Europe is the underdog in the AI race. The U.S. has OpenAI. China has DeepSeek. Both are burning billions to dominate global AI infrastructure.
Europe isn't trying to win that race. It's running a different one entirely. European large language models (LLMs) emphasize openness, multilingual mastery, privacy-conscious design, and enterprise readiness. They may not always lead in benchmarks, but they offer control, flexibility, and reliability that global corporations crave.
In this article, we take a hard look at Europe’s six most promising large language models. We’ll break down their capabilities, pricing, and real-world performance. You’ll see where they shine, where they lag, and why Europe’s AI ecosystem is carving out a distinctive, strategic niche in the global AI race.
Building AI products? Hire vetted AI engineers through Index.dev who understand multilingual models, data sovereignty, and enterprise deployment across EU infrastructure.
1. Mistral Large 3
- Developer: Mistral AI (France)
- The Numbers: 675B total parameters, 41B active | 256K token context
- Access: Commercial API + self-hosted
Mistral Large 3 is France’s bold move to claim a seat at the global AI table. Built by former DeepMind and Meta engineers, it’s designed for enterprises that want GPT-level reasoning without sending sensitive data to U.S. clouds.
Features
- Mixture-of-Experts at Scale: Mistral Large 3 activates only 41 billion of its 675 billion parameters per query. While GPT-4 burns through all its parameters for every request, Mistral selectively engages only the experts needed for each task.
- Native European Multilingualism: Most models learn English first, then awkwardly bolt on French, German, and Spanish. Mistral trained them all as equals from day one. The difference shows in nuance, idioms, regional context. Try asking GPT-4 about French tax law versus asking Mistral. You'll notice.
- Extended Context with Actual Recall: Mistral Large 3 maintains coherent reasoning across entire codebases, legal contracts, and research papers without the context degradation that plagues other long-context models.
Pricing
$3 per million input tokens, $9 output. GPT-4o charges $5 input. Claude 3.5 Sonnet runs similar rates. You're getting frontier performance at mid-tier pricing.
Performance
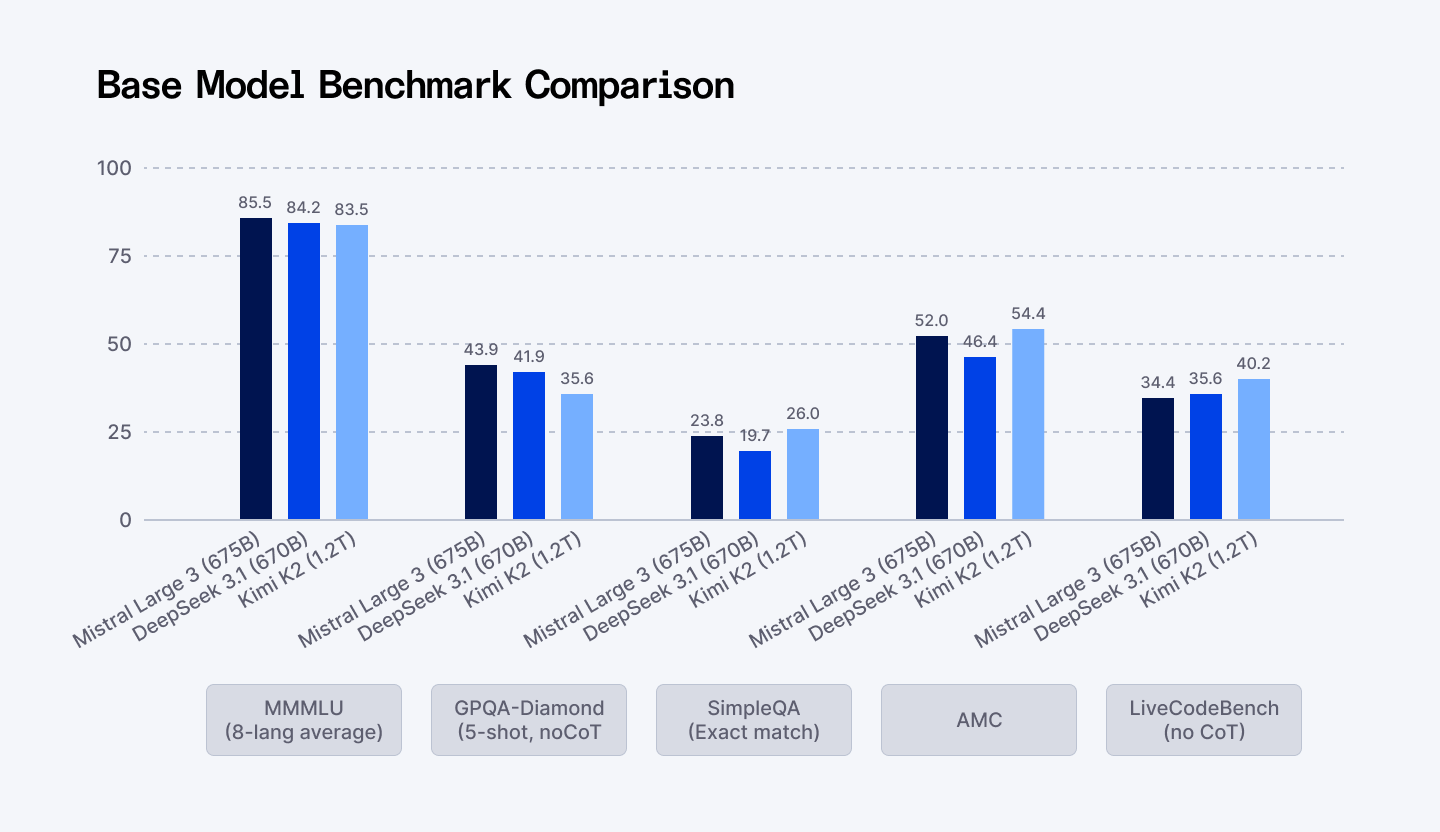
Here is how Mistral Large 3 stacks up against the elite competition:
| Benchmark | Metric | Mistral Large 3 (675B) | DeepSeek v3.1 (670B) | Qwen 3 (235B) |
| MMMLU (Multitask Knowledge) | 8-language Average | 85.5 | 84.2 | 83.7 |
| GPQA-Diamond (Expert Reasoning) | Complex, Multi-step Logic | 43.9 | 41.9 | 39.5 |
| AIME25 (Advanced Math) | Reasoning & Numerical Accuracy | 87.1 | 85.0 | 84.2 |
- Frontier-Level Reasoning: Mistral Large 3 sits comfortably in the global Top 5 by user preference. On GPQA-Diamond, the gold standard for complex reasoning, it scores 43.9 versus DeepSeek's 41.9 and Qwen's 39.5.
- Massive Context Capacity: 256K tokens means real context. You can drop entire codebases, legal contracts, or research papers into a single prompt and Mistral remembers what it read. No degradation. No hallucinating about page 47 when you ask about page 200.
- Coding Capabilities: While models specifically tuned for code (like Kimi-2 or DeepSeek-V3) may hold a slight edge on certain code benchmarks, Mistral Large 3 remains a powerful general-purpose coder. The smaller sibling, Ministral 14B, scored 85.0 on AIME25. That obliterates same-size competitors like Qwen 3 (73.7). You can now run serious reasoning locally, on-device, without cloud dependencies.
⭢ Compare ChatGPT vs Claude for coding to see which AI model delivers better results for developers.
2. Minerva AI
- Developer: Sapienza NLP, FAIR, CINECA (Italy)
- The Numbers: 350M to 7B parameters | 2.5 trillion training tokens
- Access: Fully open source (Apache 2.0)
Minerva proves that Europe can build sovereign AI without trying to outspend Silicon Valley or China. It’s Italy staking its claim in the global AI scene. Unlike English-first models adapted after the fact, Minerva was trained from scratch on Italian and English. Half a trillion words in Italian and English, fully documented, fully auditable.
Features
- Trained From Scratch on Italian: Every other Italian LLM starts with Llama or Mistral and bolts on Italian afterward. That means English-biased tokenizers, opaque training data, linguistic assumptions you can't audit. Minerva bypassed all of it. Over 500 billion words of documented Italian and English sources. You know exactly what went in.
- 50/50 Italian-English Balance: Most multilingual models are 90% English, 10% everything else. Minerva treats Italian and English as equals. The result? Italian queries don't inflate your token costs by 25%. Your inference runs faster. Your bills stay reasonable.
- Instruction-Tuned for Safety: Researchers can audit the training data. Regulators can verify compliance. Organizations understand model behavior instead of guessing. When you're deploying AI in healthcare, legal, or government contexts, that matters more than benchmark scores.
- Free App and Chatbot: The free chatbot and app mean you can test before you commit. Students can learn. Researchers can experiment. Everyone can participate.
Pricing
The flagship 7B model runs on a single GPU. The 350M variant runs on modest hardware. Both are yours to download and deploy wherever you want. No API costs. No licensing negotiations. No vendor lock-in.
For Italian businesses, this eliminates the adoption barrier. Small companies, regional governments, universities, startups can deploy serious Italian-language AI without budget approvals or procurement cycles.
Performance
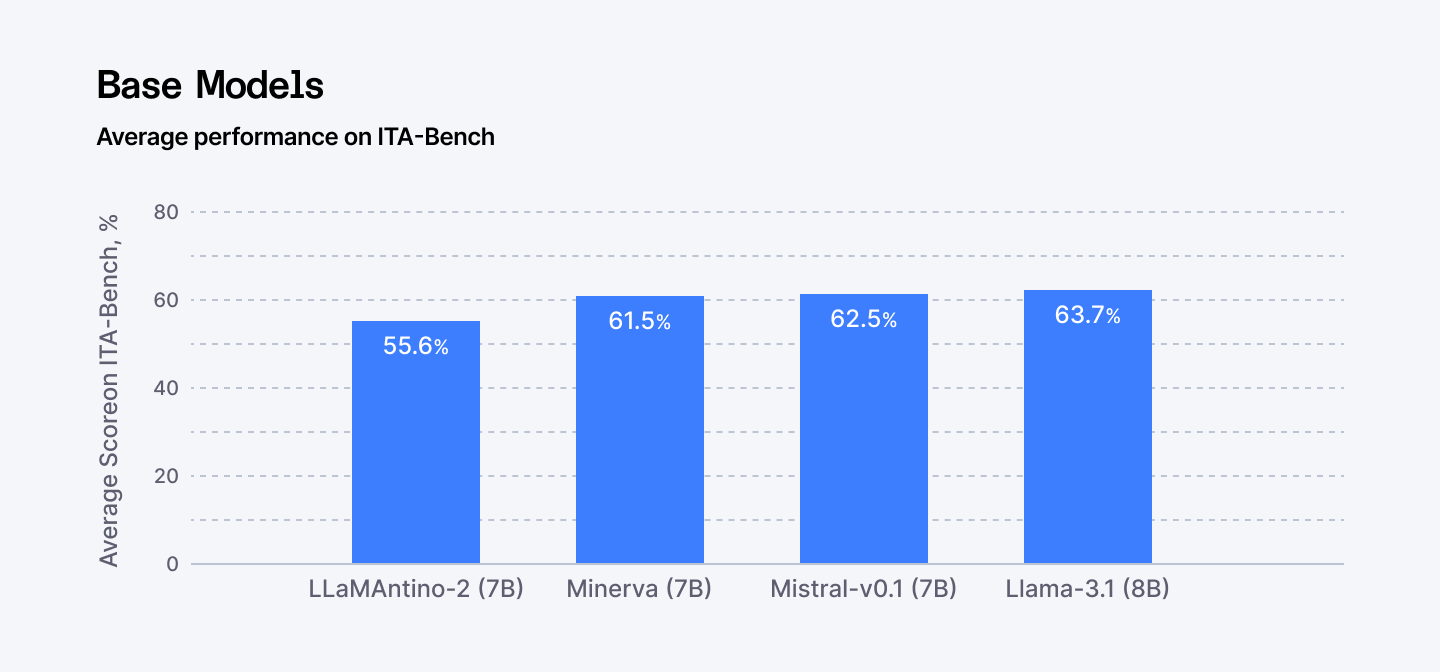
- Italian Benchmark Leadership: Minerva scores 82.4 on MMLU (broad knowledge), competitive with Llama 3.1's 83.1. On GSM8K (grade-school math reasoning), it hits 89.2, edging Mistral 7B's 88.5. For Italian-specific benchmarks like ITA-Bench and Evalita-LLM, it outperforms adapted models by meaningful margins.
- Efficiency Advantage: 25% token efficiency advantage on Italian text compared to English-centric models. Every Italian query processes faster and costs less because the tokenizer was designed for the language, not retrofitted.
- Architectural Alignment: The model is built on the high-performance Mistral architecture, ensuring that while its size is modest (7B parameters), its computational design is state-of-the-art for fast inference and handling complex sequences.
Model | Parameters | Training Tokens | Italian MMLU | English Capability |
| Minerva 7B | 7.4B | 2.5T | Strong | Native bilingual |
| Mistral 7B (adapted) | 7B | Unknown | Moderate | Native |
| Llama 3.1 8B | 8B | 15T+ | Weak | Native |
3. PhariaAI
- Developer: Aleph Alpha (Germany)
- The Numbers: 7-8B parameters | Tokenizer-free architecture
- Access: Commercial, on-premises deployment
Aleph Alpha looked at how every major LLM processes language and said no. GPT-4, Claude, Gemini—they all use tokenizers built on English-heavy data. Try to run them in Finnish, Arabic, or specialized domains and watch your costs explode by 5-6x. Aleph Alpha eliminated the tokenizer entirely.
Features
- The Architecture Breakthrough: Hierarchical Autoregressive Transformer (HAT) processes text at word and byte level. No tokenization. No English bias baked into the foundation. You can fine-tune on Hungarian medical records, Finnish engineering specs, or Arabic legal documents without computational penalties. For European organizations operating across multilingual markets, this changes the math. You're not paying 5-6x more because your data isn't in English. Every language costs the same to process.
- Explainability That Regulators Accept: AtMan technology makes reasoning transparent. You see which patterns influenced each output, which relationships the model accessed, where contradictions exist. This is table stakes in finance, healthcare, government—anywhere decisions carry legal consequences.
- Sovereignty by Design: Training happens on European supercomputers. Deployment runs on European infrastructure. Your data never crosses jurisdictions. Aleph Alpha partnered with AMD and Schwarz Digits to build a complete European AI stack.
Pricing
Aleph Alpha doesn't compete on price per token. They compete on total cost of ownership for enterprises that need custom models, regulatory compliance, and guaranteed data residency. When you factor in the cost of regulatory violations, data breaches, or vendor lock-in to U.S. cloud providers, Aleph Alpha's on-premises deployment model often pencils out cheaper.
Performance
- German Benchmark: On German zero-shot instruction tasks, Pharia 7B beats both Llama 3.1 8B and Mistral 7B. For engineering domain prompts in English and German, it outperforms Mistral while matching Llama with more concise outputs.
- Tokenizer Efficiency: Best in class for 4 out of 7 European languages. Fewer tokens for the same text means lower costs and faster processing.
- Length Control: When you need exactly 500 words, Pharia delivers exactly 500 words. Competitors overshoot or undershoot. That precision matters for structured documents and automated reports.
- Domain-Specific Strength: User preference scores show 3.10 for German instructions versus Llama's 3.08 and Mistral's 2.89. Not massive gaps, but Pharia wins where European enterprises operate.
Key performance comparison against similarly sized models:
Metric | Pharia 7B | Mistral 7B v0.3 | Llama 3.1 8B |
| German Instruction Tasks | Superior | Good | Good |
| Engineering Domain (EN/DE) | Superior | Moderate | Superior |
| Tokenizer Efficiency (EU langs) | Best in class | Standard | Standard |
| Length Control Accuracy | Highest | Moderate | Moderate |
| Safety (Unsafe Outputs) | Low | Low | Lowest |
4. Velvet AI
- Developer: Almawave (Italy)
- The Numbers: Up to 14B parameters | 128K token context
- Access: Open source (Apache 2.0)
Almawave built Velvet for a future where AI doesn't just read text. It processes images, voice, documents—everything flowing through European enterprises simultaneously. Not chasing parameter counts. Building what works in hospitals, banks, and government offices.
Features
- Built for Real Deployment Scenarios: It runs everywhere. Cloud, on-premises behind your firewall, edge devices in bank branches or hospital wings. The 14B model uses Grouped Query Attention for efficiency. The 2B variant runs on a single GPU. You deploy where your data security requirements demand, not where your vendor prefers.
- Multimodal and Multi-Input: Text, images, voice—Velvet handles them natively. Almawave's background in speech recognition and NLP shows. You can process customer service calls, analyze medical images alongside patient notes, review audio-visual evidence in legal cases.
- Industry Focus: Almawave has deep roots in healthcare, finance, and public administration. That experience shaped Velvet's training. You're not starting from a generic foundation and hoping fine-tuning works. The model already understands domain context, terminology, workflows.
Pricing
Apache 2.0 license. Zero licensing fees. Deploy commercially without negotiations.
- Low Infrastructure Footprint. The 2B variant runs efficiently on minimal hardware. Dramatically lower initial investment and ongoing costs for bringing AI in-house.
- Enterprise Backing. Open source with commercial stability. You get the freedom of Apache 2.0 plus the support structure startups and open source consortiums lack.
Performance
- Long-Context Mastery: Velvet-14B handles 128,000 tokens in one go, enough to process full legislative acts or complex legal dossiers, maintaining coherence across hundreds of pages.
- Multilingual Reasoning: 56.4 for EU languages, 58.6 for Italian. Strong on MMLU benchmarks for European languages, including Italian, making it effective for multinational teams and internal knowledge retrieval.
- Compute Efficiency Exceeding 90%: Efficiency-focused design and training on high-performance Italian supercomputers using 4D parallelization and quantization techniques reduces operational costs and carbon footprint.
5. EuroLLM 9B
- Developer: 9 institutions across 8 countries
- The Numbers: 9B parameters | 128K context | 4 trillion training tokens
- Access: Fully open source, no restrictions
This is what happens when Europe decides multilingual AI is a public good, not a profit center. A consortium spanning Portugal, Scotland, France, the Netherlands and beyond trained EuroLLM on all 24 official EU languages plus 11 more. Funded by European supercomputers. Released completely open. No licenses. No restrictions. No vendor lock-in.
Features
- Multilingual Parity: Most "multilingual" models are English first, everything else adapted. EuroLLM designed all languages as equals from scratch. The data mix ensures Greek doesn't get penalized versus English. The tokenizer handles all European writing systems efficiently. Evaluation happened across languages, not just translated English tests.
- European Context Baked In: Training corpus includes European literature, scientific papers, government documents, EU Parliament transcripts, cultural content U.S. and Chinese models never see. It understands European legal systems, historical context, and regional variations.
- Supercomputer Scaling: EuroLLM-9B was trained on the MareNostrum 5 supercomputer (EuroHPC). This access to cutting-edge public hardware allows the consortium to scale their models aggressively (with plans for a 22B model and multimodal variants) without reliance on external cloud providers.
Pricing
EuroLLM is fully open. Weights, data, and training pipelines are public. Companies can modify it, governments can audit it, and researchers can study it—all without licensing restrictions. Trained on Europe’s MareNostrum 5 supercomputer, it scales aggressively without reliance on foreign clouds. Zero API costs, zero vendor lock-in, full control over inference and deployment.
Performance
- Multilingual Benchmarks: Superior Borda count on MMLU-Pro and MUSR versus other European models. Matches or surpasses Gemma-2-9B in multilingual tasks.
- Translation Leadership: EuroLLM-9B-Instruct outperforms Gemma-2-9B-IT on WMT24++ translation tests (COMET metric). Best performance among European LLMs in machine translation.
- English Parity Maintained: Despite massive multilingual focus, matches Mistral-7B on English benchmarks like Hellaswag. Grouped Query Attention boosts inference speed. Strategic 128K token vocabulary reduces memory footprint versus Gemma-2's 256K while maintaining efficiency.
Head-to-head performance benchmarks prove its value:
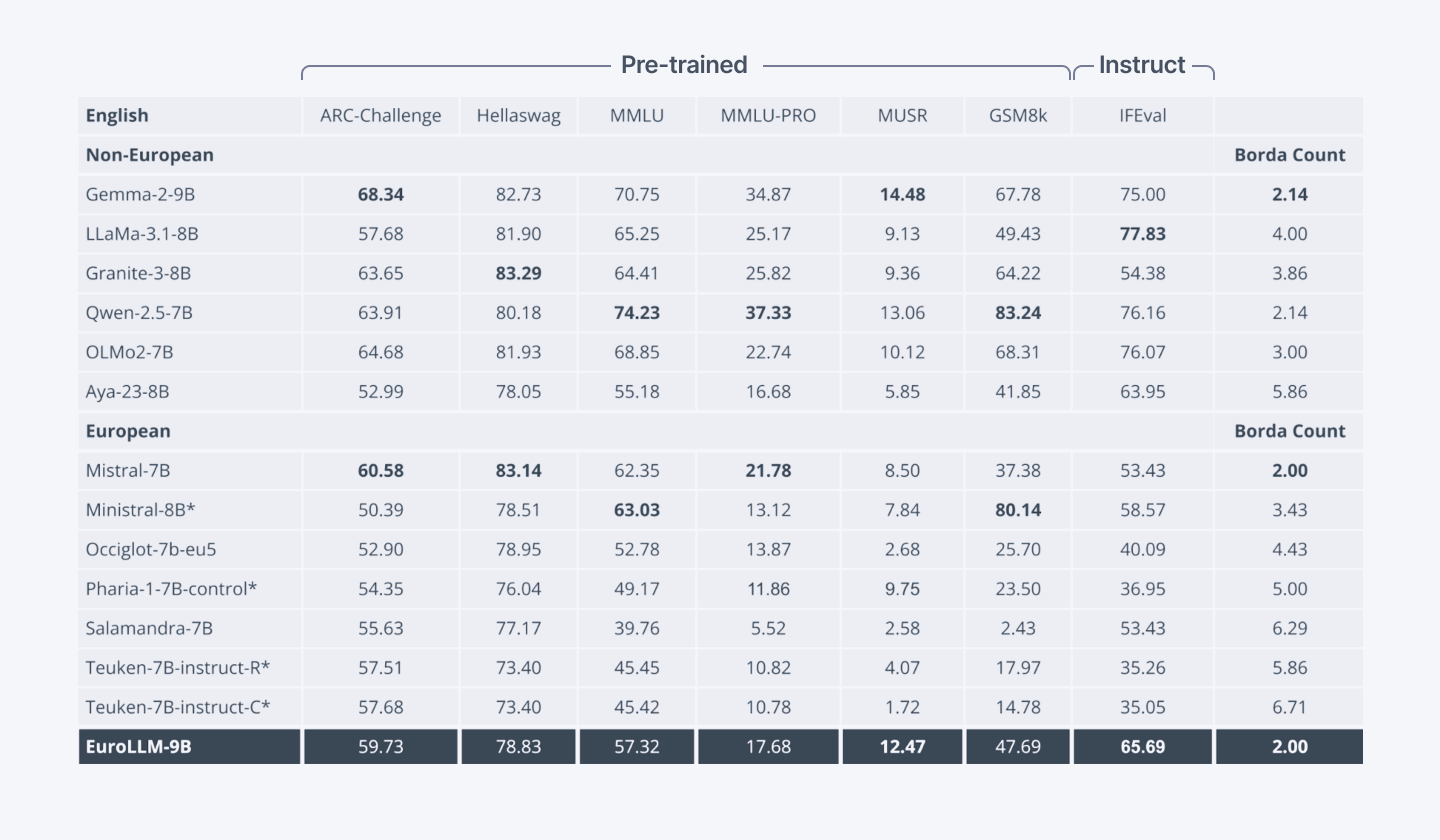
Comparison of open-weight LLMs on English general benchmarks. The results demonstrate EuroLLM's strong performance on English tasks, surpassing most European-developed models and matching the performance of Mistral-7B. (Source: Hugging Face)
6. BLOOM
- Developer: BigScience (1,000 researchers, Hugging Face)
- The Numbers: 176B parameters | 46 languages | 2,048 token context
- Access: Fully open source (Responsible AI License)
In 2022, BLOOM did something nobody thought possible: 1,000 researchers across the world built a 176 billion parameter model, documented everything, and released it publicly to prove open collaboration could work at frontier scale.
Features
- Complete Transparency: Every training checkpoint published. ROOTS corpus curated with documentation. Researchers can study exactly how it was built, not reverse-engineer from black boxes. That transparency enabled independent auditing for robustness, fairness, bias.
- Multilingual Coverage: 46 languages including 20 African languages. First model over 100B parameters trained for Spanish, French, Arabic, and dozens of others as primary languages.
- The Responsible AI License: BLOOM pioneered licensing that balances open access with ethical guardrails. Broad use permitted, harmful applications prohibited.
Pricing
Fully open-source and inexpensive to run, BLOOM allows organizations to deploy a 176B parameter model at a fraction of commercial API costs. Small businesses and research labs can access world-class capabilities without subscription fees.
Performance
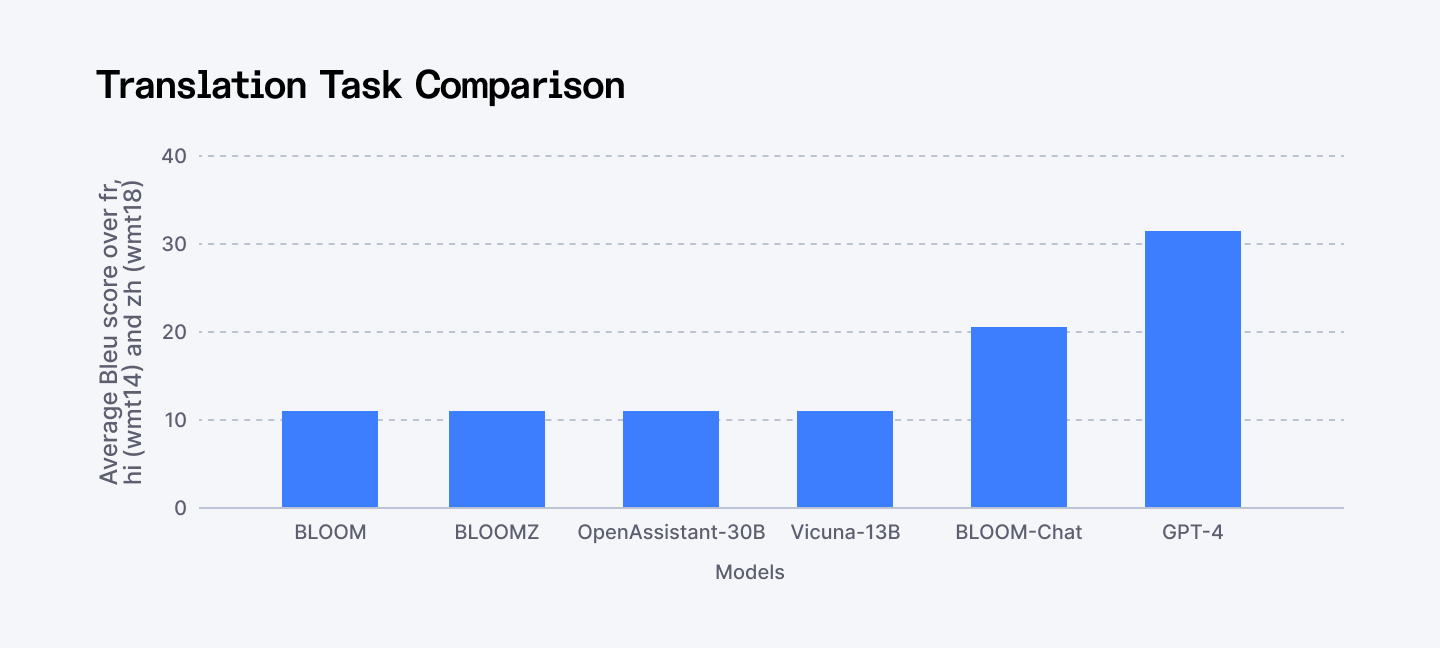
- Competitive Baseline: BigScience evaluations and lm-eval harness reports place BLOOM at 72.1 on MMLU for multitask understanding, trailing Llama 3.1 70B's 86.0 yet leading early multilingual peers like mT5-XXL at 68.4. 75% average accuracy on XGLUE translation across 46 languages, 78.3 on Hellaswag commonsense reasoning (competitive with OPT-175B).
- BloomZ (Instruction-Tuned Variant): The original BLOOM was a base model. Its fine-tuned version, BloomZ, clearly demonstrated what fine-tuning could achieve. Significant performance jumps across nearly all tasks. Showed the path forward for specialized derivatives.
- Low-Resource Language Strength: Where proprietary models falter—Estonian, Swahili, Yoruba—BLOOM maintains capability. For enterprises serving diverse markets, that breadth matters more than marginal benchmark improvements on English tasks.
⭢Explore whether DeepSeek can outperform ChatGPT as an AI model and where each one truly stands.
European Models and Strategic Benefits
This table maps the key European AI strengths (Sovereignty, Compliance, Multilinguality) directly to the best-fit model for your enterprise use case.
Business Benefit / Use Case | Best AI Model |
| Long-context enterprise applications & legal / code analysis | Mistral Large 3: Ideal for handling massive context windows (256k tokens), complex multi-step reasoning, and retrieval-augmented generation for contracts, research papers, or large codebases. |
| Italian-language applications & culturally aware NLP | Minerva AI: Pretrained from scratch on Italian-English data; perfect for chatbots, customer service, and apps requiring cultural nuance and bilingual fluency. |
| Data sovereignty & regulated industries | PhariaAI: Tokenizer-free architecture, on-prem deployment, and explainability (AtMan) ensures EU-compliant, secure AI for finance, healthcare, and government sectors. |
| Multimodal enterprise solutions (text, image, voice) | Velvet AI: Supports multimodal input, optimized for healthcare, finance, and public sector, with low hardware footprint and flexible deployment options. |
| EU-wide multilingual AI projects | EuroLLM 9B: Covers all 24 official EU languages plus additional languages, suitable for translation, multilingual customer support, research, and pan-European applications. |
| Ethical, open-access AI for low-resource languages | BLOOM: Open-source, transparent, and multilingual; ideal for organizations focusing on low-resource language support, academic research, or ethical AI initiatives. |
Where Europe Outperforms
Europe's LLM advantage isn't in raw compute or parameter counts. It's in areas Silicon Valley and Beijing consistently undervalue:
1. Multilingual AI
Most U.S. models treat non-English as a feature request. Chinese models optimize for Chinese. European models start from diversity. When your AI needs to perform equally well in Finnish, Portuguese, Greek, or Italian, Europe leads. Not through translation layers, but through models trained with linguistic parity.
2. Regulatory Compliance as Architecture
European LLMs are built to be auditable, explainable, and privacy-aware by default. What looks like slower progress at the research stage becomes a serious advantage at deployment, especially in healthcare, finance, government, and defense.
3. Open Collaboration
BLOOM proved 1,000 researchers across continents can build frontier models. EuroLLM showed nine institutions across eight countries can coordinate effectively. Minerva demonstrated open source can serve national language needs. It’s a different model. Slower, yes. But resilient, transparent, and aligned with democratic values.
4. Data Sovereignty Infrastructure
Europe is the only region that offers a true alternative to U.S. and Chinese cloud dominance. European organizations can train, deploy, and run AI entirely within EU jurisdiction, on European infrastructure, under European law. For many enterprises, that matters more than squeezing out a few extra points on English benchmarks.
5. Domain Specialization Over Generalization
While U.S. and Chinese labs chase artificial general intelligence, European AI focuses on solving specific problems. Healthcare diagnostics. Aerospace engineering. Public service automation. Industrial process optimization. The models are smaller. More specialized. Less impressive on general benchmarks. But more immediately useful in actual deployment.
⭢ Explore how the US, China, and Europe compete in building the best AI models and what sets them apart.
Where Europe Still Lags
Let’s be clear-eyed. Europe is doing many things right. But it’s not winning every fight.
1. Compute Access
Europe’s supercomputers are serious. But they're also outnumbered and outscaled by U.S. hyperscalers and Chinese government clusters. In the U.S., frontier models are trained with a credit card and a cloud contract. In China, they’re backed by the state. In Europe, you apply for grants. That slows iteration and limits experimentation.
2. Talent Still Drifts West
European universities produce exceptional AI researchers. The problem isn’t education. It’s retention.
Silicon Valley still offers compensation, scale, and speed that most European startups can’t match. China is closing that gap fast. Europe trains talent, then watches too much of it leave at the peak of its impact.
3. Capital Is Cautious
Yes, Mistral raised billions. That’s the exception, not the rule. Compared to OpenAI or state-backed Chinese labs, European AI funding remains conservative. VCs move slower. Government funding comes with friction. The exit market is thinner. That makes it harder to take big technical risks.
4. Benchmark Bias
When the entire industry measures success on English-language tests, multilingual European models look less impressive than they are. EuroLLM outperforms on European language tasks. That doesn't make headlines because those benchmarks don't trend on social media. The industry’s scoreboard is biased, and Europe pays the price for that bias.
5. Europe Undersells Itself
Silicon Valley excels at storytelling. Viral demos. Carefully orchestrated product launches. CEOs who understand media dynamics. Europe builds impressive technology and then... doesn't tell anyone. When's the last time you saw a European AI lab demo go viral? The work is strong. The storytelling is not.
How the EU Leads in Ethical AI
Europe is playing a long game. U.S. and Chinese models dominate headlines with raw power, but European LLMs are designed for inclusivity, transparency, and practical impact. They excel in multilingual communication, regulatory alignment, and local context sensitivity.
The EU may underperform in sheer scale, but it overperforms in accessibility, ethics, and cultural intelligence.
Wrapping Up
Europe’s AI ecosystem in 2025 is not flashy. It won’t deliver the next viral chatbot or dominate consumer headlines. And that’s the point.
What Europe is building is more durable: AI infrastructure it controls, understands, and can trust. Systems designed for multilingual societies, regulated industries, and long-term deployment. AI treated as critical infrastructure, not a growth hack.
For a region of 450 million people, that matters more than chasing hype cycles.
This isn’t about catching up to the U.S. or China. It’s about refusing to compete on terms that don’t fit Europe’s reality. When success is defined by English benchmarks, cloud dependency, and opaque models, Europe loses. When success is defined by sovereignty, compliance, and real-world usability, Europe wins.
➡︎ Building on European LLMs? You need developers who understand privacy-first AI. Index.dev connects you with pre-vetted engineers experienced in Mistral, open-source models, and EU data compliance. Scale your AI stack without vendor lock-in or sovereignty risks.
➡︎ Want to explore more real-world AI performance insights and tools? Dive into our expert reviews — from Kombai for frontend development and ChatGPT vs Claude comparison, to top Chinese LLMs, vibe coding tools, and AI tools that strengthen developer workflow like deep research, and code documentation. Stay ahead of what’s shaping developer productivity in 2026.
