Indexed Retrieval
If you prefer not to create an extra List, you can use an Iterator to traverse the Map’s values until you reach the desired index.
Ideal Scenario
- When memory is a constraint.
- When you want to avoid additional data structure overhead.
Code Example
import java.util.*;
public class IteratorMapIndexRetriever {
public static <V> V getValueByIterator(Map<String, V> map, int targetIndex) {
Objects.requireNonNull(map, "Map cannot be null");
if (targetIndex < 0) {
throw new IllegalArgumentException("Index must be non-negative");
}
Iterator<V> iterator = map.values().iterator();
V result = null;
int currentIndex = 0;
while (iterator.hasNext()) {
result = iterator.next();
if (currentIndex == targetIndex) {
break;
}
currentIndex++;
}
return currentIndex == targetIndex ? result : null;
}
public static void main(String[] args) {
Map<String, Integer> scores = new LinkedHashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);
scores.put("Charlie", 78);
scores.put("David", 92);
Integer value = getValueByIterator(scores, 2);
System.out.println("Iterator Value at index 2: " + value);
}
}Explanation
- What was implemented? We utilized an Iterator to manually traverse the Map's values, keeping track of the current index until we reach the desired position. This approach avoids creating an additional data structure.
- Where and Why? This method is ideal for memory-constrained environments where creating a temporary List is undesirable. It provides a straightforward, low-overhead mechanism for index-based retrieval directly from the Map's values.
Pros
- Memory efficient - no extra List is needed.
- Straightforward iteration.
Cons
- Manual traversal increases code verbosity.
- Still operates in O(n) time complexity in the worst-case scenario.
Performance Profile
- Time Complexity: O(n) (traversal).
- Space Complexity: O(1).
Method 4: Leveraging LinkedHashMap Behavior for Predictable Order
A LinkedHashMap maintains the insertion order of its entries. By using a LinkedHashMap, you guarantee that converting to a List (or using an Iterator/Stream) will yield a consistent order, making index-based retrieval reliable.
Ideal Use Scenario
- When your application logic depends on the order of insertion.
- When you need a predictable sequence for subsequent operations.
Code Example
import java.util.*;
public class LinkedHashMapOrderRetriever {
public static <K, V> Map.Entry<K, V> getEntryByIndex(Map<K, V> map, int index) {
Objects.requireNonNull(map, "Map cannot be null");
if (index < 0) {
throw new IllegalArgumentException("Index must be non-negative");
}
List<Map.Entry<K, V>> entryList = new ArrayList<>(map.entrySet());
return index < entryList.size() ? entryList.get(index) : null;
}
public static void main(String[] args) {
Map<String, Integer> scores = new LinkedHashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);
scores.put("Charlie", 78);
scores.put("David", 92);
Map.Entry<String, Integer> entry = getEntryByIndex(scores, 2);
if (entry != null) {
System.out.printf("Entry at index 2: Key = %s, Value = %d%n",
entry.getKey(), entry.getValue());
}
}
}Explanation
- What was implemented? The code converts the entrySet() of a LinkedHashMap into a List. This ensures that you can access both keys and values by their insertion order.
- Where and Why? This method underscores the importance of data structure choice. With LinkedHashMap, you ensure the order is predictable, which is critical for index-based retrieval. It's particularly useful when the insertion order of elements is significant to your application's logic.
Pros
- Guarantees consistent order of elements.
- Works seamlessly with the other methods that require order conversion.
Cons
- Limited to scenarios where insertion order is maintained.
- Conversion overhead is similar to Method 1.
Performance Profile
- Time Complexity: O(n) for conversion, O(1) for access.
- Space Complexity: O(n).
Explore More: How to Identify and Optimize Long-Running Queries in Java
Best Practices to Follow
- Select the Right Map Implementation: Use LinkedHashMap when preserving insertion order is essential. For unordered maps, consider if index-based access is truly necessary.
- Minimize Unnecessary Conversions: If you need frequent index-based retrieval, convert once and cache the resulting List rather than converting on every access.
- Leverage Streams for Readability: The Streams API offers clean and concise code, especially when combined with parallel processing for large datasets.
- Monitor Memory Usage: When converting large Maps, be aware of the extra memory overhead. Use profiling tools (e.g., VisualVM, JProfiler) to monitor the memory footprint.
Memory Profiling Recommendations
- Method 1 (List Conversion): Monitor the size and growth of the temporary List using tools like VisualVM. Consider caching the list if multiple accesses are needed.
- Method 2 (Streams): Use Java Flight Recorder or similar tools to assess the performance impact of stream operations on very large datasets.
- Method 3 (Iterator): This method is inherently memory-efficient, but ensures that the iteration logic is optimized for your specific use-case.
- Method 4 (LinkedHashMap Conversion): Ensure that the Map size remains manageable before converting to a List. Profiling with tools like JProfiler can help determine if the overhead is acceptable.
Comparative Performance Metrics Diagram
Comparative Performance Metrics
Below is a simplified table comparing the performance metrics of each method:
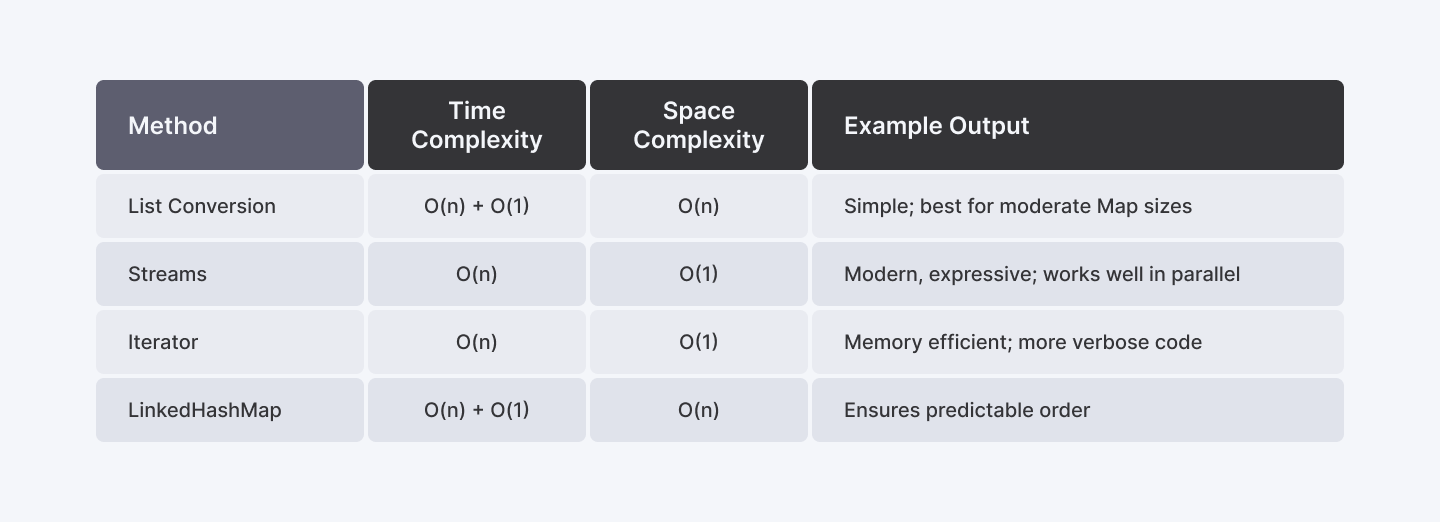
Method | Time Complexity | Space Complexity | Comments |
List Conversion | O(n) + O(1) | O(n) | Simple; best for moderate Map sizes |
Streams | O(n) | O(1) | Modern, expressive; works well in parallel |
Iterator | O(n) | O(1) | Memory efficient; more verbose code |
LinkedHashMap | O(n) + O(1) | O(n) | Ensures predictable order |
When choosing between these methods, consider:
- Data Size:
- Small Maps (<1000 elements): Method 1 (List Conversion) and Method 4 (LinkedHashMap with EntrySet) are effective since the conversion overhead is minimal.
- Large Maps with Frequent Lookups: Method 2 (Stream-Based Resolution) is preferable as it can be enhanced with parallel processing to optimize performance.
- Memory-Constrained Environments: Method 3 (Iterator-Based Retrieval) is ideal because it avoids additional memory allocation by not creating a temporary List.
- Operation Complexity:
- Index Lookup:
- Method 1 & 4: O(n) for the conversion step, then O(1) for accessing an element.
- Method 2 & 3: O(n) in the worst case for retrieving the target element.
- Value Lookup: All methods yield O(1) access after conversion or traversal, although the initial retrieval strategy differs.
- Insertion: For all methods, the Map insertion remains O(1) amortized (assuming you use a standard implementation like LinkedHashMap).
- Index Lookup:
Use Cases & Applications
Use Case 1: Retrieving User Scores (Leaderboard)
Imagine a scenario where you need to retrieve a user's score based on their leaderboard position. This method is particularly useful when working with game or educational platforms.
public class LeaderboardManager {
public static void displayTopScores(Map<String, Integer> scores, int topN) {
List<Map.Entry<String, Integer>> sortedScores = new ArrayList<>(scores.entrySet());
sortedScores.sort(Map.Entry.<String, Integer>comparingByValue().reversed());
System.out.println("Top " + topN + " Scores:");
sortedScores.stream()
.limit(topN)
.forEach(entry ->
System.out.printf("%s: %d%n", entry.getKey(), entry.getValue())
);
}
public static void main(String[] args) {
Map<String, Integer> scores = new LinkedHashMap<>();
scores.put("Alice", 95);
scores.put("Bob", 87);
scores.put("Charlie", 92);
scores.put("David", 89);
displayTopScores(scores, 3);
}
}Use Case 2: Ordered Data Transformation
For applications that require data transformations while preserving the order (for instance, converting raw data before visualization), converting a Map’s entries into a List is beneficial.
public class DataTransformer {
public static List<Integer> transformValues(
Map<String, Integer> dataStore,
Function<Integer, Integer> transformer
) {
return dataStore.values().stream()
.map(transformer)
.collect(Collectors.toList());
}
public static void main(String[] args) {
Map<String, Integer> rawData = new LinkedHashMap<>();
rawData.put("first", 10);
rawData.put("second", 20);
rawData.put("third", 30);
List<Integer> scaledData = transformValues(
rawData,
value -> value * 2
);
System.out.println("Transformed: " + scaledData);
}
}Learn More: Key Algorithms Developers Should Learn in 2025
Conclusion
While Java’s Map does not natively support index-based access, you can simulate this functionality using several methods - converting to a List, iterating with an Iterator, leveraging the Streams API, or taking advantage of LinkedHashMap’s order.
Each method has its strengths and weaknesses - whether it’s time complexity, memory usage, or code verbosity - so choosing the right one depends on efficiency and readability needs. Experiment with these techniques and integrate them into your projects for optimized data handling!
For Developers:
Looking to strengthen your Java expertise? Optimize your code for speed and scalability. Explore expert insights, hands-on tutorials, and career opportunities at Index.dev.
For Companies:
Need skilled Java developers who excel at writing efficient, scalable code? Index.dev connects you with pre-vetted Java experts who streamline data retrieval and boost application performance. Get top talent within 48 hours—risk-free for 30 days.
