You're overpaying for AI by a factor of ten. Not accidentally. Systemically. Your team built an AI feature, deployed GPT-4o to everything, and called it done. Now the bill hits $12,000/month for something that could run on $1,500. You didn't realize you could route simple queries to cheaper models. Nobody told you prompt caching cuts costs by 75%. By the time you find out, the damage is locked in.
This happens to every team. Once.
The second time, they optimize. They route. They cache. They measure. The bill drops to $2,100. Same output quality. Same user experience. 75% reduction. And suddenly the feature is defensible.
This is 2026. The economics of AI have inverted. For teams thinking beyond cost optimization alone, Agentic AI pricing strategy is becoming just as important to long-term monetization.
Frontier models aren't the default anymore. They're the exception. Smart teams dispatch queries to the cheapest model that can still solve the problem. The ones who don't? They lose. The economics of AI have inverted. For teams thinking beyond cost optimization alone, agentic AI pricing strategy is becoming just as important to long-term monetization.
Here's the playbook.
Looking to optimize AI costs fast? Hire vetted AI engineers on Index.dev in 48 hours—experts in routing, caching, DeepSeek for 75% savings.
At A Glance: The Cost-Cutting Toolkit
| Platform/Strategy | Best For | Estimated Savings | Difficulty |
| OpenRouter | Routing & Failover | 40-60% | Low |
| DeepSeek V3 | High-volume Tasks | 80-90% | Low |
| Anthropic Caching | Long Documents | 75-90% | Medium |
| OmniRouter | Dynamic Model Selection | 10-30% | Medium |
| Quantization | Self-hosted / On-device | 100% (Cloud Bill) | High |
| Helicone | Cost Observability | 15-20% | Low |
The Problem Everyone Has (And Ignores)
Look at this.
The LLM Cost Collapse: From $35/1M Tokens to $0.70 (2023-2025)
You're paying for compute you don't need. That's not an accusation. That's the default state.
Frontier models cost $20-35 per million tokens in 2023. They still cost roughly $18-20 in 2025. The compression was real but modest.
Then DeepSeek arrived in November 2024. $0.70 per million tokens for comparable performance. A 28x cost reduction in a single product launch.
That changed everything.
It's not just DeepSeek. Google Gemini Flash is $3.50. Llama inference via OpenRouter is under $2. Claude Haiku is $4.80. The frontier isn't moated anymore. It's fractured.
Teams that haven't adapted to this are bleeding. Teams that have are printing money.
The Actual Breakdown: Before vs After
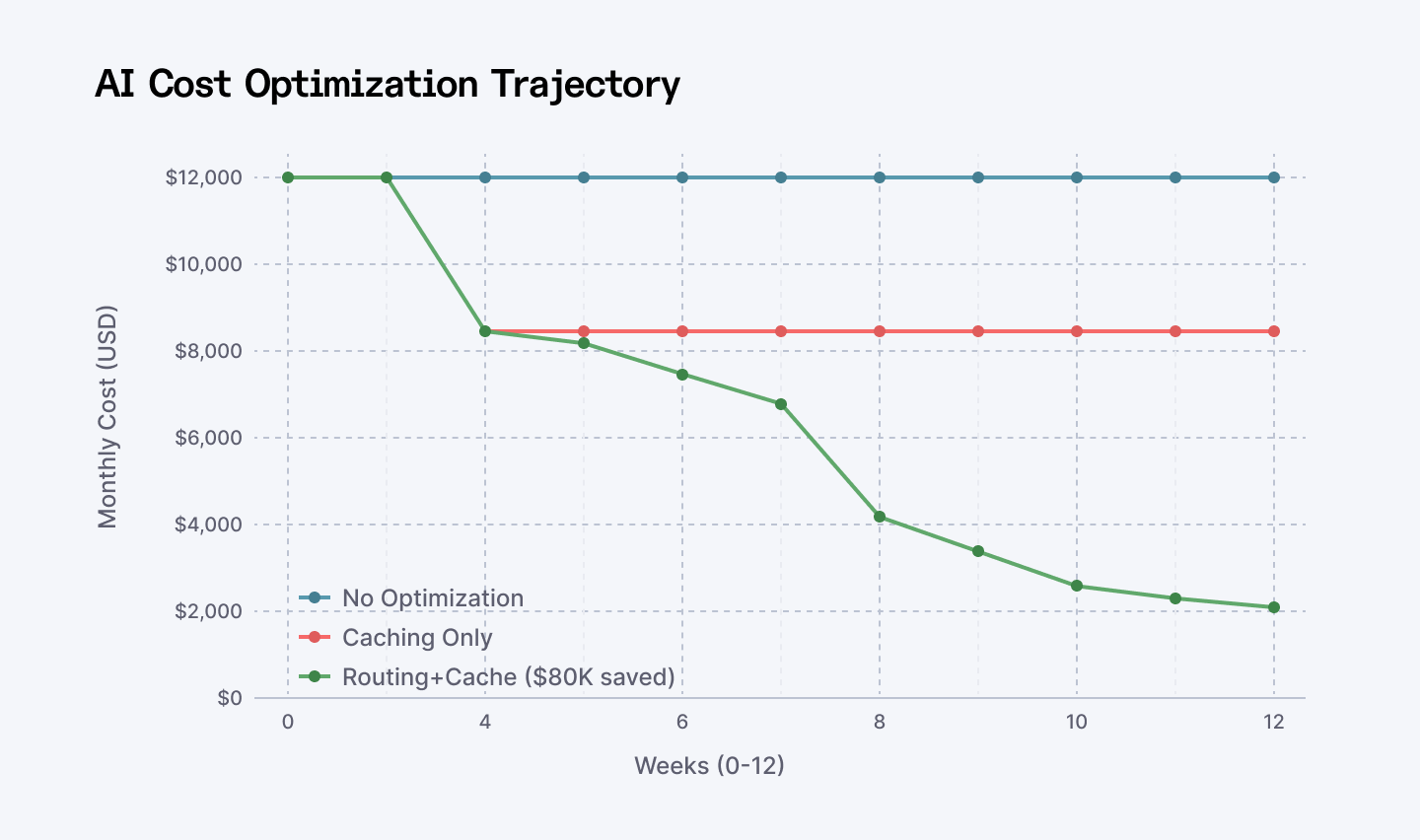
One development team ran customer support automation on GPT-4o. 150,000 queries per month. Average 500 tokens input, 300 tokens output.
Cost? $12,400/month.
The problem was stupidly obvious once they measured it. 70% of their queries were classification tasks. "Is this urgent?" "Which department?" "Does this mention billing?" GPT-4o was like using a fighter jet for grocery delivery.
They switched to smart routing. Gemini Flash for classification. DeepSeek for content summarization. GPT-4o only for edge cases that actually needed reasoning.
New bill? $2,100/month.
Same accuracy. Same response time. Three-quarters less cost.
But here's the thing nobody talks about: they also got faster response times. Cheaper models route faster. Cache hits are instant. The "optimization" accidentally improved the user experience. Cost reduction and performance gain. That's the real story.
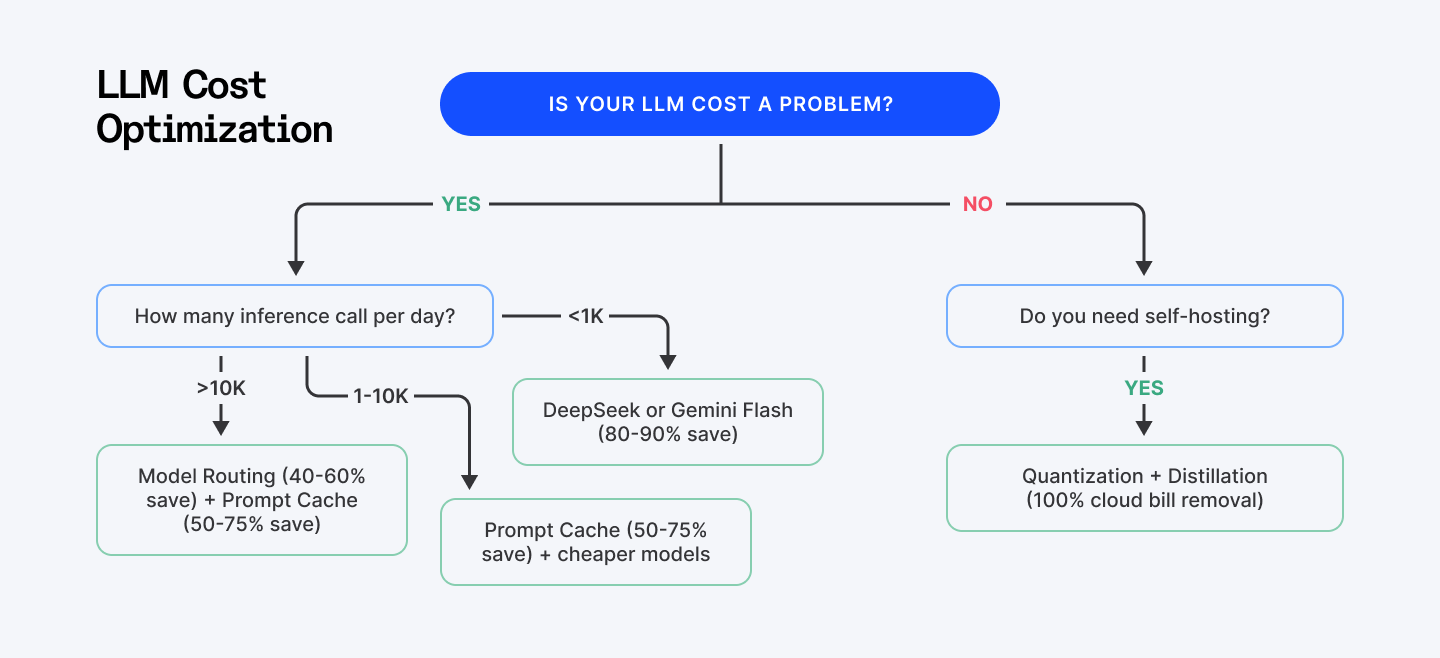
Pick Your Path: The Decision Tree
You can't implement everything at once. You shouldn't. Different teams have different constraints.
AI Cost Optimization Decision Tree: Pick Your Path
Use this: if you run 10,000+ inferences per day, start with routing + caching. If you're under 1,000 inferences per day, just switch to DeepSeek and call it done. If you have a machine learning engineer and stable workloads, invest in quantization.
Most teams live in the "1,000-10,000" band. For you: prompt caching is the immediate win. Caching tokens cost 90% less on Anthropic, 50% less on OpenAI. Restructure your prompts (static content first, dynamic input last), enable caching, measure your hit rate. You'll see cost reduction within two weeks.
The platforms and strategies below serve as an eye-opener. They're not about shipping worse AI. They're about shipping the same AI for less.
Want to see AI in action across software development? Explore the top 11 generative AI use cases.
1. Model Routing: The Simplest Win Nobody's Using
Model routing is the foundation. Everything else builds on top of it.
The concept is laughably simple. Don't route all queries to your most expensive model. Route to the cheapest model that can handle the task.
Classification? Send to Gemini 2.5 Flash. Summarization? DeepSeek. Complex reasoning? Claude Opus. Let the system decide.
Real numbers: OmniRouter achieved a 10.15% cost reduction while maintaining accuracy. MESS+, an algorithm that learns routing patterns over time, achieved 2x cost savings.
One developer's setup:
- 60% of traffic to DeepSeek V3 ($0.70 per 1M tokens)
- 30% to Gemini Flash ($3.50 per 1M tokens)
- 10% to Claude Haiku ($4.80 per 1M tokens)
Monthly bill: $2,100 instead of $8,500.
The implementation is not trivial—you need a routing layer that predicts task difficulty and selects the right model. But OpenRouter handles this natively. Route through their API. They route to the cheapest provider. You don't write a line of routing code.
Start here. This is the 40-60% win. Everything else is optimization on top.
Compare Remix vs Next.js vs Astro side-by-side for frontend tech selection with clear insights on Index.dev.
2. Prompt Caching: The 50-75% Cost Reduction That Works
Prompt caching is the hidden nuclear option that most teams ignore.
When you send a request with static context (system prompt, documentation, code snippets, long documents), the first request processes all of it. Subsequent requests with the same context? OpenAI routes to cached servers. Cached tokens cost 50% less. Anthropic goes further: 90% less.
A PDF analysis tool processed the same 50 documents repeatedly. Without caching, every query reprocessed those 50 PDFs (roughly 200K tokens). Cost per query: $3. With caching? $0.15. Same output. 95% cost reduction.
One team ran this experiment in production:
- 1,000 daily queries
- 200K token document corpus
- Without caching: $3,000/month
- With caching: $750/month
75% reduction.
The catch: you need to restructure prompts. Put your boilerplate at the top (system instructions, documentation, static examples). Put user input at the bottom. This maximizes cache hits.
Semantic caching is the next level. New query? Check if something similar exists in cache. If yes, retrieve it. Hit rates between 61.6% and 68.8% depending on query patterns. Practical result: API calls reduced by 68.8%.
Deploy this week. It's literally a prompt restructure and an API flag. Done.
Pro Tip: Implementation isn't just "flipping a switch." You need to restructure your prompts. Put static content (system instructions, docs) at the start. Put dynamic user input at the end.
3. DeepSeek V3: The Economics-Shifting Outsider Nobody Expected
DeepSeek arrived in November 2024 and broke the market. Look at this chart. This is why everyone is talking about it.
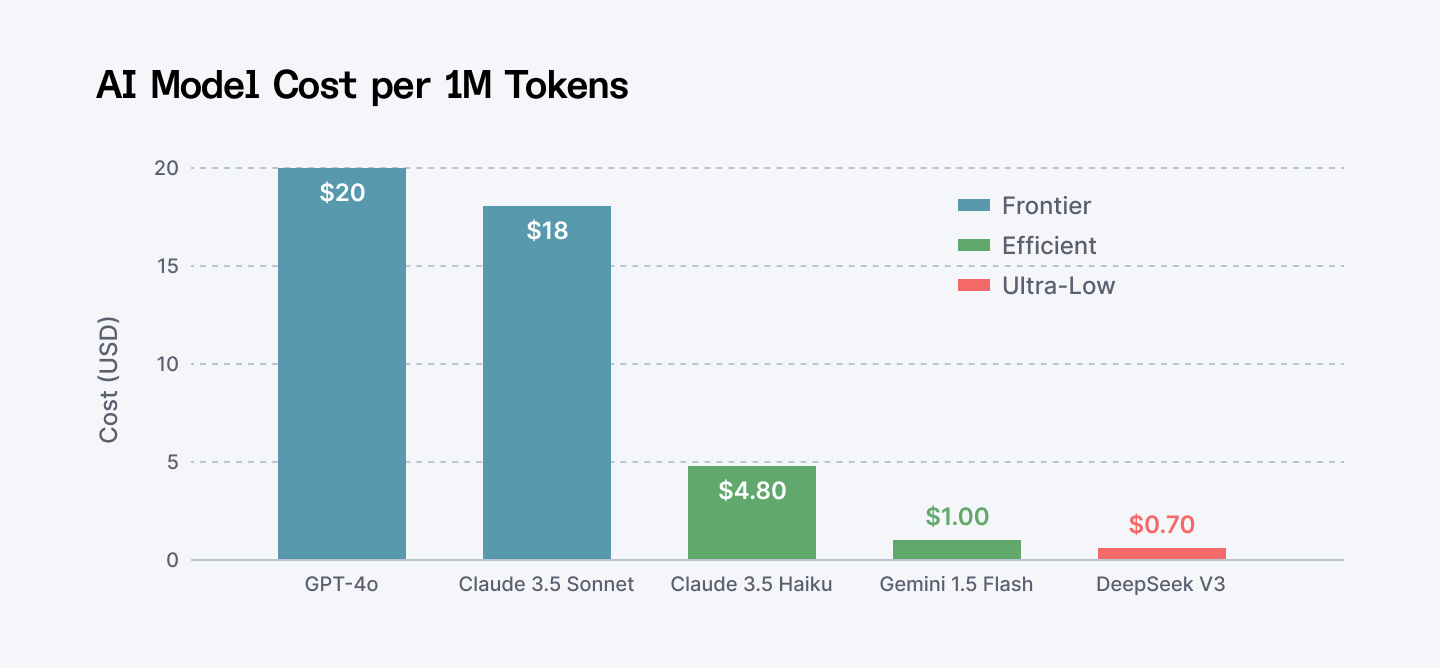
Cost Comparison of Top AI Models (Per 1 Million Tokens)
$0.28 for input. $0.42 for output. Per million tokens. GPT-4o is $20. Claude is $18. Do the math.
One developer cut costs from $10 per million tokens to $0.70 by shifting non-reasoning tasks to DeepSeek. Same accuracy verified by users. 88% cost reduction.
The context window is 128K tokens. That's roughly 100,000 words of document context. Massive.
The caveat: Chinese-owned. Data residency concerns exist in some regulated industries. Healthcare? Finance? Government contracts? Check your compliance regs first. Startup building B2B SaaS? No problem.
Google Gemini 2.5 Flash is the compliant alternative. $0.15 input + $0.60 output. Still dramatically cheaper than GPT-4o. Solid for 80% of tasks.
Deploy via DeepSeek API directly or through OpenRouter.
Dive into our DeepSeek vs. ChatGPT comparison to find out which model delivers smarter results for your projects.
4. Anthropic Claude with Prompt Caching
Claude’s pricing sits between OpenAI and DeepSeek. Claude's base pricing ($3/$15 for Sonnet, $0.80/$4 for Haiku) sits between OpenAI and DeepSeek.
But its architecture is different.
Prompt caching with 90% cost reduction.
For long-document workloads, this is the winner. Contract analysis. Medical record processing. Legal brief review. Load the 200K context window once. Cache it. Repeat queries cost pennies.
One enterprise processed 50,000 documents/month on Claude with caching. Cost: $8,000/month. Without caching? $45,000. Five-fold reduction.
Use Claude when: complex reasoning, ethical nuance, long documents, or when caching ROI justifies the base price.
Deploy via Anthropic API.
5. Quantization, Pruning and Model Distillation: The Self-Hosted Path
For teams comfortable running their own models, on-device optimization erases cloud API costs entirely.
Quantization compresses model weights from 32-bit to 8-bit. Result: 75% memory reduction with negligible accuracy loss. An 8B model suddenly fits on a single consumer GPU. Suddenly affordable.
Pruning removes redundant neurons. Think of it as trimming dead branches from a tree. You get 20-50% parameter reduction while retaining 95%+ of original accuracy.
Distillation trains a smaller model to mimic a larger one. One developer collected 50,000 rows of GPT-4 logs. Fine-tuned a 7B model. Result: 88% cost reduction. Users didn't notice the difference. Quality metrics were identical.
The catch: This is heavy engineering. You need PyTorch, Hugging Face, and ML expertise. Infrastructure. Time. Payoff hits fast for high-volume workloads (1,000+ inferences/day). For low-traffic apps? Skip it.
But if you're running 100,000 inferences per day? Distillation pays for itself within 60 days.
Tools to get started: PyTorch pruning module, SparseML, Hugging Face Optimum.
For serious teams: budget 2-3 months. Hire a senior ML engineer or contract it out. ROI materializes within months if you're at scale.
Don't have a Machine Learning Engineer who can handle quantization? Read our guide on how to vet software developers before you hire.
6. OpenRouter: API Aggregation and Failover Without Lock-in
OpenRouter is a proxy layer routing API calls to 150+ LLM providers—OpenAI, Anthropic, Google, DeepSeek, Llama via vLLM, Mistral, and a dozen others.
Why does this matter? You're not locked into one vendor. One provider goes down? Failover to another. One model underperforms? Test another without rewriting code. DeepSeek gets too expensive? Shift to Gemini in the config.
One developer's setup: route 60% to DeepSeek, 30% to Gemini, 10% to Claude—all through a single API endpoint. Costs vary? Dashboard shows it immediately. Provider quota exceeded? Automatic failover.
Semantic caching across all providers. Structured outputs. Native support for open-source models via vLLM. Real-time cost dashboards.
This is your abstraction layer. Vendor lock-in dies here.
Deploy via OpenRouter API.
7. FinOps Tools and Cost Observability
You can't optimize what you don't measure.
Helicone breaks down cost by model, by user, by feature. Real-time alerts. Anomaly detection. A teammate spins up an expensive experiment? Alert fires instantly, before the damage hits the credit card.
LangSmith (from LangChain team) tracks prompt performance over time. Flags regressions. Ties cost to quality metrics. Run the same prompt across multiple models, see which delivers best accuracy per dollar. Repeat.
FinOps frameworks from cloud providers apply to LLM workloads. Automated budget enforcement. Rightsizing recommendations based on historical usage. AWS Cost Explorer, GCP Cost Management, Azure Cost Management all support this.
The ROI is subtle but real. Teams using robust observability catch cost creep weeks before it spirals.
Deploy one of these immediately. Don't wait. Every week without observability is money you're not tracking.
Deploy via Helicone, LangSmith, or native observability middleware.
The Implementation Gauntlet: Week By Week
Week 1: Audit
Measure your current spend. Which models? How often? OpenRouter's dashboard shows this in two clicks. Benchmark this. You'll need it to measure progress.
Week 2: Enable Caching
If using OpenAI or Anthropic: restructure prompts. Static content first. Dynamic input last. Enable prompt caching. Measure cache hit rate.
Week 3: Implement Routing
Route simple tasks to cheaper models. Use OpenRouter or build a lightweight routing layer. Test the change on 10% of traffic first. Measure quality metrics.
Week 4: Deploy Observability
Set up Helicone or LangSmith. Real-time cost dashboards. Anomaly alerts. Lock in the savings. By week 5, you'll have concrete data: before vs. after cost, quality metrics unchanged, and a path forward.
The Uncomfortable Truth
Every month your team doesn't implement this, you're burning cash. Literally burning it.
The developer team that waits three months to optimize? They're out $9,000 in the quarter. The team that implements week 2? $2,100 in the quarter. That's $7,000 difference. For one small team.
Scale that across an organization with 10 AI features. That's $70,000 per quarter. $280,000 per year. On money that's just gone.
You can't compete with teams who've cracked this. They've got better margins. They can undercut you. They can experiment more because they're not bleeding on infrastructure.
The teams winning in 2025 aren't winning because they have better AI models. They're winning because they're ruthless about cost.
Curious how AI can speed up your hiring process? Check out our guide on 5 ways AI cuts time-to-hire.
Who Wins Here?
The companies shipping AI profitably are the ones who did all of this by now. Routing to cheaper models. Caching aggressively. Measuring obsessively.
The companies still using GPT-4o for everything? They're dead. They just don't know it yet. The inflection point isn't coming. It's here. Right now.
If your team can route queries intelligently, implement semantic caching, and pick the right model for the task—you're competitive. If you can't, you're bleeding.
Here's What Comes Next
You've got the playbook. Pick two platforms that match your constraints. Implement week 1. Measure week 4.
But here's where most teams get stuck: the engineering execution. Routing logic. Caching architecture. Distillation pipelines. That's not trivial.
You need engineers who've actually built this in production. Not just "AI enthusiasts." Builders who understand cost-efficient architecture. Who've debugged DeepSeek integration. Who've seen semantic caching fail and fixed it.
Those engineers are rare. Really rare.
Index.dev's network includes the top 5% of developers who specialize in this. Cost-conscious infrastructure. AI architecture. Production mindset.
You can find them through job boards and waste three months interviewing. Or you can hire a vetted AI infrastructure engineer on Index.dev in 48 hours.
97% placement success. Engineers stay 3x longer than in-house hires. Actually understand cost optimization.
➡︎ Need AI engineers who can ship? Index.dev connects you with production-ready AI specialists from LATAM and CEE in 48 hours—senior talent at half the Silicon Valley cost, with 95% retention and zero time zone headaches.
➡︎ Want to take your AI and software cost optimization skills even further? Explore practical strategies and real-world insights from our expert guides: learn 5 smart ways to reduce development costs, discover the top 5 AI tools for cloud infrastructure cost optimization, and uncover 5 cost optimization strategies for fintech infrastructure. Dive into detailed advice on AI application development cost estimation and optimization, explore code optimization strategies for faster software, and avoid common pitfalls with 10 vendor selection mistakes to avoid when choosing your AI recruiting partner. Browse these resources to sharpen your approach, save money, and make smarter AI and software investments.
